AWS Certified Solutions Architect Professional
Course Introduction
About Me

DevOps@RajeshKumar.XYZ


AWS Certification Tracks

Prerequisites

Additional Prerequisites
- Assumed AWS knowledge
- An understanding of cloud computing
- Microsoft / Linux essentials
- Networking essentials
- Working knowledge of virtualization
- Storage fundamentals
Scenario-based
Training
AWS
Strategies
Billing
Strategies
Security
Strategies
Deployment
Services
Analytics
Services
Strategy for Success!
Exam Highlights

2500
Certified
AWS Certified Solutions Architect - Professional
Exam Guide:
https://aws.amazon.com/certification/certified-solutions-architect-professional/
Summary
- Course at a glance
- AWS certifications
- Prerequisites
- Strategy for success
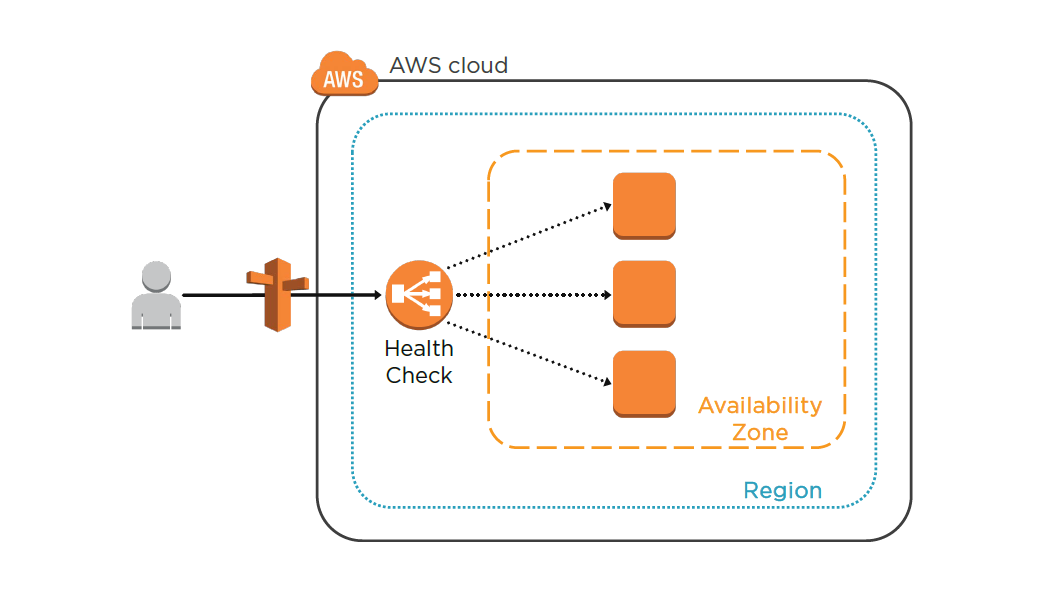
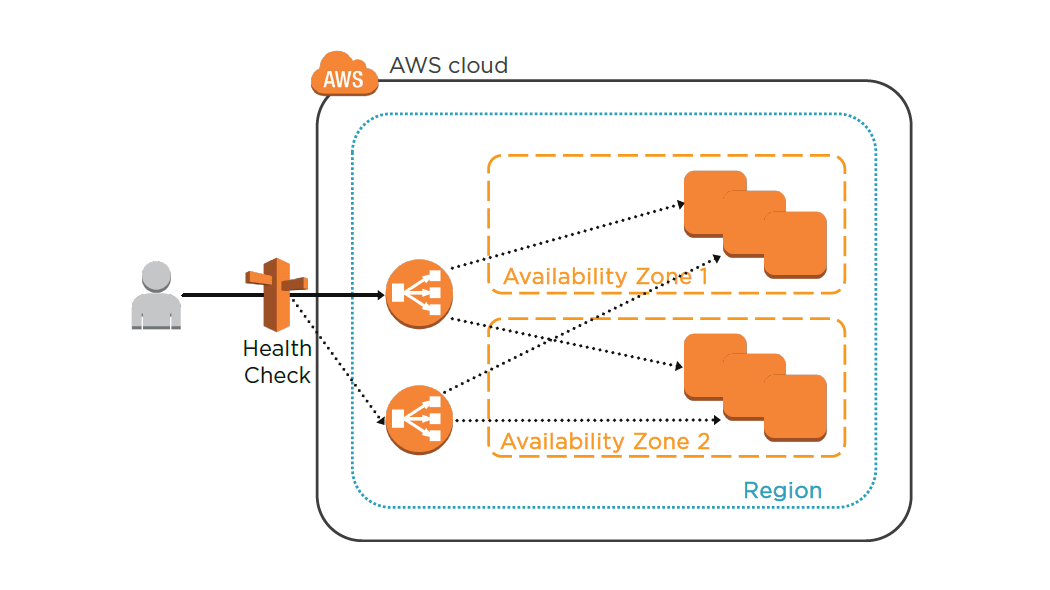
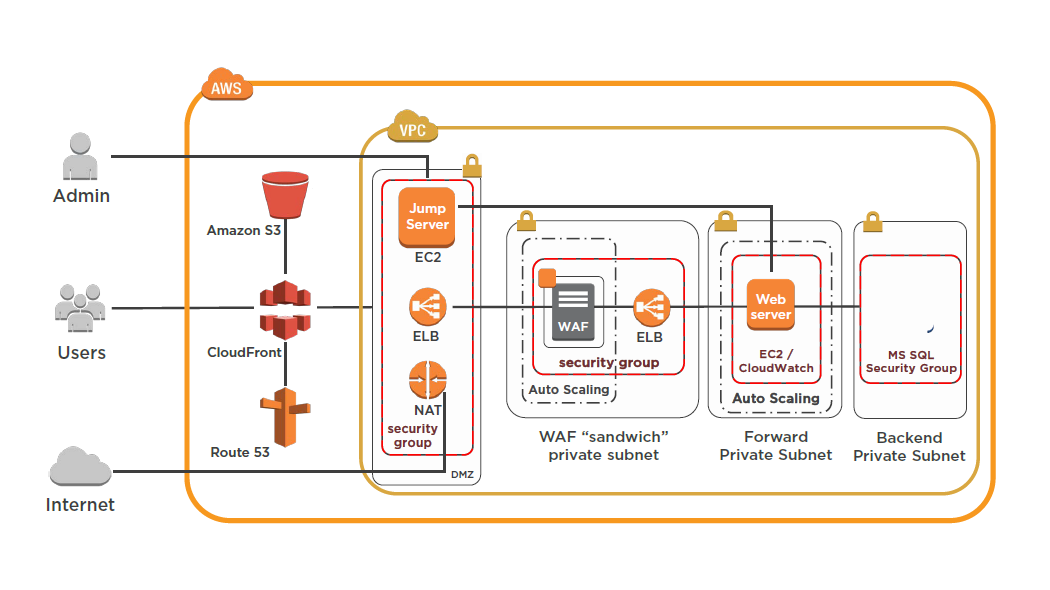
Designing AWS Networking Services: Elastic Load BalancerM
ELB Characteristics
- Region wide load balancer
- Can be used internally or externally
- SSL termination and processing
- Cookie-based sticky session
- Integrates with Auto Scaling
- ELB EC2 health checks / Amazon CloudWatch
- Integrates with Route 53
- Supported ports:
- 25 (SMTP)
- 80/443 (HTTP/HTTPS)
- 1024-65535
- Does not support EIP
- Supports domain Zone Apex
- Supports IPv4 and IPv6 (VPC does not support IPv6 at this time)
- Integrates with CloudTrail for log security analysis
- Multiple SSL certificates require multiple ELBs
- Wildcard certificates are supported
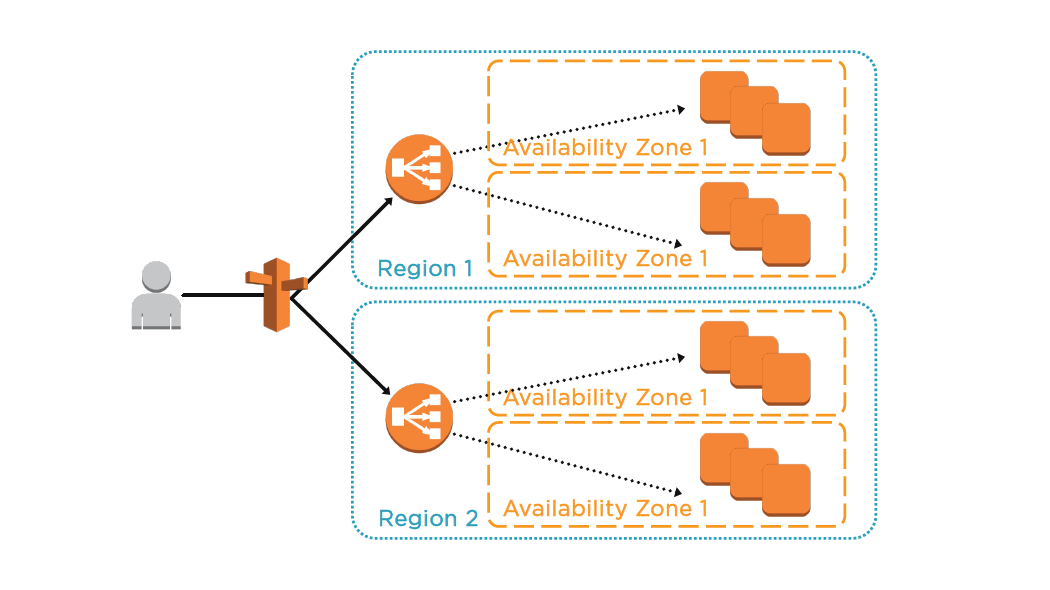
Summary
- ELB Characteristics
- ELB Scenarios
Designing AWS Networking Services: VPC and Direct Connect
Virtual Private Cloud Overview
- Logically isolated network in the AWS cloud
- Control of network architecture
- Enhanced security
- Internetwork with other organizations
- Elastic IP Address (public IPs)
- Enable hybrid cloud (site-to-site VPN)
- Single tenant dedicated server hardware
- VPC cost = $0 / VPN cost is $0.05/hr
VPC Peering
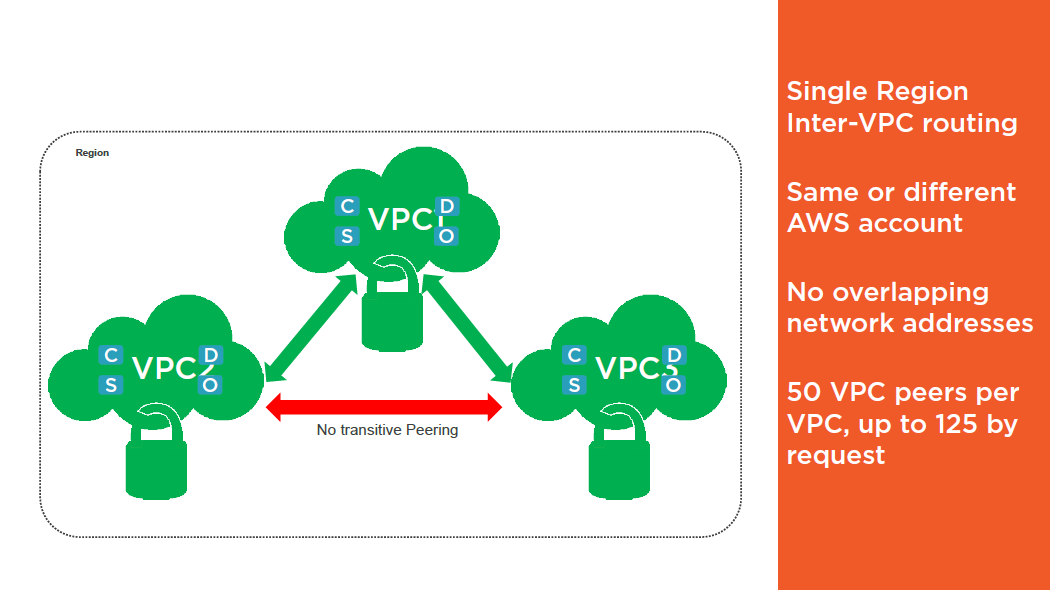
- Private DNS entries cannot be resolved between VPC peers
- Update the inbound or outbound rules for your VPC security groups to reference security groups in the peered VPC
AWS VPC Access
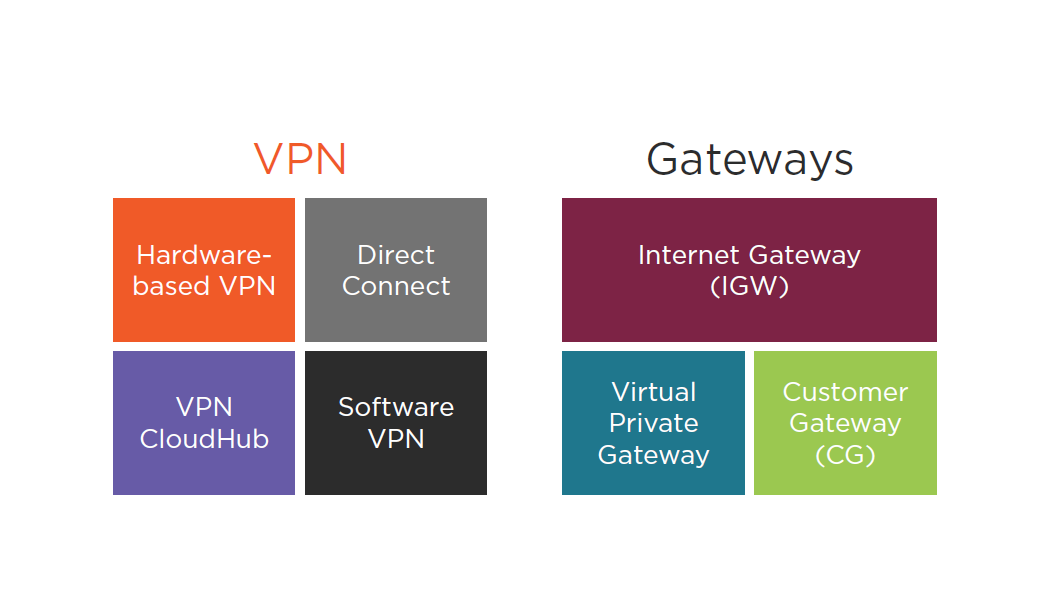
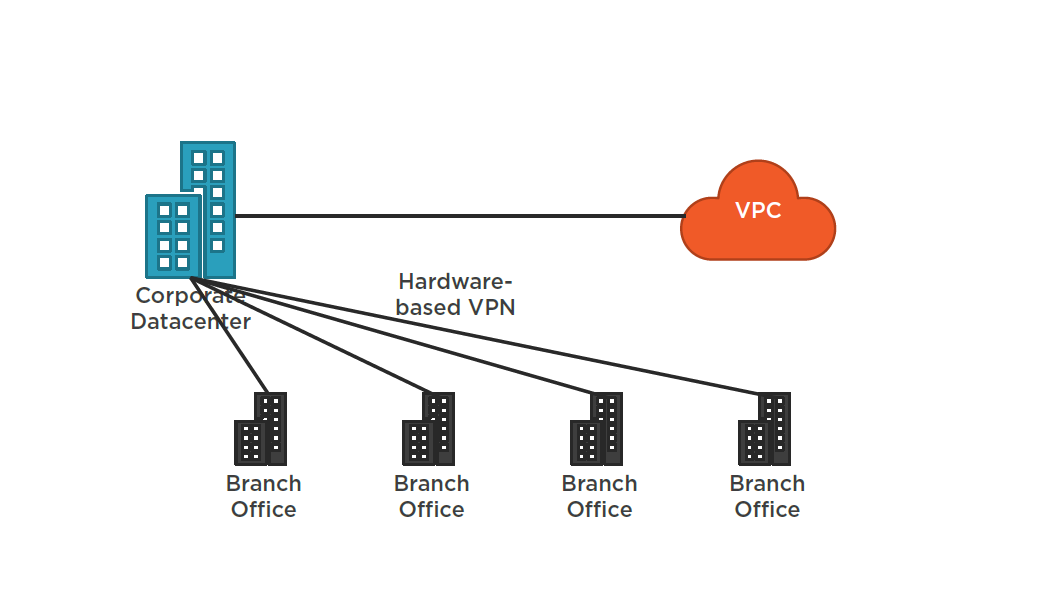
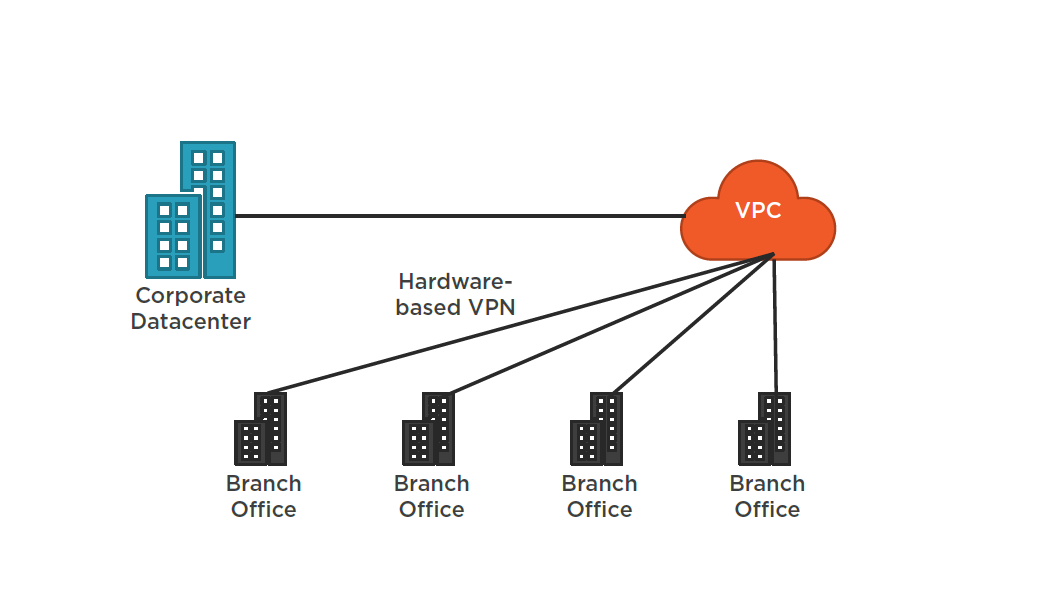
VPN Types
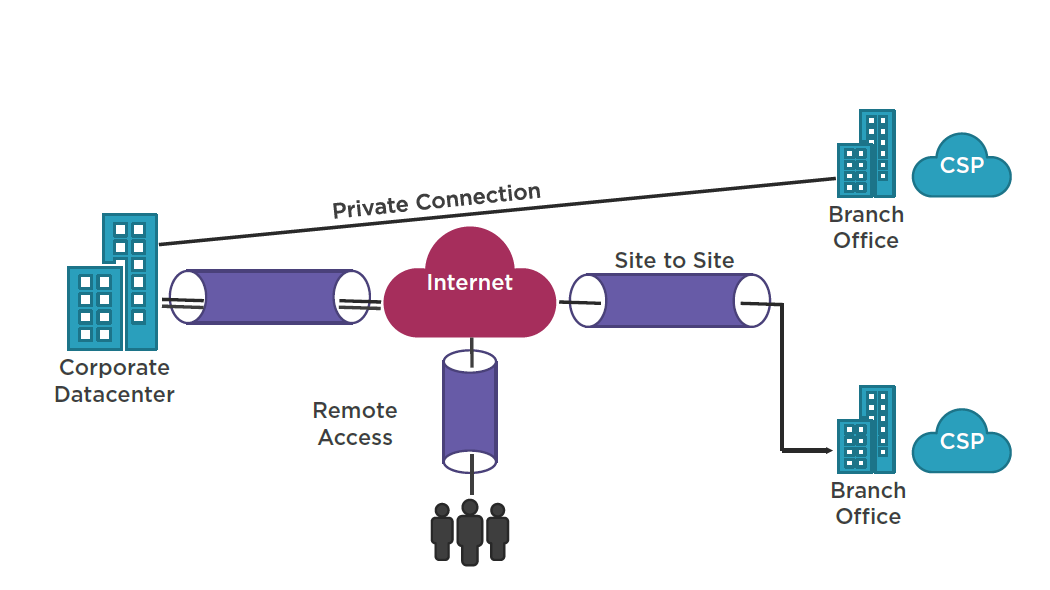
AWS VPC Access
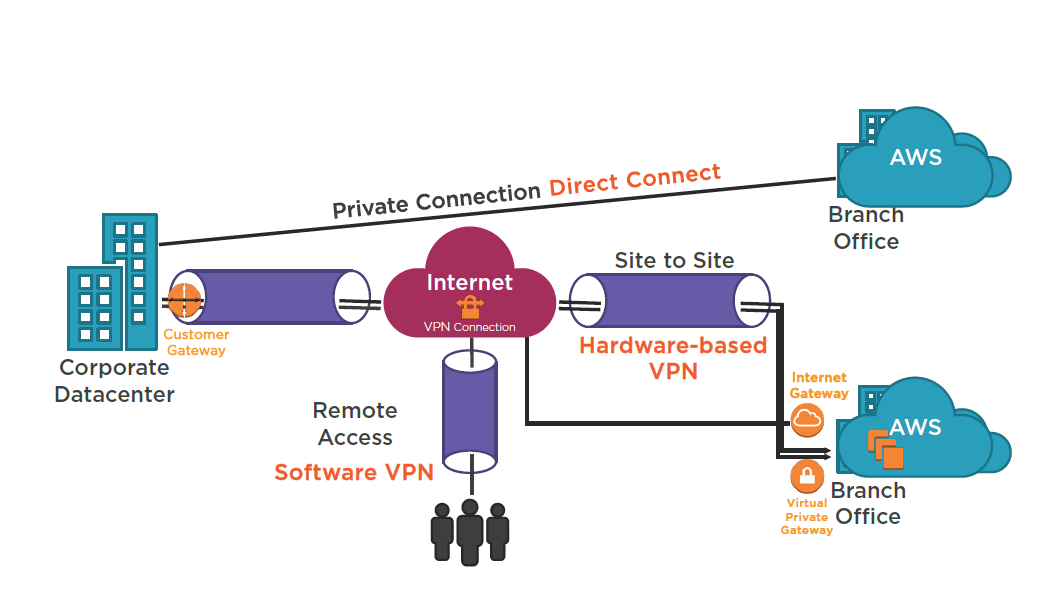
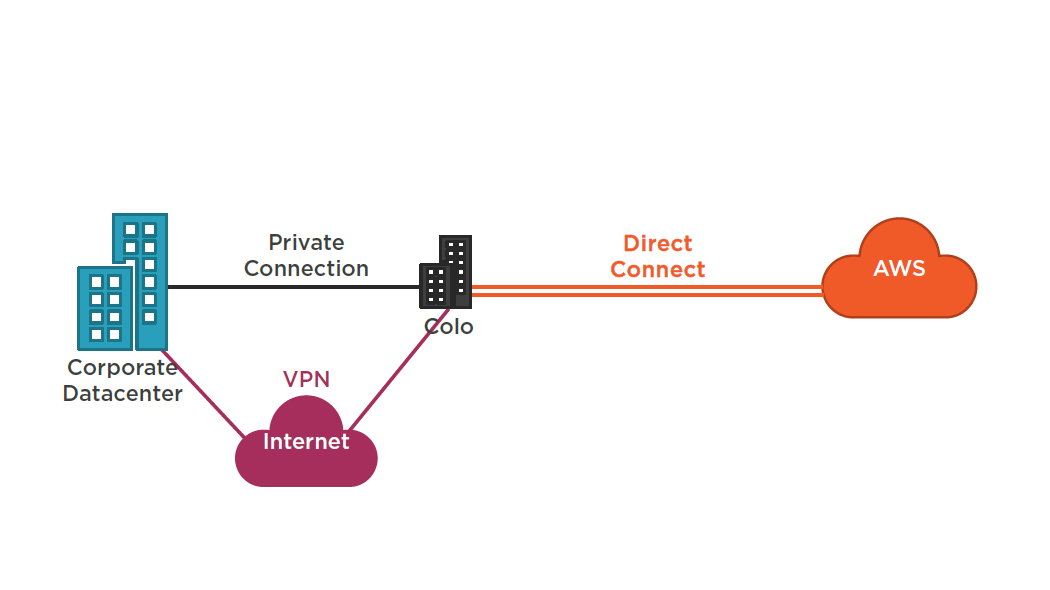
AWS Direct Connect
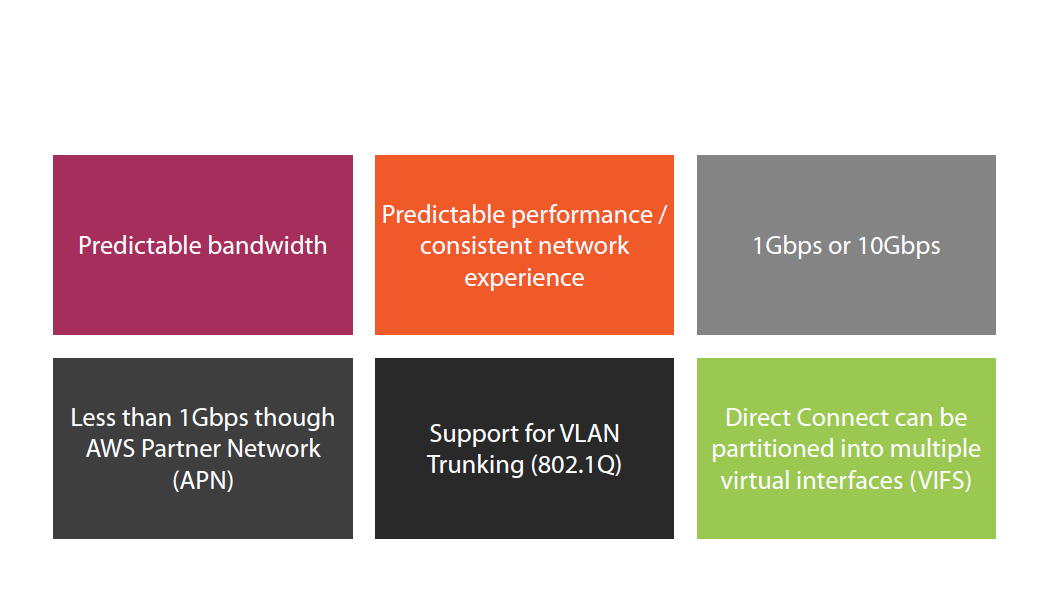

Virtual Interfaces
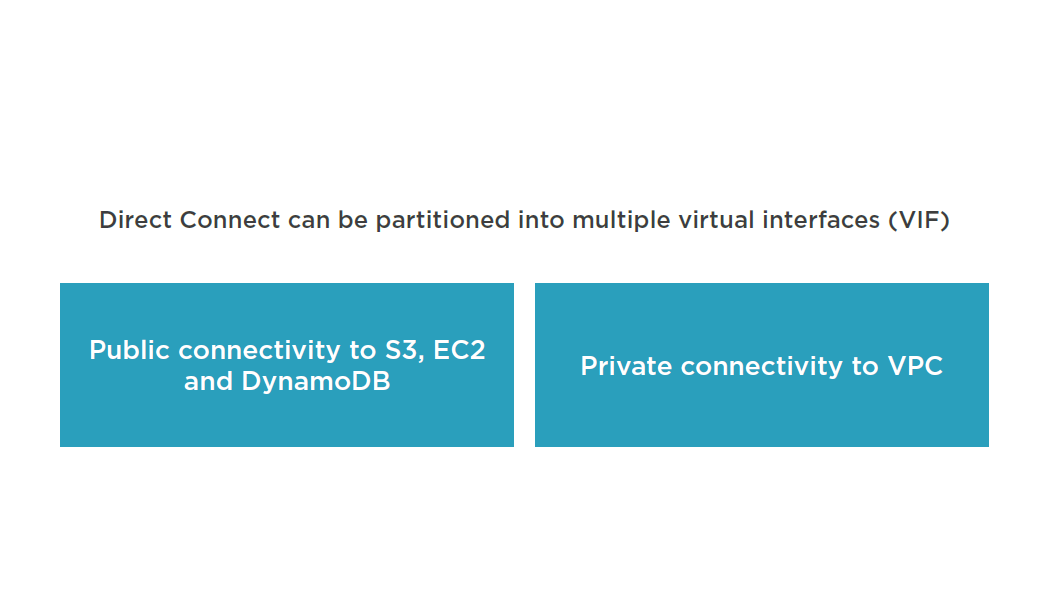
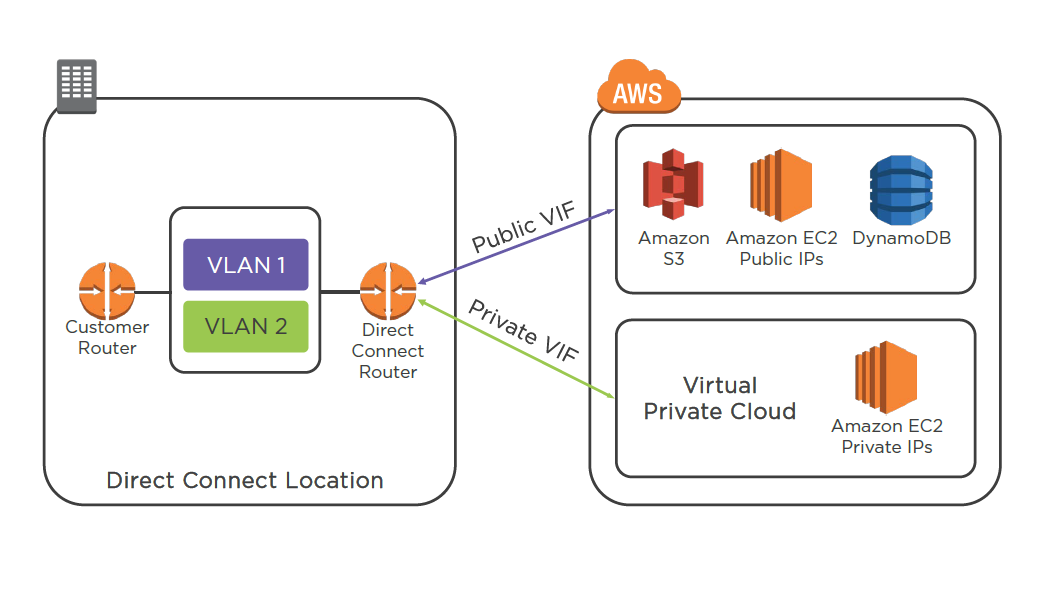
Direct Connect
Deep Dive -AWS Direct Connect and VPNs:
https://youtu.be/SMvom9QjkPk
AWS Direct Connect:
https://aws.amazon.com/directconnect/
AWS VPN CloudHub
Summary
- VPC Overview
- VPC Peering
- VPN Access Types
- Direct Connect
Designing AWS Networking Services: NAT Instances and NAT Gateways
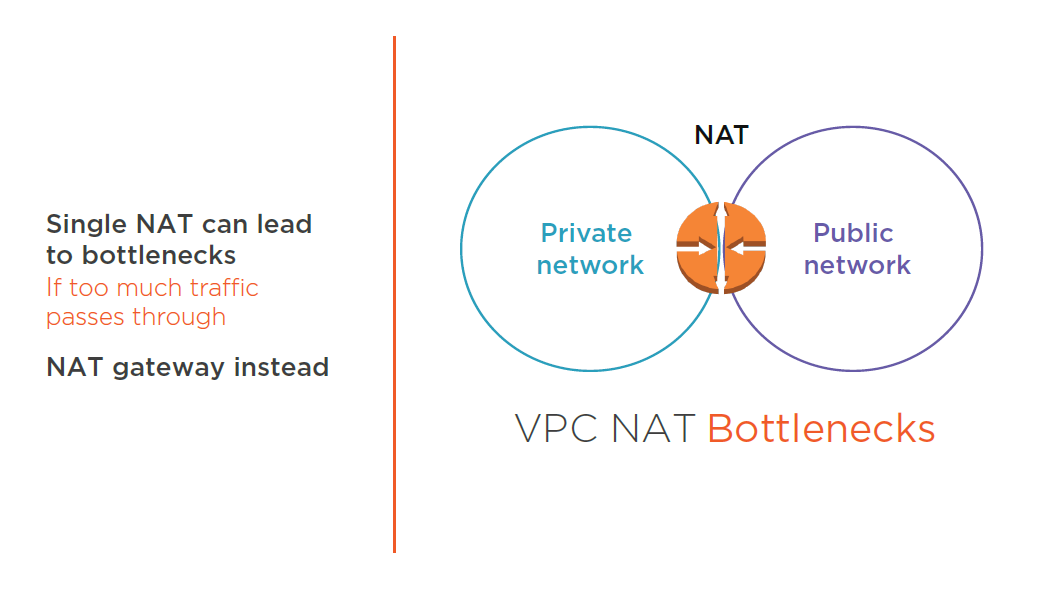
NAT Instances vs NAT Gateways

Creating a VPC
Deploying and configuring a NAT instance
Configuring a NAT Gateway
Summary
- Scaling NAT instances
- Creating a VPC
- Deploying and configuring a NAT instance
- Configuring a NAT Gateway
Designing AWS Networking Services: Domain Name System
- AWS SysOps / AWS Fundamentals courses
- TCP 53 / UDP 53
- Worldwide distributed DNS
- Database of name to IP mappings
- Route 53 has a 100% SLA uptime
- Route 53 API
- Server health checks
- Public Hosted Zone
- Private Hosted Zone for Amazon VPC
- You can extend on-premises DNS to Amazon VPC
- You cannot extend Route 53 to on-premises instances
- Cannot automatically register EC2 instances with private hosted zones
Route 53 Private Hosted Zone
Extend On-premises DNS to EC2 Instances
Summary
- Route 53 overview
- Private Hosted Zone
- On-Premises DNS to Amazon VPC
Designing AWS Networking Services: High Performance Computing
High Performance Computing (HPC)
HPC used by oil & gas, pharmaceuticals, research, automotive, and other industries
Batch processing of compute intensive workloads
Requires high performance CPU, network, and storage
Jumbo Frames are typically required
- HPC workloads typically need access to a shared filesystem, and will use a lot of disk I/O
Jumbo Frames
Help significantly because they can carry up to 9000 bytes of data
Supported on AWS through enhanced networking
Enhanced networking is enabled through single rout I/O virtualization (SR-IOV) on supported instances
Enhanced networking is only supported on Hardware Virtualization (HVM) instances. Not supported on Paravirtulized(PV) instanced
Enabling Enhanced Networking on Linux Instances in a VPC:
http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/enhanced-networking.html
Enabling Enhanced Networking on Windows Instances in a VPC:
http://docs.aws.amazon.com/AWSEC2/latest/WindowsGuide/enhanced-networking.html
Placement Groups
- A logical grouping of instances in a single availability zone (AZ) Can’t span multiple availability zones
- Name must be unique across AWS account
- Recommended for application that benefit from low latency, high bandwidth or both
- Only supported instances that support enhanced networking can be launched into a placement group (C3, C4, D2, I2, M4, E3)
- Existing instances cannot be moved into a placement group
- Placement groups cannot be merged
- Can span peered VPCs but you will not get full-bisection bandwidth between instances
- Reserved instances are supported on an instance level but you cannot explicitly reserved capacity for a placement group
Placement Groups and supported instances:
http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/placement-groups.html
Summary
- HPC Overview
- Jumbo Frames
- Placement Groups
Designing and Optimizing AWS Data Storage Services
Storage and Archive

Amazon S3 Storage Classes

Amazon S3
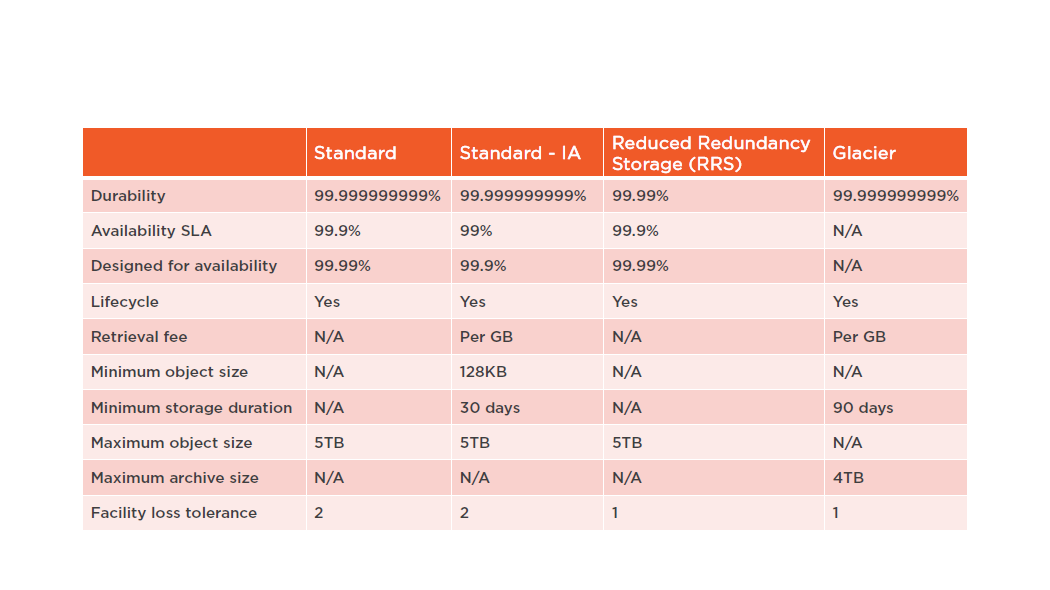
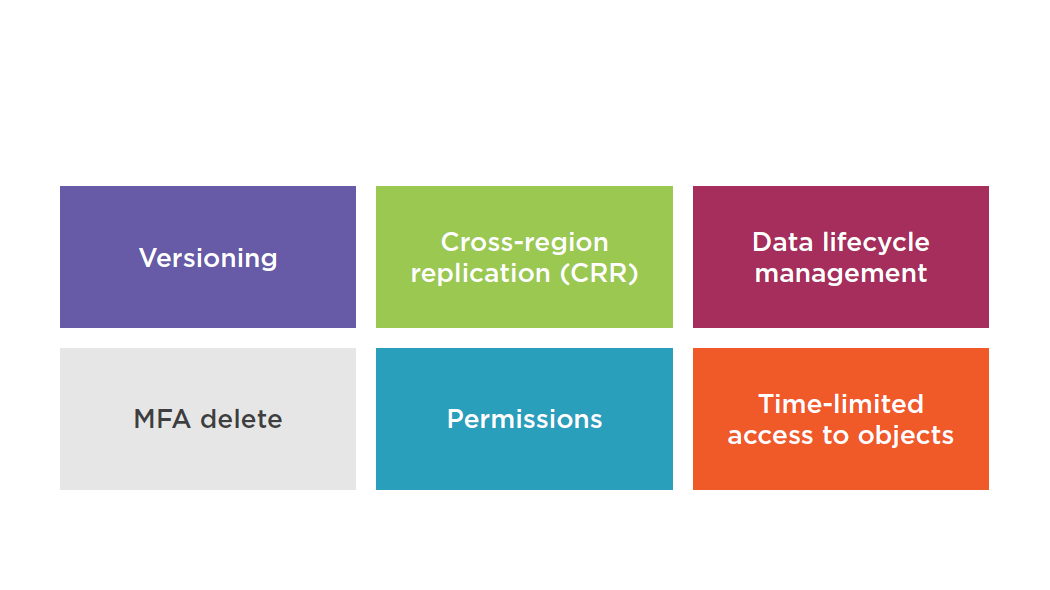
Amazon S3 Features
Optimizing for PUTs
- Parallelization divides files into smaller parts and uploads them simultaneously
- Increase resiliency to network errors
- Moves the bottleneck to the network
- 25-50MB on high bandwidth networks
- 10MB on low bandwidth networks
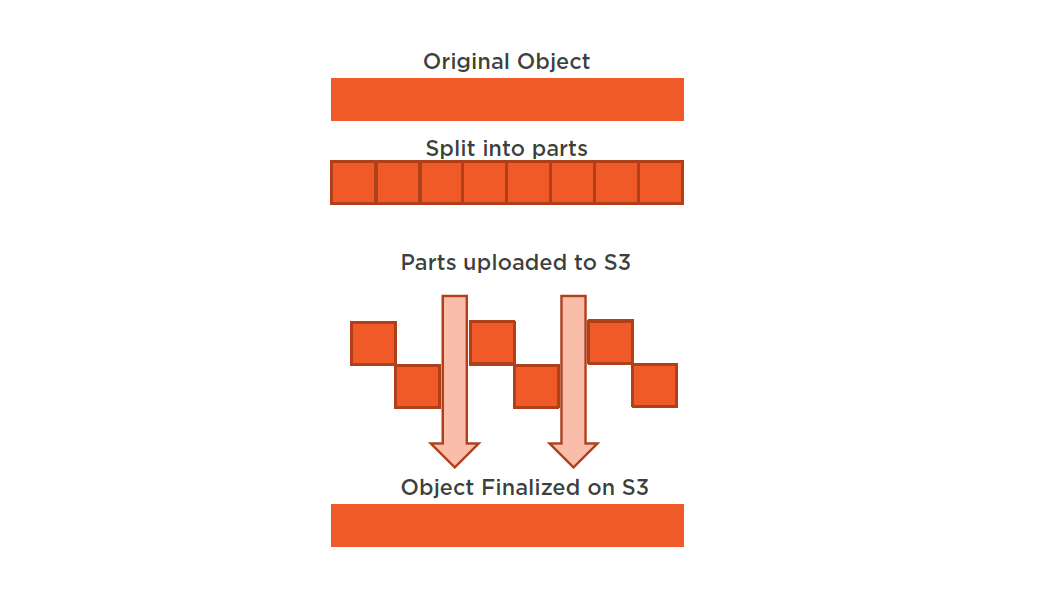
Splitting Files
Windows:
http://www.hjsplit.org/
Linux:
http://www.manpagez.com/man/1/split/
Bucket Explorer:
http://www.bucketexplorer.com/
CloudBerry
S3 Explorer:http://www.cloudberrylab.com/free-amazon-s3-explorer-cloudfront-IAM.aspx
S3 Browser:
http://s3browser.com/
Optimizing for GETs

Parallelizing for GETs
- Use range-based GETs for multithreaded performance
- Using the Range HTTP header in a GET request allows you to retrieve a specific range of bytes for an object stored in S3
- Enables you to send multiple GETs at a time
- Compensates for unreliable networks
- Maximizes bandwidth throughput
Optimizing for GETs
Performance Considerations
yourbucket/2016-18-03/march/photo1.jpg
yourbucket/2016-18-03/march/photo2.jpg
yourbucket/2016-18-03/march/photo3.jpg
Add a Hex Hash Prefix to Key Name
yourbucket/2016-18-03/march/photo1.jpg
yourbucket/2016-18-03/march/photo2.jpg
yourbucket/2016-18-03/march/photo3.jpg
yourbucket/bc66-2016-18-03/march/photo1.jpg
yourbucket/9957-2016-18-03/march/photo2.jpg
yourbucket/1045-2016-18-03/march/photo3.jpg
Add a Hex Hash Prefix to Key Name
yourbucket/621787/march/photo1.jpg
yourbucket/621788/march/photo2.jpg
yourbucket/621789/march/photo3.jpg
yourbucket/621790/march/photo4.jpg
yourbucket/621791/march/photo5.jpg
yourbucket/621792/march/photo6.jpg
yourbucket/787621/march/photo1.jpg
yourbucket/788621/march/photo2.jpg
yourbucket/789621/march/photo3.jpg
yourbucket/790621/march/photo4.jpg
yourbucket/791621/march/photo5.jpg
yourbucket/792621/march/photo6.jpg
Amazon EBS
- Does not need to be attached to an instance
- Cannot be attached to more than one instance at the same time
- Can be transferred between Availability Zones
- EBS volume data is replicated across multiple servers in an Availability Zone
- Encryption of EBS data volumes, boot volumes and snapshots
- Designed for an annual failure rate (AFR) of between 0.1% -0.2% & an SLA 99.95%
Amazon Glacier
Suggested Reading
AWS Storage Options:
https://media.amazonwebservices.com/AWS_Storage_Options.pdf
Summary
- Amazon S3
- Optimizing for GETs / PUTs
- Securing S3
- Amazon EBS
- Amazon Glacier
- AWS Storage Gateway
Understanding AWS Database Services
RDS Characteristics
- Database engine managed by AWS
- MySQL, Oracle, Microsoft SQL, PostgreSQL, MariaDB, and Amazon Aurora
- Multi-AZ deployment options
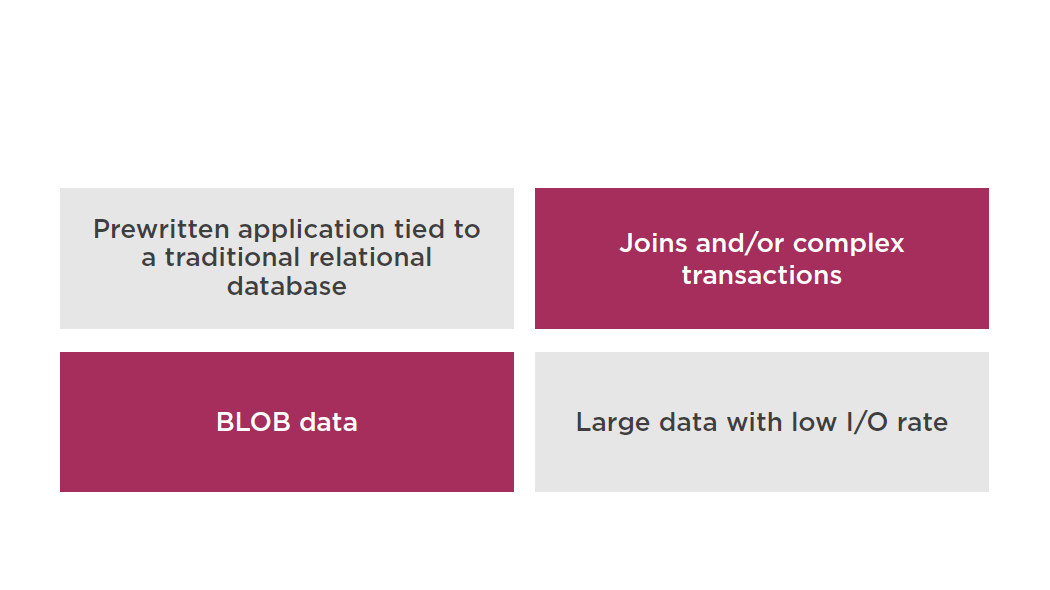
- Ideal for existing applications that rely on traditional relational database engines
- Optimal for new applications with structured data that requires more sophisticated querying and joining capabilities
Amazon RDS for SQL server now supports Windows Authentication
- Using credentials stored in the AWS
- Directory Service for Microsoft Active
- Directory (Enterprise Edition)
Non-ideal RDS Scenarios
Multi-AZ Failover
- Multi-AZ deployment designed for HA
- Synchronous replica in secondary availability zone (AZ)
- Used for disaster recovery, not for scaling
- Multi-AZ is different from an RDS read replica
RDS Read Replicas
- Used for scaling out, not for disaster recovery
- Asynchronous replication / Read-only connections
ACID
Atomicity, Consistency, Isolation, Durability
A set of properties that guarantee that database transactions are processed reliably.
The ACID concept is described in ISO/IEC 10026-1:1992 Section 4
Atomicity
Requires that each transaction be "all or nothing" If one part of the transaction fails, the entire transaction fails, and the database state is left unchanged.
Consistency
Ensures that any transaction will bring the database from one valid state to another.
Isolation
Ensures that the concurrent execution of transactions results in a system state that would be obtained if transactions were executed serially.
i.e., one after the other
Durability
Ensures that once a transaction has been committed, it will remain so, even in the event of power loss, crashes, or errors
Amazon Dynamo DB
DynamoDB is a fully managed, highly available and scalable NoSQL database
Automatically and synchronously replicates data across three Availability Zones
SSDs and limiting indexing on attributes provides high throughput and low latency
ElastiCachecan be used in front of DynamoDB in order to offload high amounts of reads for non-frequently changed data
Ideal for existing or new applications that need:
- A flexible NoSQL database with low read and write latencies
- The ability to scale storage and throughput up or down as needed without code changes or downtime
Non-ideal DynamoDB Scenarios
DynamoDB Integration

Amazon DynamoDB
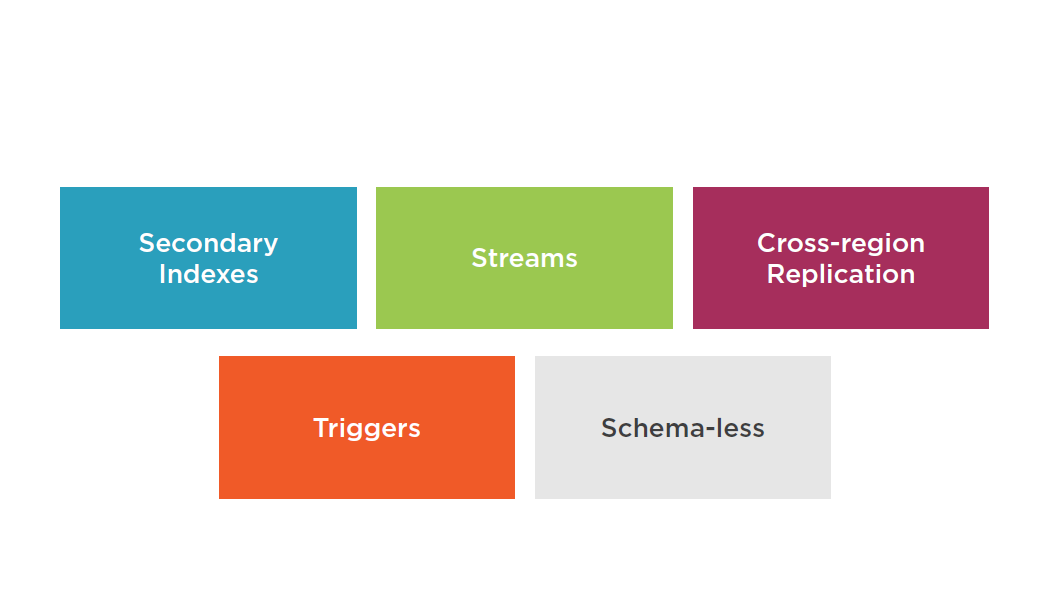
Stores structured data in tables, indexed by a primary key
Tables are a collection of items and Items are made up of attributes (columns)
Primary key can be:
- Single-attribute hash key
- Composite hash-range key
DynamoDB Features
Summary
- RDS
- DynamoDB
Managing AWS Security Strategies: Directory Service
AWS Directory Service Types
AD Connector

Simple AD is a stand-alone, managed directory that is powered by Samba 4 Active Directory Compatible Server
Simple AD

Setting up Simple AD
Setting up AD Connector
Microsoft AD
Managed Microsoft Active Directory, powered by Windows Server 2012 R2
Designed to support up to 50,000 users (approximately 200,000 directory objects including users, groups and computers)
Run directory-aware Windows workload
Create trust relationships between Microsoft AD domains in the AWS cloud, and on-premises
Microsoft AD is deployed across multiple Azs
Automatic monitoring detects and replaces DCs that fail
Data replication and automated daily snapshots are configured for you
No software to install
AWS handles all of the patching and software updates
Setting up Microsoft AD
Summary
- AD Connector
- Simple AD
- Microsoft AD
Managing AWS Security Strategies: STS and Cross Account Access
Security Token Service (STS)
Federated temporary access to AWS resources
Enterprise identity federation
- SAML 2.0
- LDAP, AD FS
- Single Sign-On
Web identity federation:
- Amazon, Facebook, Google, OpenID
Cross Account Access
Terminology
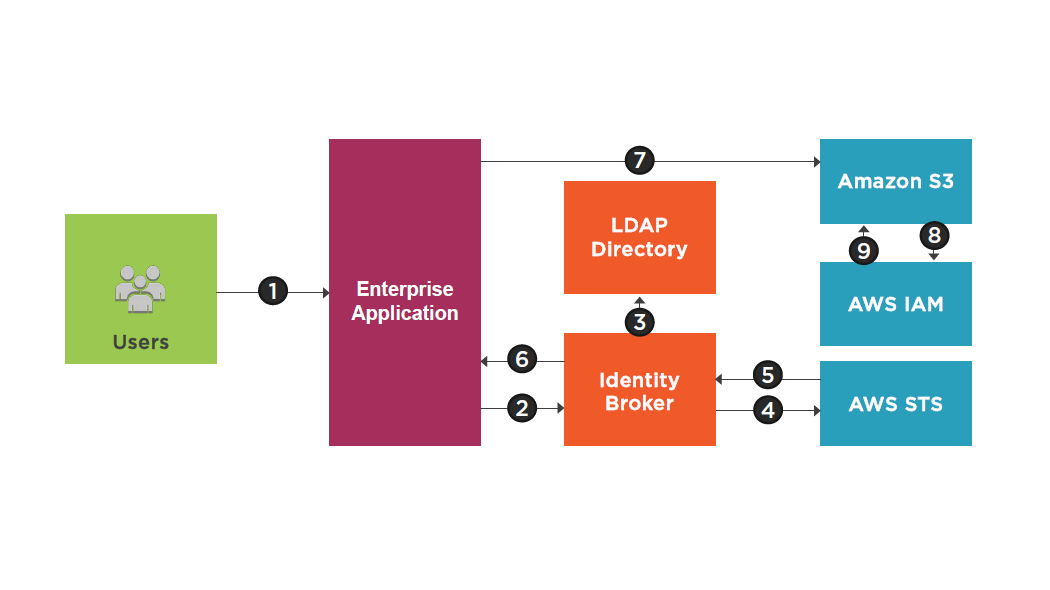
STS Service

Takeaways
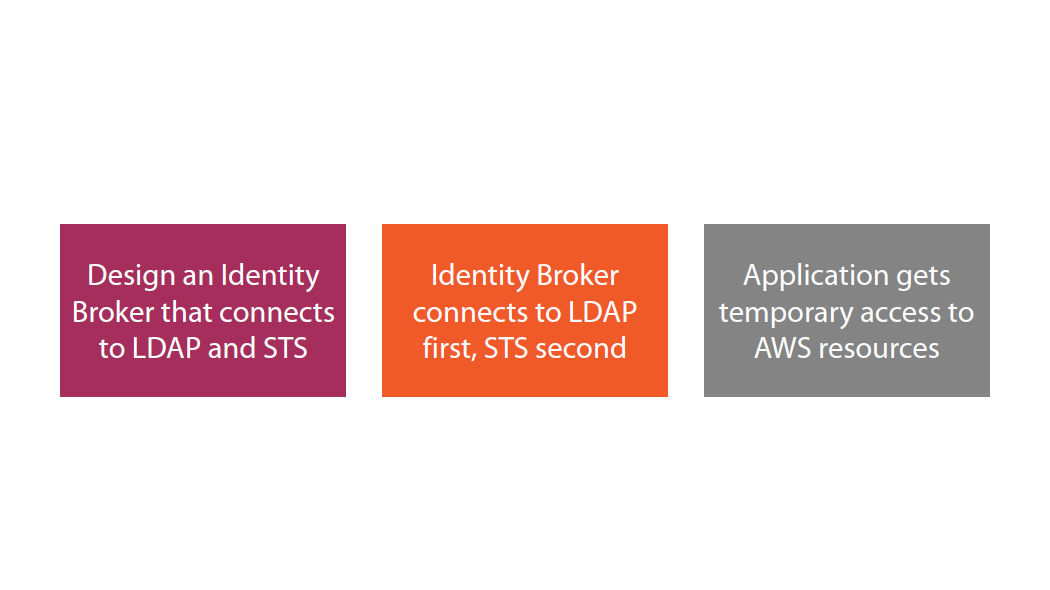
Cross Account Access
Summary
- Security Token Service (STS)
- Cross Account Access
Managing AWS Security Strategies: CloudTrail and CloudWatch
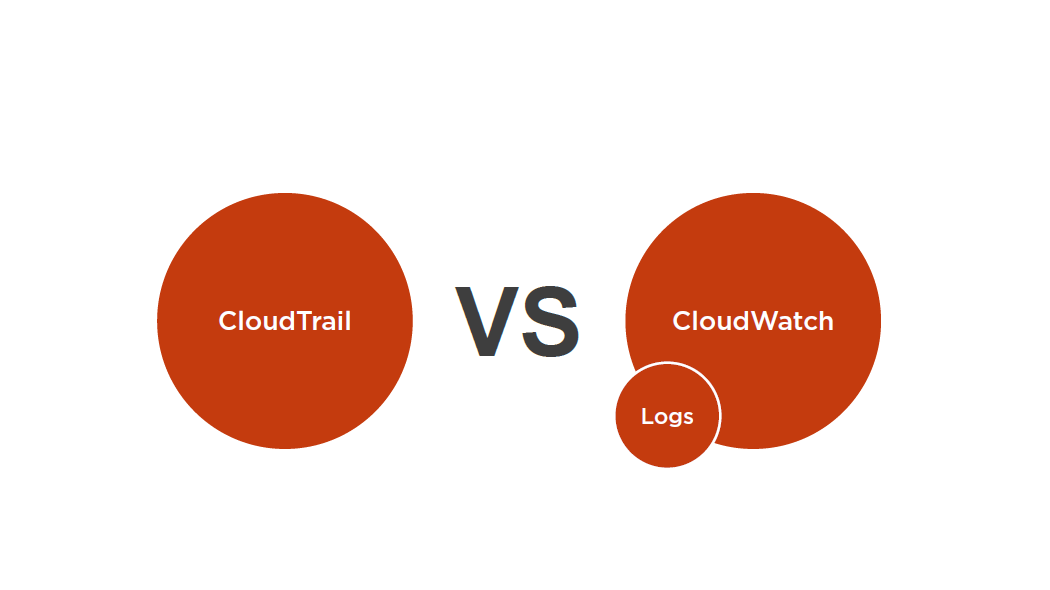
CloudTrail
A web service that records AWS API calls for your account and delivers log files to you
Recorded Information Includes
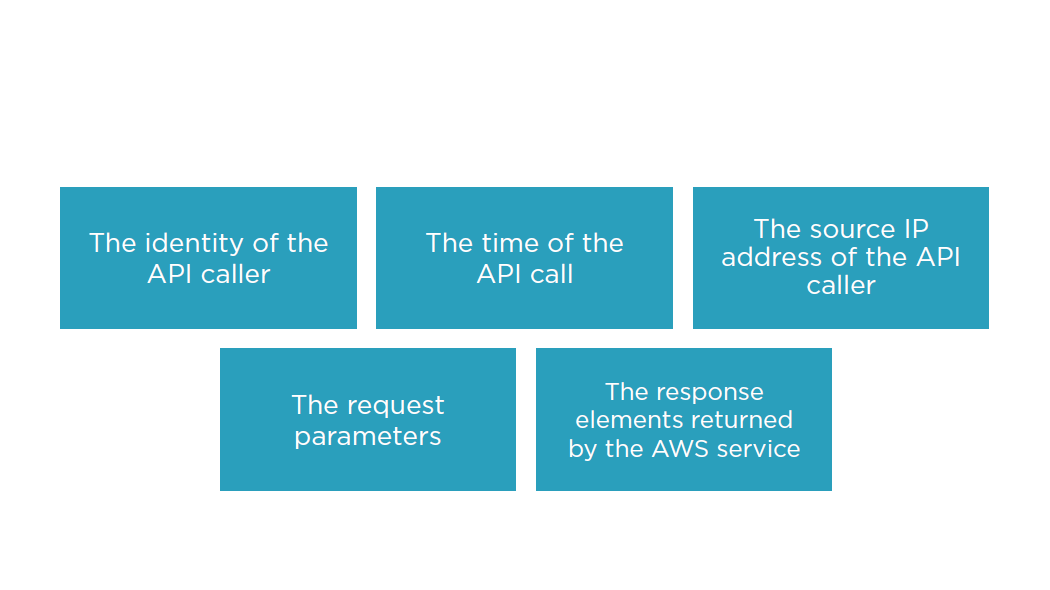
Cloud Trail

A history of API calls for your AWS account
API history enables security analysis, resource change tracking, and compliance auditing
Logs API calls made via:
- AWS Management Console
- AWS SDKs
- Command line tools
- Higher-level AWS services (such as AWS CloudFormation)
Cloud Watch
A monitoring service for AWS cloud resources and the applications you run on AWS
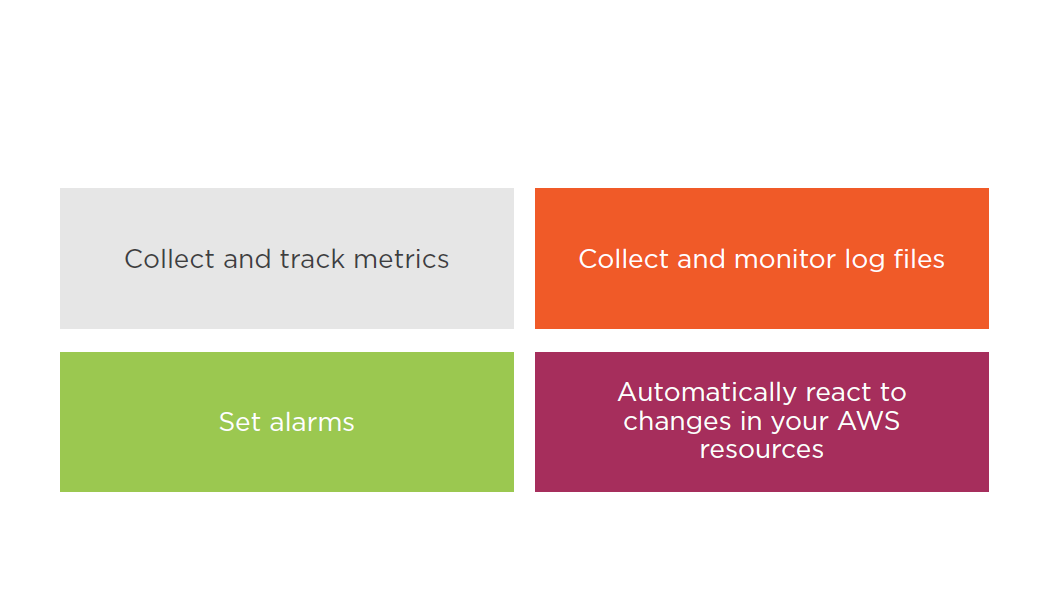
Monitor AWS resources such as:
- Amazon EC2 instances
- Amazon DynamoDB tables
- Amazon RDS DB instances
- Custom metrics generated by your applications and services
- Any log files your applications generate
Gain system-wide visibility into resource utilization
Application performance
Operational health
Cloud Watch Logs
By default, CloudWatch Logs will store your log data indefinitely
Alarm history is stored for 14 days
CloudTrail logs can be sent to CloudWatch Logs for real-time monitoring
CloudWatch Logs metric filters can evaluate CloudTrail logs for specific terms, phrases, or values
You can assign CloudWatch metrics to the metric filers
You can create CloudWatch alarms
Storing Logs
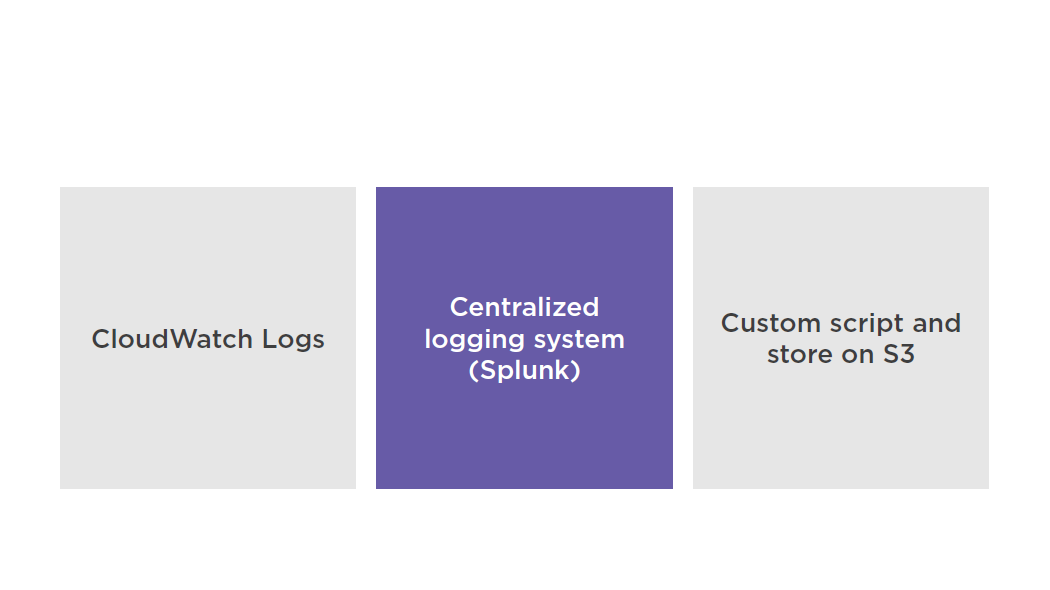
Monitoring
Do not store logs on non persistent disks:
- EC2 instances root volume
- Ephemeral storage
Best practice is to store logs in CloudWatch Logs or S3
CloudTrail can be used across multiple AWS accounts while being pointed to a single S3 bucket (requires cross account access)
CloudWatch Logs subscription can be used across multiple AWS accounts (requires cross account access)
Summary
- CloudTrail
- CloudWatch
- Storing logs
- Monitoring
Managing AWS Security Strategies: CloudHSM, DDoS and IDS/IPS
Hardware Security Module (HSM)
A physical computing device that safeguards and manages digital keys for strong authentication and provides cryptoprocessing.
HSMs can be used in any application that uses digital keys
Used to protect high value keys
HSM uses are as follows:
- Onboard secure cryptographic key generation
- Onboard secure cryptographic key storage and management
- Use of cryptographic and sensitive data material
- Offloading application servers for complete asymmetric and symmetric cryptography
HSM Overview
HSMs are also deployed to manage Transparent Data Encryption (TDE) keys for databases
TDE Automatically encrypts the data before it is written to the underlying storage device and decrypts when it is read from the storage device
Oracle requires key storage outside of KMS and integrates with CloudHSM
SQL Server requires a key but is managed by RDS after enabling TDE
CloudHSM Overview
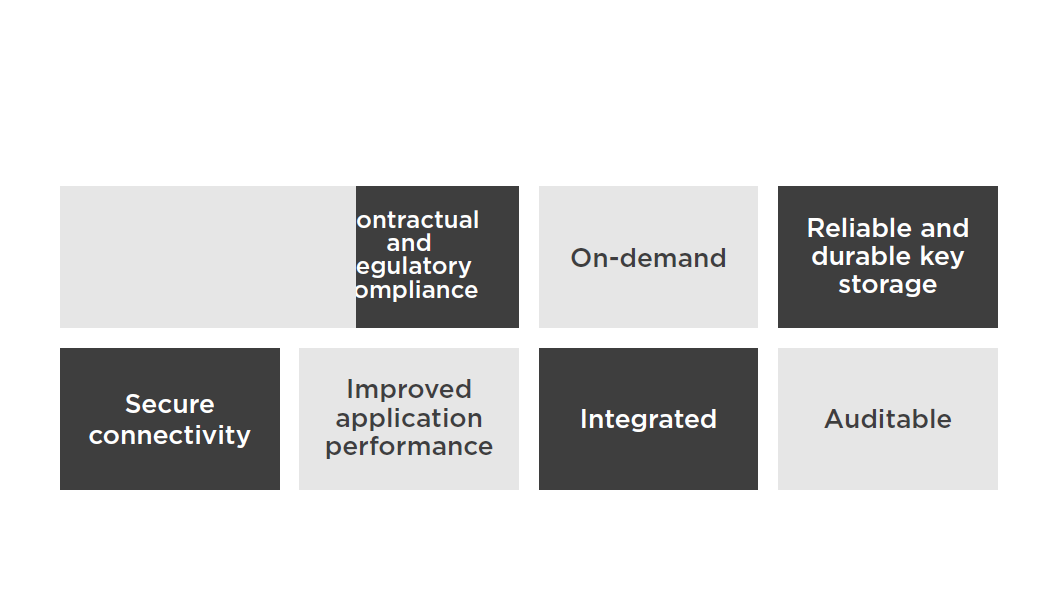
CloudHSM
- Single tenant
- Deployed within VPC
- VPC Peering is supported
- Integrates with RDS (SQL and Oracle) and Redshift
- EBS volume encryption, S3 object
- encryption, and key management are supported but require custom scripting
- For HA and FT a cluster is required
- Monitored via syslog
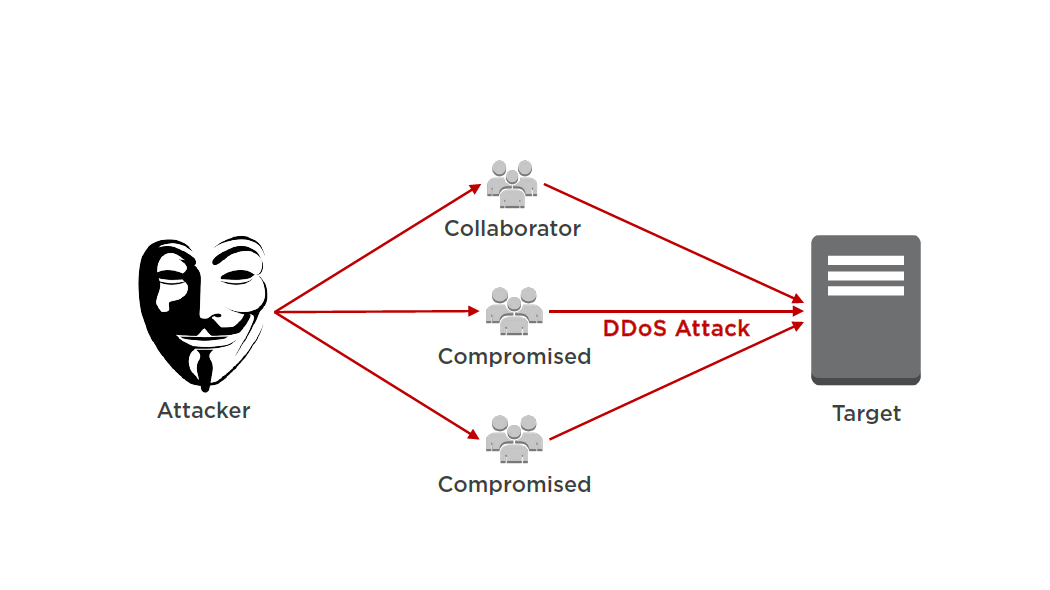
Distributed Denial of Service (DDoS)
A type denial of service attack where multiple compromised systems are used to target a single system
Reflection Attack
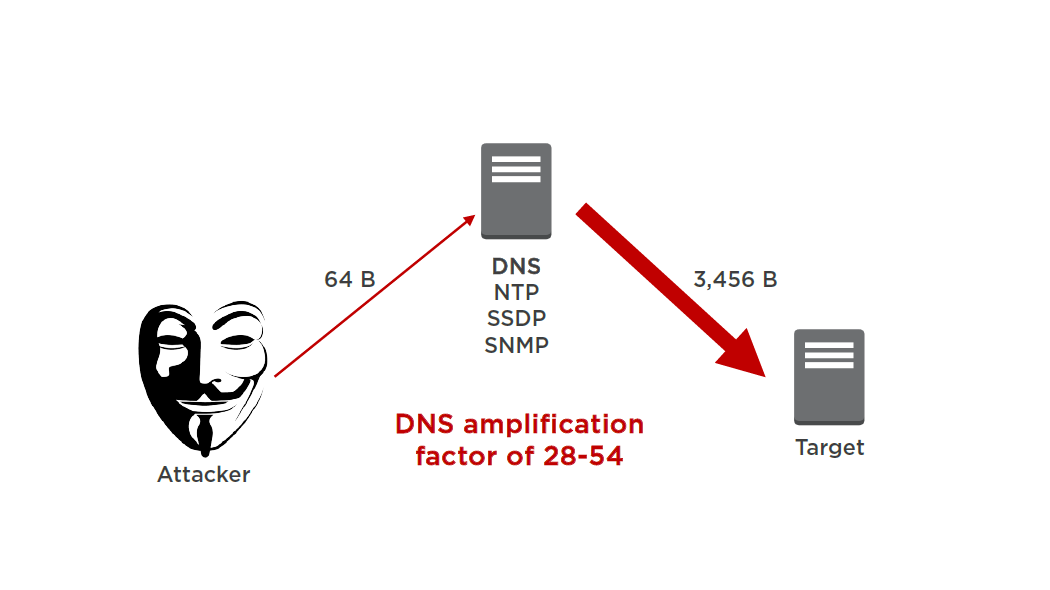
Amplification Attack
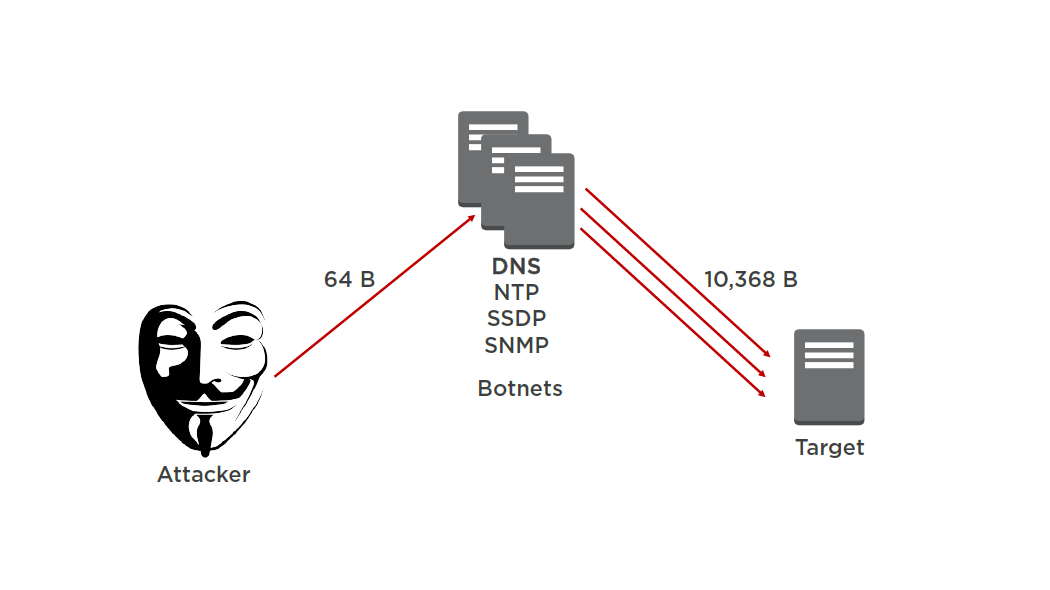
Flood, Reflection and Amplification Attack
Mitigation Techniques
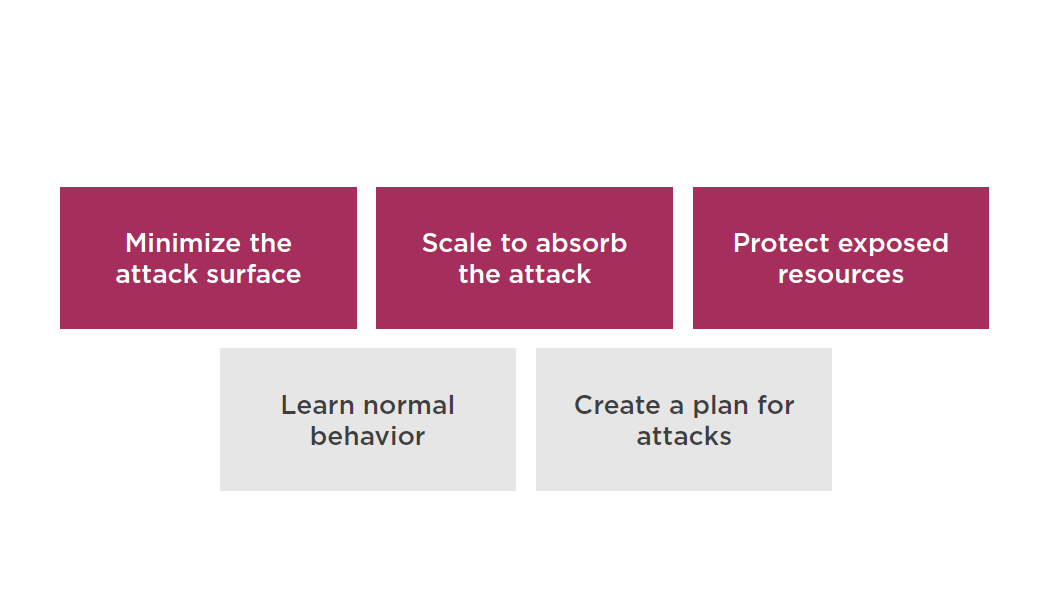
Minimize the Attack Surface
Reduce the number of necessary Internet entry points
Eliminate non-critical Internet entry points
Separate end user traffic from management traffic
Obfuscate necessary Internet entry points to the level that untrusted end users cannot access them
Decouple Internet entry points to minimize the effects of attacks
Scale to Absorb the Attack
Design your infrastructure to scale out and scale up
Attackers have to expend more resources to scale up the attack
Attack is spread over a larger area
Scaling buys you time to analyze the attack and respond
Scaling provides you more redundancy
Protect Exposed Resources

Create a Plan for Attacks
Validate the architecture and select the techniques that work for your infrastructure and application
Evaluate the costs for increased resiliency and understand the goals of your defense
Know who to contact when an attack happens
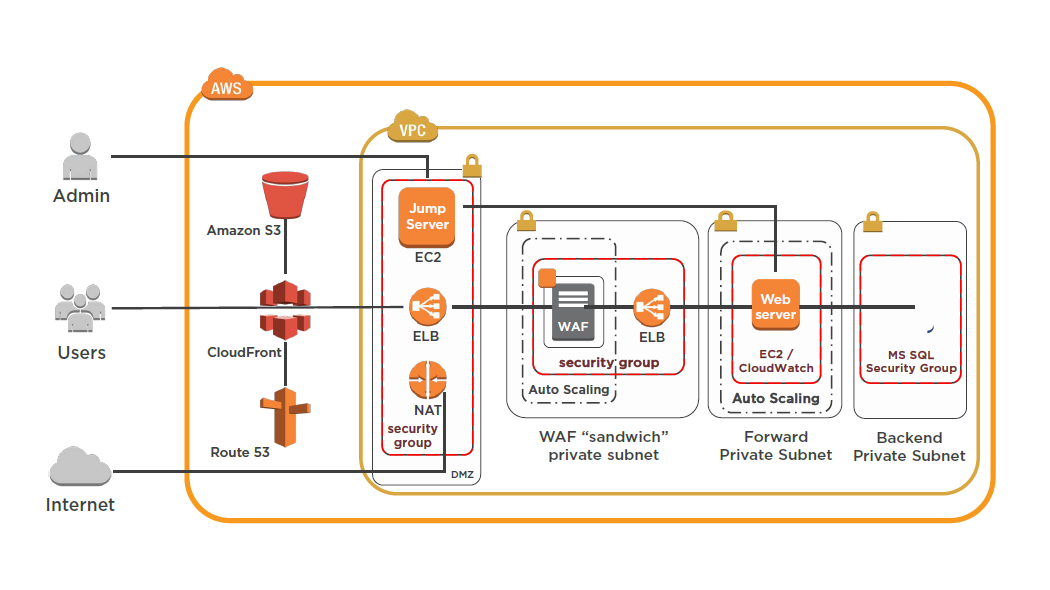
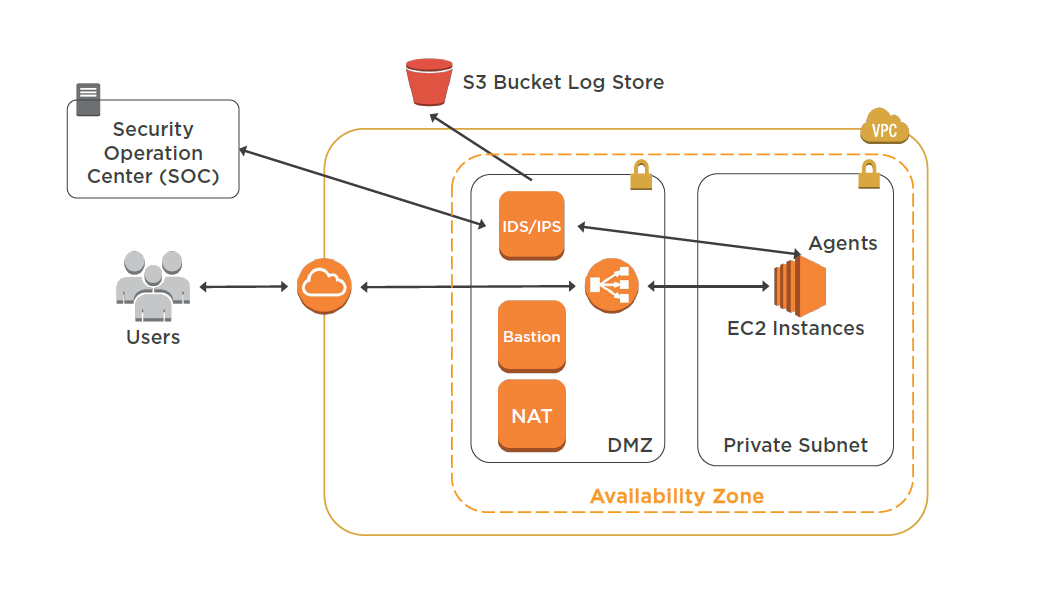
Intrusion Detection System (IDS)
An intrusion detection system (IDS) inspects all inbound and outbound network activity and identifies suspicious patterns that may indicate a network or system attack from someone attempting to break into or compromise a system.
Intrusion Prevention System (IPS)
An Intrusion Prevention System (IPS) is a network security/threat prevention technology that examines network traffic flows to detect and prevent vulnerability exploits.
Suggested Reading
AWS Best Practices for DDoS Resiliency:
https://d0.awsstatic.com/whitepapers/DDoS_White_Paper_June2015.pdf
Summary
- CloudHSM
- DDoS
- IDS/IPS
Managing Billing Strategies: EC2 Standard and Reserved Instances
EC2 Instance Types
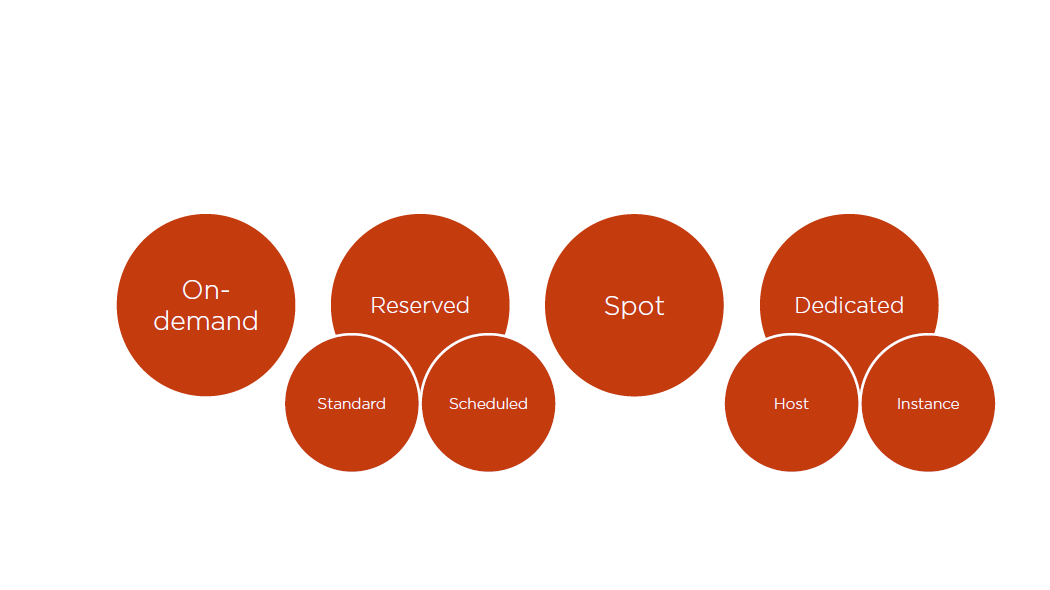
On-demand:
- Low cost and flexibility with no up front cost
- Ideal for auto scaling groups and unpredictable workloads
- Dev/test
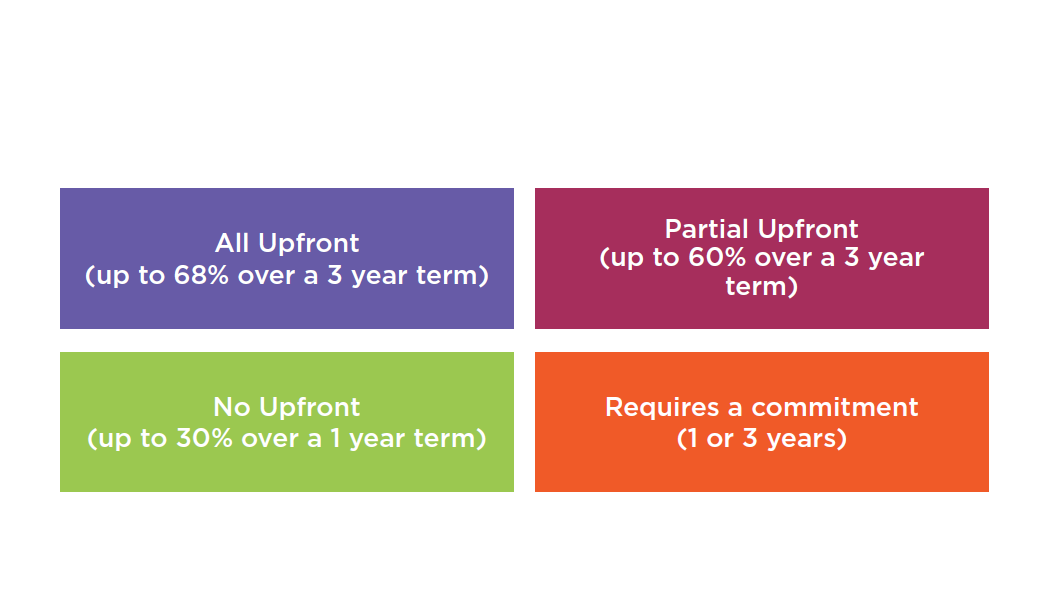
Reserved Instances:
- Steady state and predictable usage
- Applications that need reserved capacity
- Upfront payments reduce hourly rate
- Scheduled Rismatch your capacity reservation to a predictable recurring schedule
Spot:
- Flexible start and end times
- Grid computing and HPC
- Very low hourly compute cost
Dedicated:
- Predictable performance
- Complete isolation
- Most expensive
EC2 Instance Family
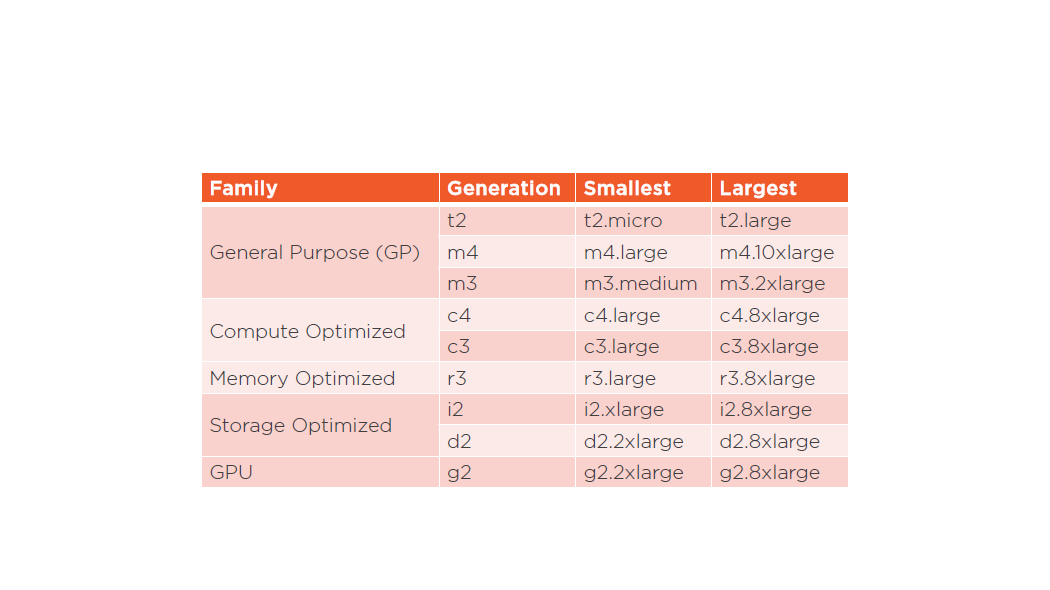
Standard Reserved Instances Attributes
Scheduled Reserved Instances Attributes

Modifying Your RIs
Switch Availability Zones within the same region
Change the instance size within the same instance type
Instance type modifications are supported only for Linux. Due to licensing differences, Linux RIs cannot be modified to RedHator SUSE
You cannot change the instance size of Windows Reserved Instances
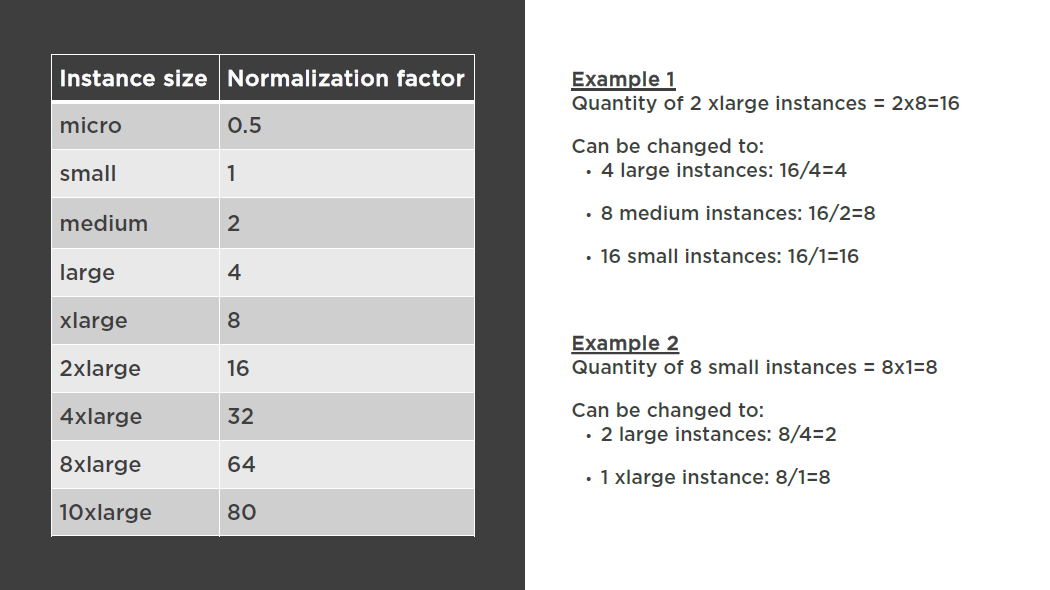
Modification Requests
RDS Reserved Instances
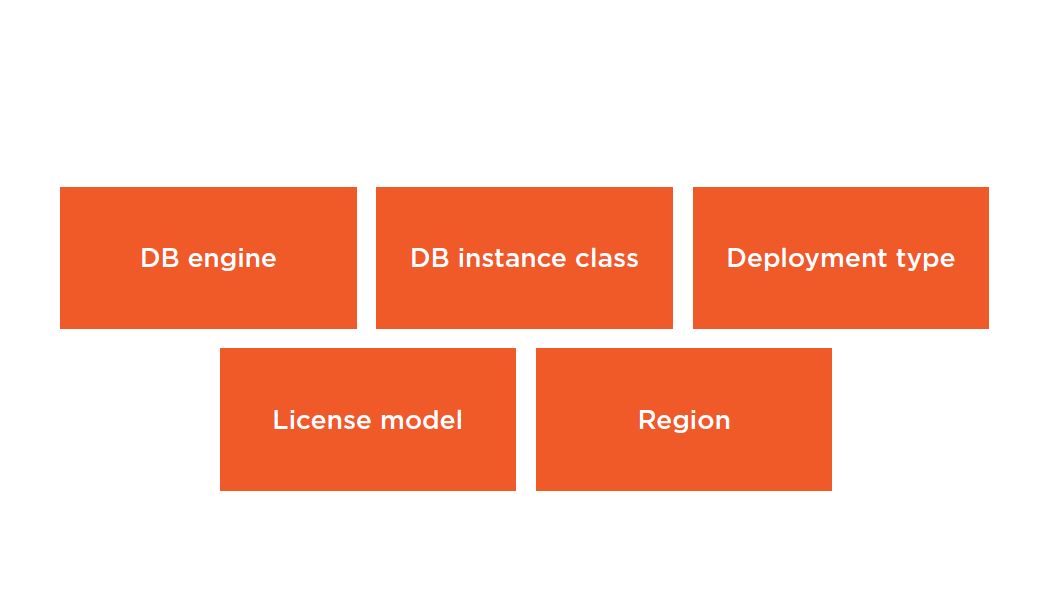
Move between AZs in the same Region
Are available for Multi-AZ deployments
Can be applied to Read Replicas provided the DB Instance class and Region are the same
Summary
- EC2 instance types
- EC2 reserved instances
- RDS reserved instances
Managing Billing Strategies: Consolidated Billing and Resource Groups
Consolidated Billing
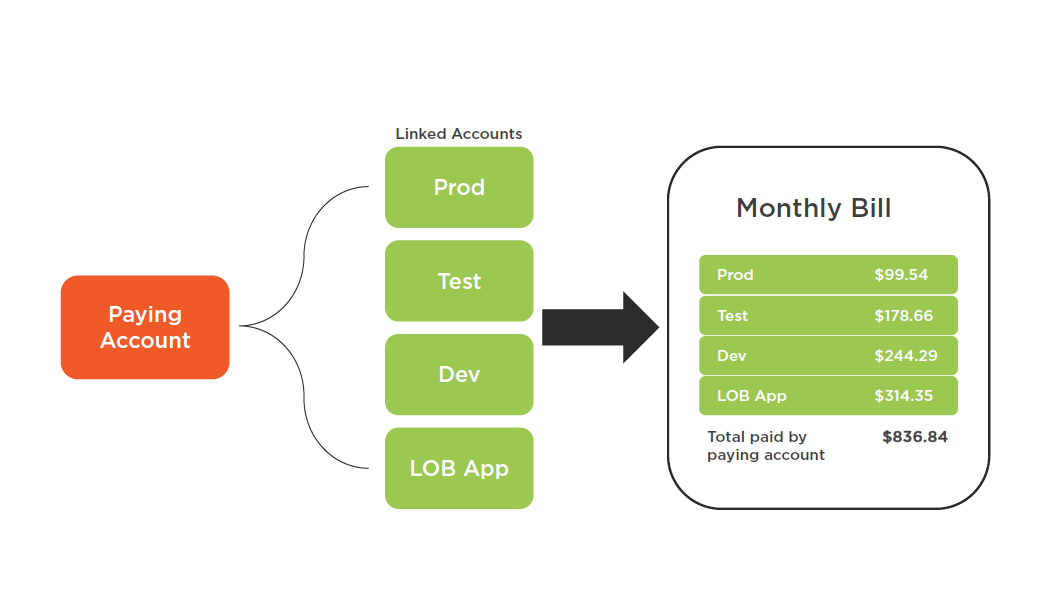
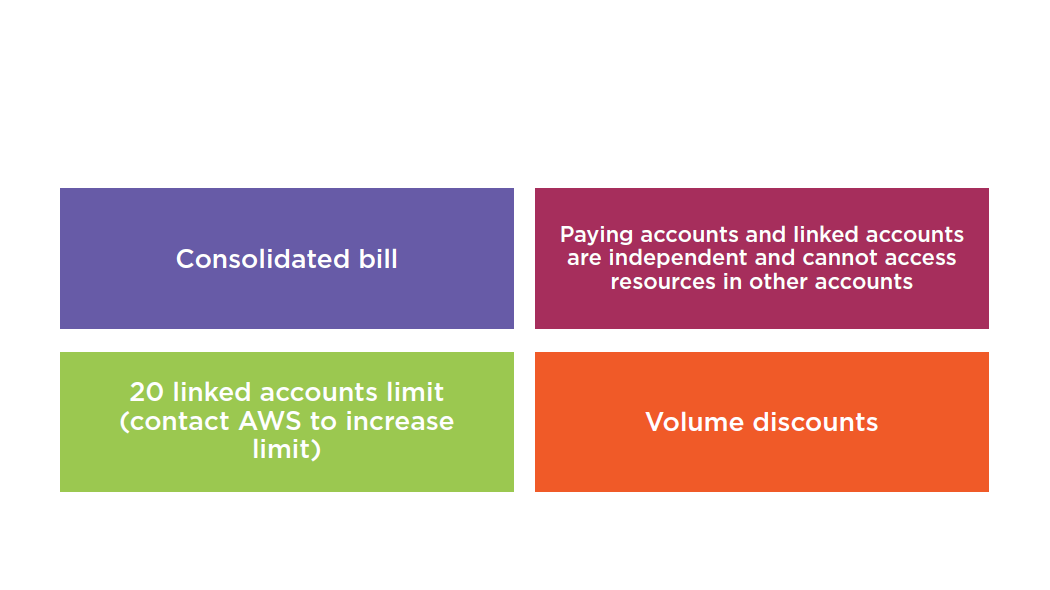
Consolidated Billing Advantages
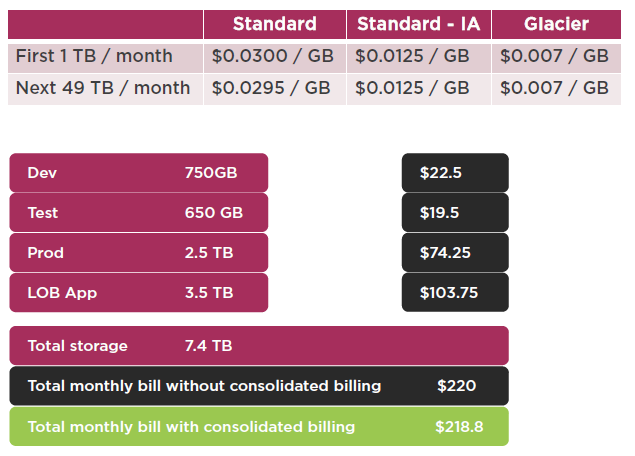
Volume Discounts Example
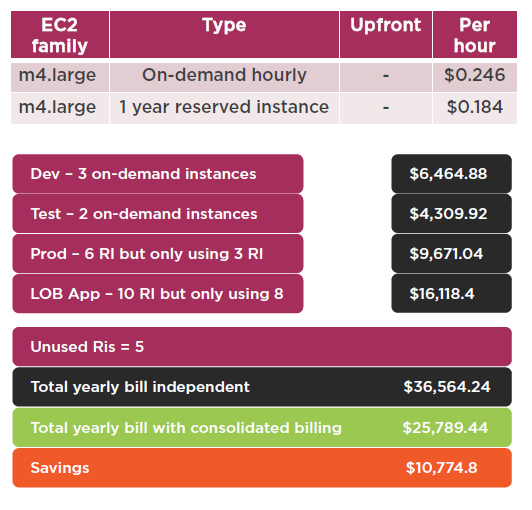
Paying Account
- Use complex password
- Use MFA
- Do not deploy resources in paying account
- Enabling monitoring (billing alerts) on paying account consolidates billing data for all linked accounts
- You can still create billing alerts per account
CloudTrail
Enabled per account per region
You can consolidate all logs into a single S3 bucket:
- Turn on CloudTrail in paying account
- Create an S3 bucket policy that allows cross account access
- Turn on CloudTrail in all other accounts
- Configure all accounts to store logs in the paying account S3 bucket
Resource Groups
A resource group is a collection of resources that share one or moretagsor portions of tags, and can be managed as a single group rather than move from one AWS service to another for each task.
Use a single page to view and manage your resources
Combines information about multiple resources, such as metrics, alarms, and configuration details
Create a custom console that organizes and consolidates the information you need based on your project and the resources you use
Quickly identify resources that are not tagged
Can be shared among users in the same AWS account by sharing a URL
Users of the same AWS account can have different resource groups
Creating Resource Groups
Working with Resource Groups
Summary
- Consolidated Billing
- CloudTrail
- Resource Groups
Understanding CloudFormation, Elastic Beanstalk and OpsWorks
AWS CloudFormation
Gives developers and systems administrators an easy way to create and manage a collection of related AWS resources, provisioning and updating them in an orderly and predictable fashion.
Supported Services
- Virtual Private Cloud (VPC)
- Auto Scaling
- Elastic Compute Cloud (EC2)
- Elastic Load Balancer (ELB)
- Identity and Access Management (IAM)
- Route 53
- Amazon S3
- CloudWatch
- Relational Database Service
- DynamoDB
- CloudFront
- CloudTrail
- Elastic Beanstalk
- Amazon ElastiCache
- Simple Notification Service (SNS)
- Simple Queue Service (SQS)
- Amazon Kinesis
- AWS OpsWorks
- Amazon Redshift
- Amazon SimpleDB
Templates and Stacks
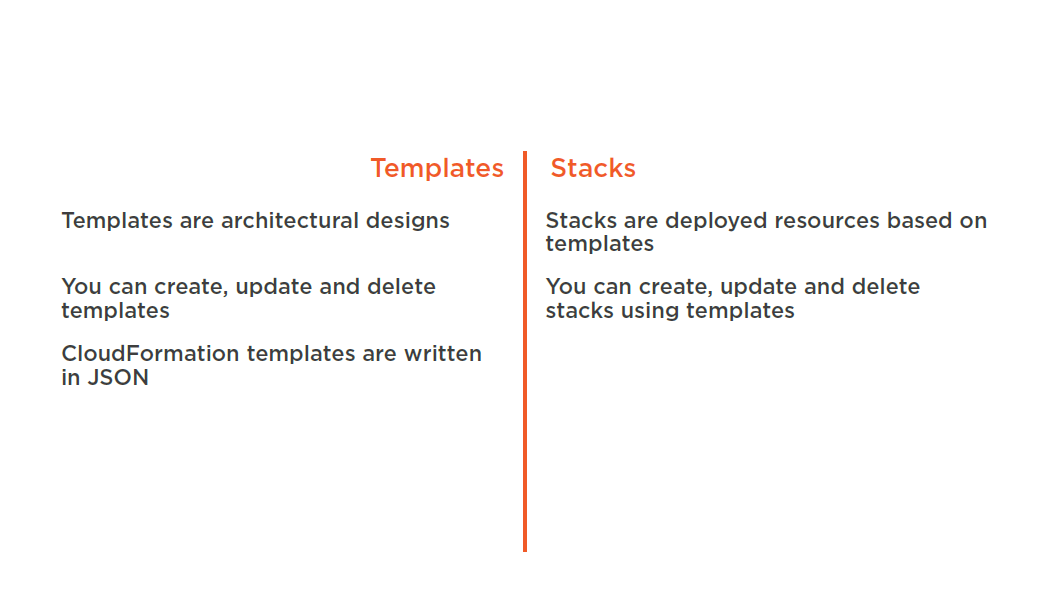
Templates and Stacks
You don’t need to figure out the order for provisioning AWS services
You don’t need to worry about making dependencies work
Modify and update templates in a controlled and predictable way
- In effect applying version control
Visualize your templates as diagrams and edit them using a drag-and-drop interface with the AWS Cloud Formation Designer
Deploying Stacks
Template Elements
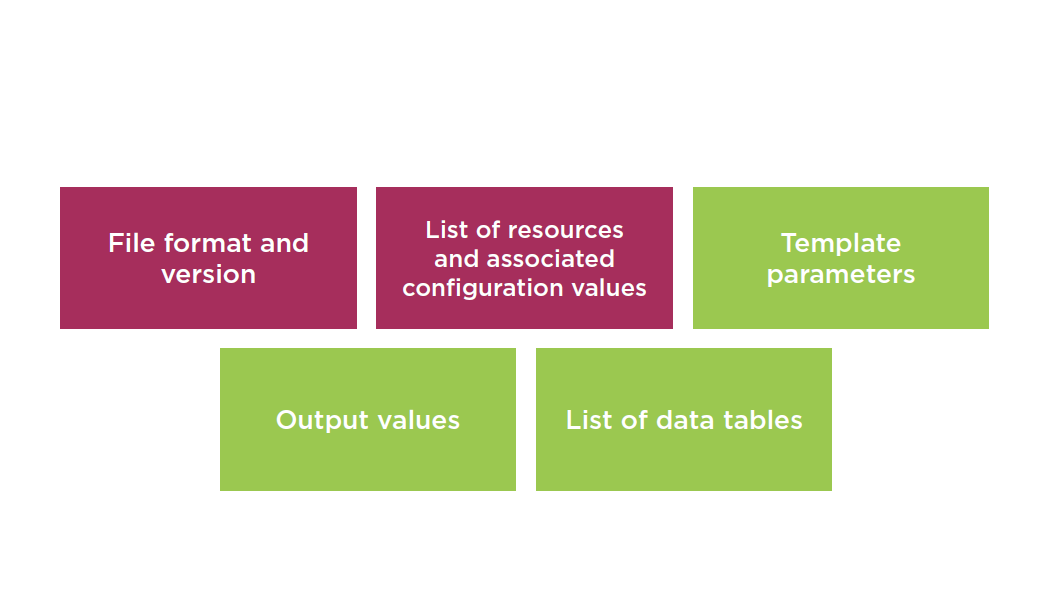
Intrinsic Function
Provides several built-in functions that help you manage your stacks
Assign values to properties that are not available until runtime
Functions include:
- Fn::Base64
- Condition Functions
- Fn::FindInMap
- Fn::GetAtt
- Fn::GetAZs
- Fn::Join
- Fn::Select
- Ref
Fn::GetAtt
Declaration:
"Fn::GetAtt" : [ "logicalNameOfResource", "attributeName" ]
Example:
"Fn::GetAtt" : [ “ELB" , "DNSName" ]
Additional Reading
Intrinsic Function:
http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/intrinsic-function-reference.html
Fn::GetAtt:
http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/intrinsic-function-reference-getatt.html
Need to Know
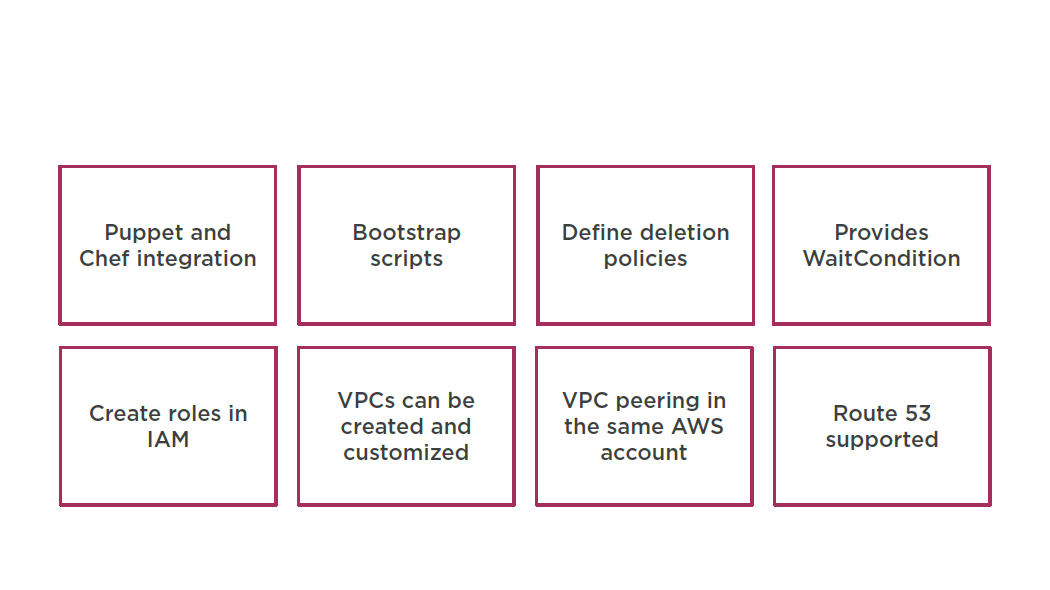
Stack Creation Errors
Automatic rollback on error is enabled by default
You will be charged for resources provisioned even if there is an error
CloudFormation is free
AWS Elastic Beanstalk
A service for deploying and scaling web applications and services. Upload your code and Elastic Beanstalk automatically handles the deployment, from capacity provisioning, load balancing, auto-scaling to application health monitoring.
Elastic Beanstalk Overview
- Integrates with VPC
- Integrates with IAM
- Can provision RDS instances
- Full control of resources
- Code is stored in S3
- Multiple environments are supported to enable versioning
- Changes from Gitrepositories are replicated
- Linux and Windows 2008 R2 AMI support
- Deploy code using a WAR file or Gitrepository
- Use AWS toolkit for Visual Studio and AWS Toolkit for Eclipse to deploy to Elastic Beanstalk
- Elastic BeanStalkis fault tolerant within a single region (not FT between regions)
- By default your applications are publicly accessible
Elastic Beanstalk Management
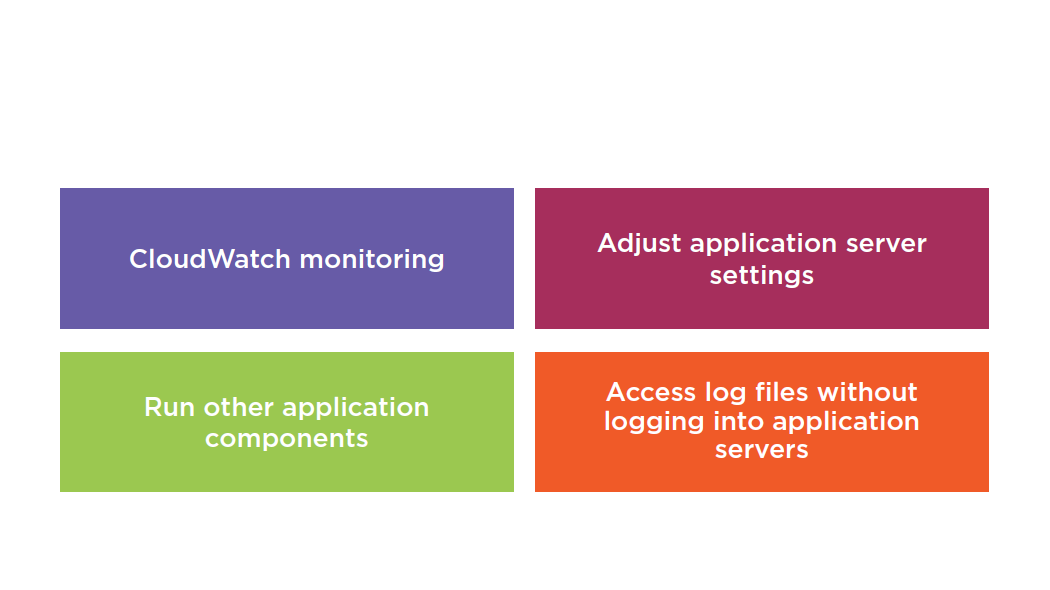
Cloud Formation vs Elastic Beanstalk
Cloud Formation supports Elastic Beanstalk
Elastic Beanstalk does not provision CloudFormation templates
Elastic Beanstalk is ideal for developers with limited cloud experience that need to deploy environments fast
Elastic Beanstalk is ideal if you have a standard PHP, Java, Python, Ruby, Node.js, .NET, Go, or Docker application that can run on an app server with a database.
AWS OpsWorks
A configuration management service that helps you automate operational tasks like software configurations, package installations, database setups, server scaling, and code deployment using Chef.
What Is Chef?
- Automation platform that transforms infrastructure into code
- Automates how applications are configured, deployed, and managed across your network
- Chef server stores your recipes and configuration data
- Chef client (node) is installed on each server
OpsWorksComponents
Use the AWS Management Console
Consists of two elements: Stack and Layers
Stacks are containers of resources (EC2, RDS, ELB) that you want to manage collectively
Every Stack contains one or more layers:
- Web application layer
- Database layer
Layers automate the deployment of packages for you
Summary
- CloudFormation
- Elastic Beanstalk
- OpsWorks
Understanding CloudFront, Kinesis Streams, & SNS Mobile Push Notifications
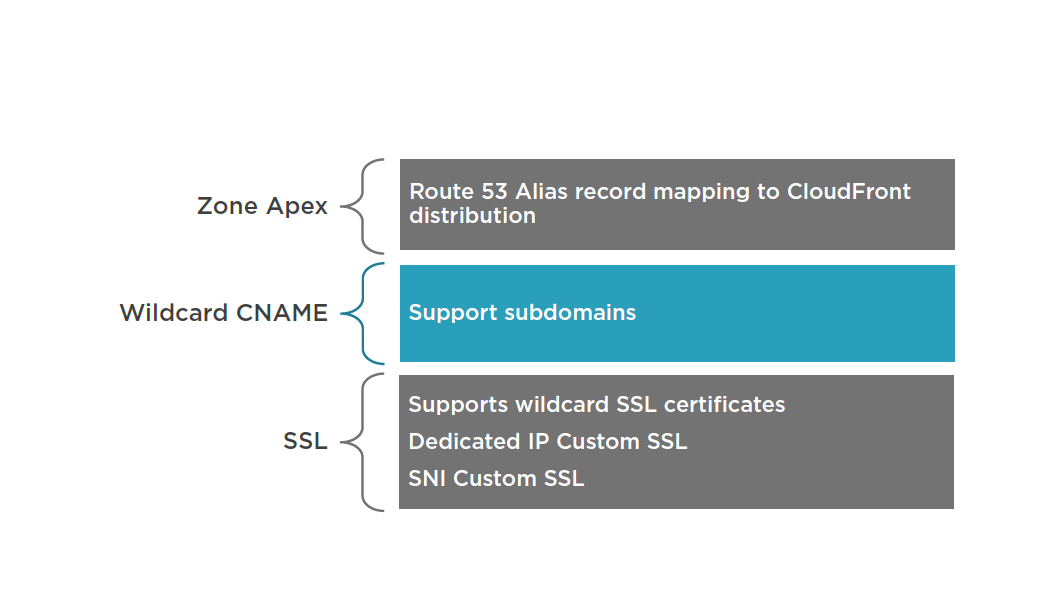
CloudFront
A global CDN service. It integrates with other AWS products to give developers and businesses an easy way to distribute content to end users with low latency, high data transfer speeds, and no minimum usage commitments.
Used to deliver an entire website using a global network of edge locations
- Dynamic, static, streaming, interactive
Requests for content is automatically routed to the nearest edge location for best possible performance
Optimized to work with other Amazon Web Services
- Amazon S3
- Amazon EC2
- Amazon Elastic Load Balancing
- Amazon Route 53
CloudFront Characteristics

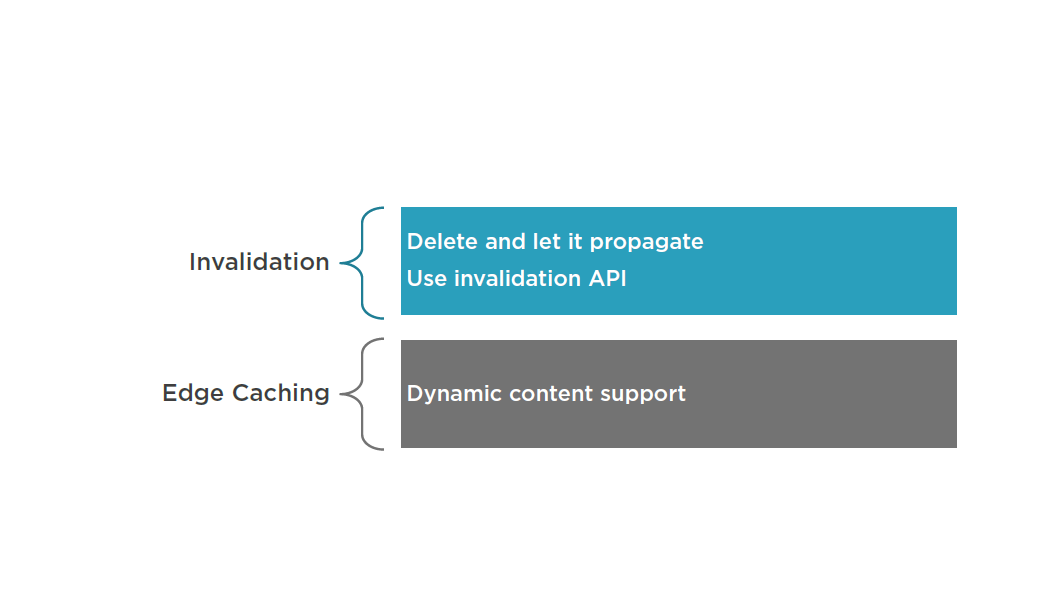
ElastiCache
Open-source in-memory caching engines
- Memcached
- Widely adopted memory object caching system
- Redis
- Popular open-source in-memory key-value store
- Supports data structures such as sorted sets and lists
Master / Slave replication and Multi-AZ
- Can be used to achieve cross AZ redundancy
Memcached vs. Redis
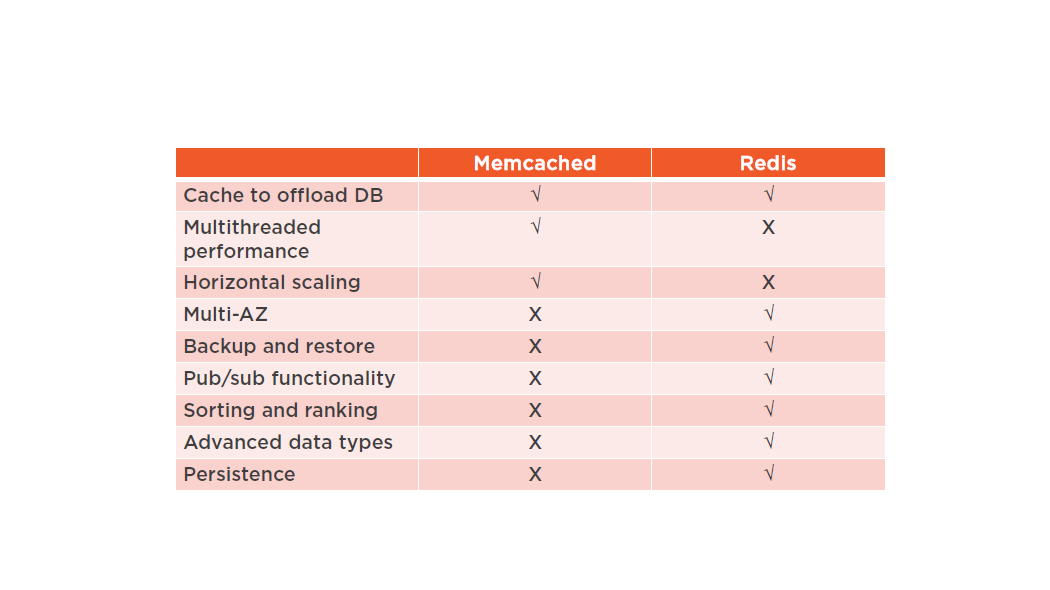
Suggested Reading
Performance at Scale with Amazon ElastiCache:
https://d0.awsstatic.com/whitepapers/performance-at-scale-with-amazon-elasticache.pdf
Kinesis Streams
Enables you to build custom applications that process or analyze streaming data for specialized needs. It can continuously capture and store TB of data per hour from thousands of sources such as website clickstreams, financial transactions, social media feeds, IT logs, and location-tracking events.
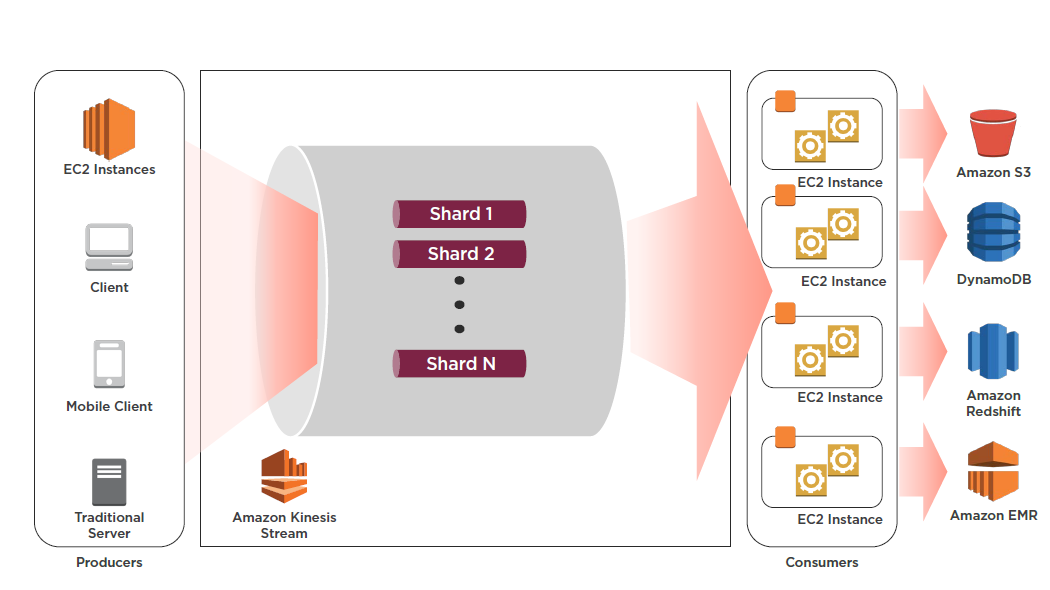
By default data is stored for 24 hours, but can be increased to 7 days
Streams Terminology
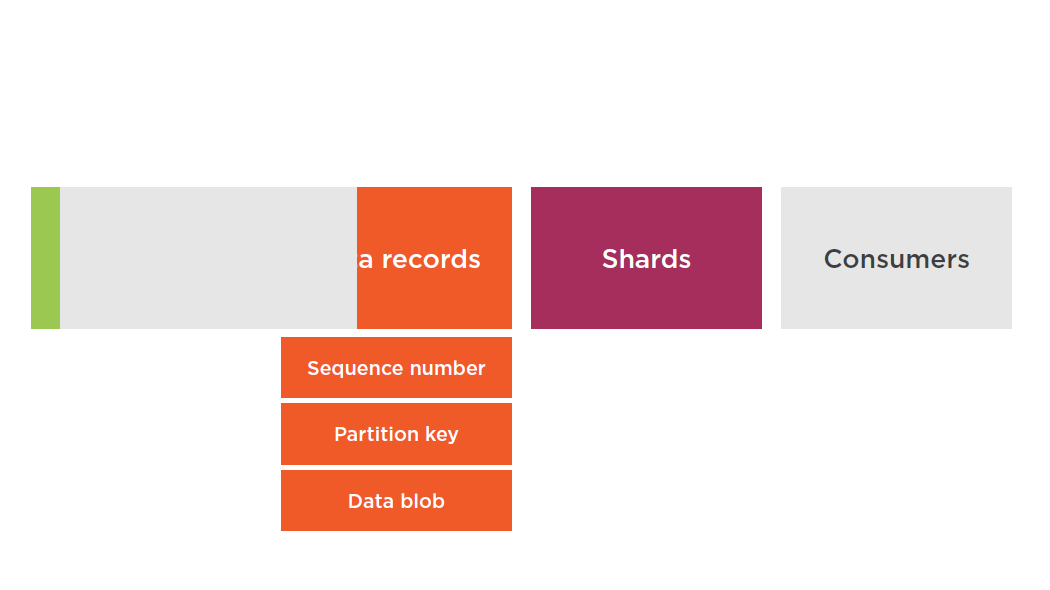
Shards
A uniquely identified group of data records in a stream
A stream is composed of one or more shards, each of which provides a fixed unit of capacity
Can support up to 5 transactions per second for reads
Max total data read rate of 2 MB/s
Up to 1,000 records per second for writes
Max total data write rate of 1 MB/s (including partition keys)
If your data rate increases, add more shards to increase the size of your stream. Remove shards if the data rate decreases.
Partition Keys
Used to group data by shard within a stream
Stream service segregates data records belonging to a stream into multiple shards
Use partition keys associated with each data record to determine which shard a given data record belongs to
Specified by the applications putting the data into a stream
Data Blobs
The data your producer adds to a stream. The maximum size of a data blob (the data payload after Base64-decoding) is 1 megabyte (MB).
Consumers
Consumers get records from Amazon Kinesis Streams and process them. These consumers are known as Amazon Kinesis Streams Applications.
SNS Mobile Push Notifications
The ability to send push notification messages directly to apps on mobile devices.
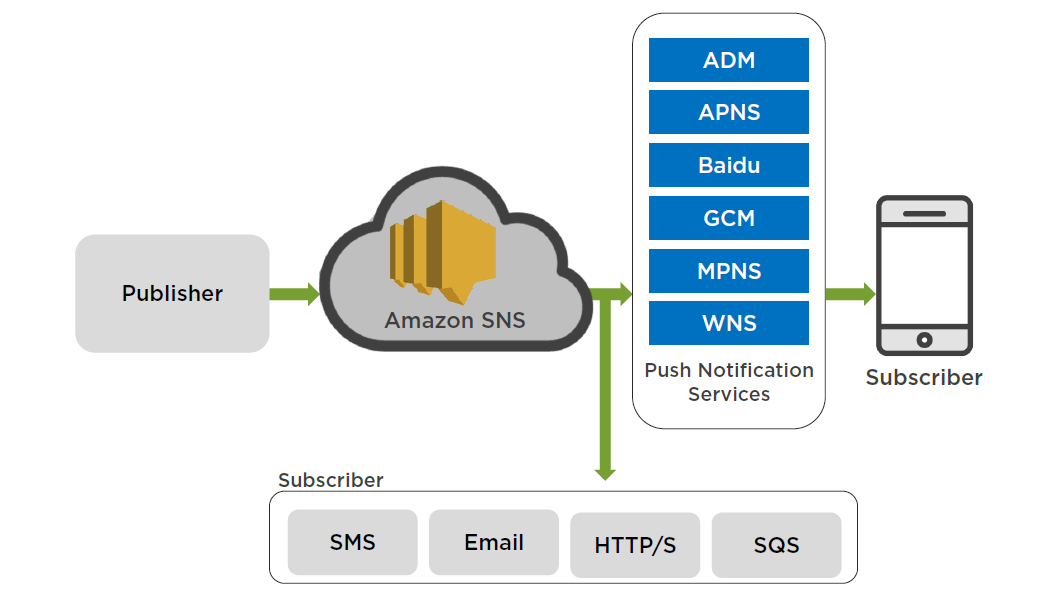
Supported Push Notification Services
Summary
- CloudFront
- Kinesis Streams
- Amazon SNS Mobile Push Notifications
Understanding AWS High Availability and BC/DR Options
Recovery Time Objective (RTO)
The time it takes after a disruption to restore a business process to its service level, as defined by the operational level agreement (OLA). For example, if a disaster occurs at 12:00 PM and the RTO is eight hours, the DR process should restore the business process to the acceptable service level by 8:00 PM.
Recovery Point Objective (RPO)
The acceptable amount of data loss measured in time. For example, if a disaster occurs at 12:00 PM and the RPO is one hour, the system should recover all data that was in the system before 11:00 AM. Data loss will span only one hour, between 11:00 AM and 12:00 PM.
Traditional DR
Different levels of off-site duplication of data and infrastructure
Critical business services are set up and maintained on this infrastructure and tested at regular intervals
DR environment’s location and the production infrastructure should be a significant physical distance apart
Traditional DR Investments
AWS for DR

AWS Services for DR
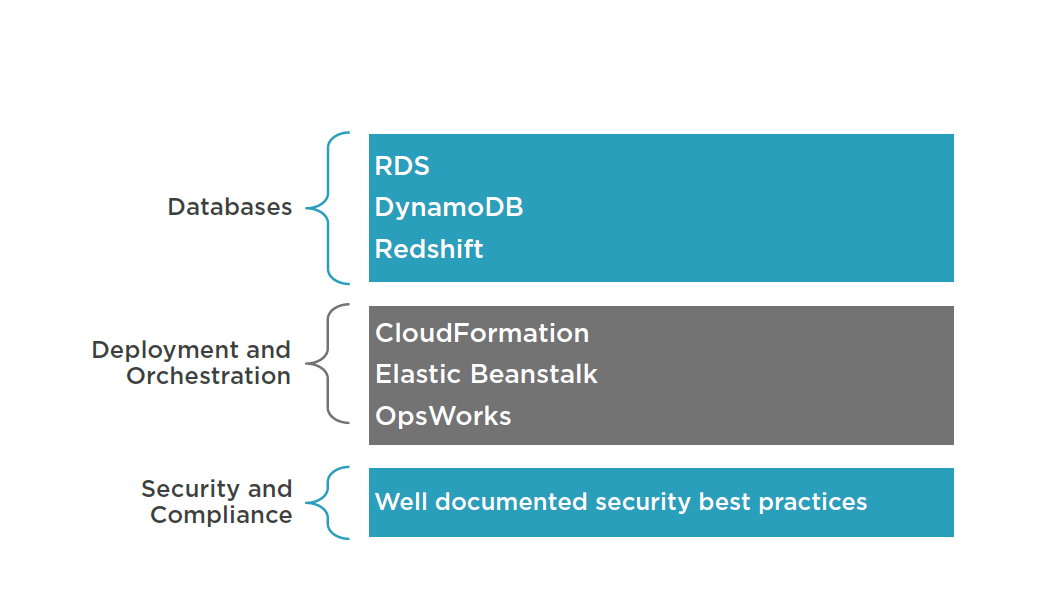
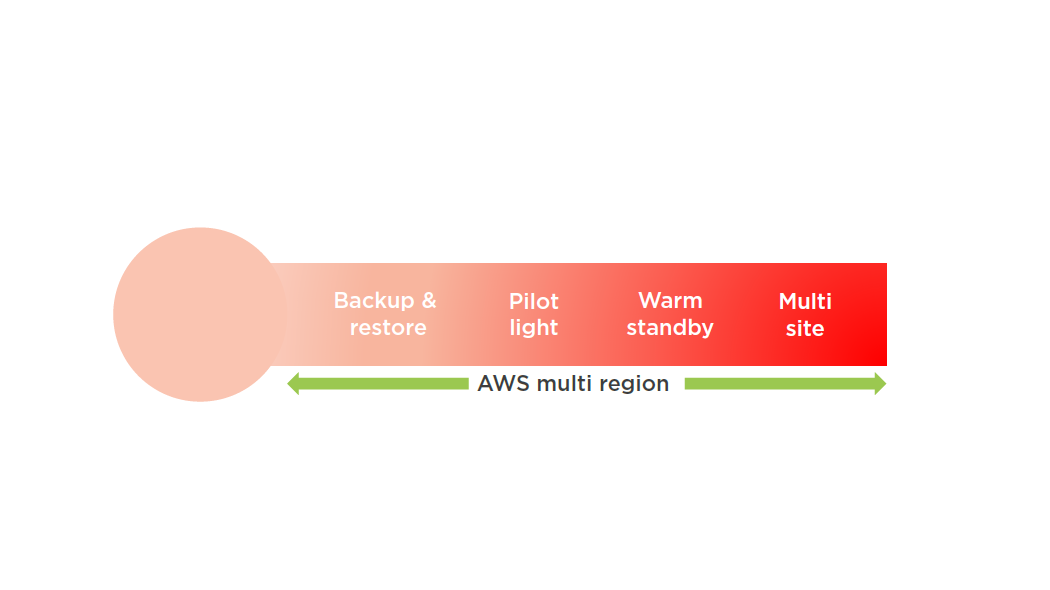
DR Scenarios
Backup and Recovery
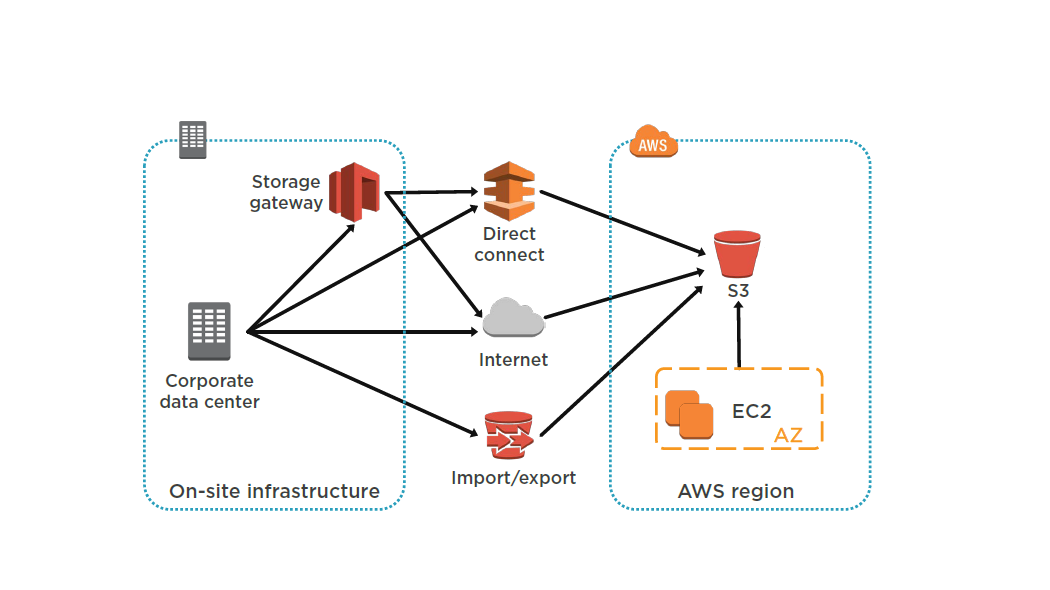
AWS Storage Gateway enables snapshots of your on-premises data volumes to be transparently copied into Amazon S3 for backup. You can subsequently create local volumes or Amazon EBS volumes from these snapshots.
Storage -cached volumes allow you to store your primary data in Amazon S3, but keep your frequently accessed data local for low-latency access. You can snapshot the data volumes for highly durable backups. In the event of DR, you can restore the cache volumes either to a second site running a storage cache gateway or to Amazon EC2.
You can use the gateway-VTL configuration as a backup target for your existing backup management software. This can be used as a replacement for traditional magnetic tape backup.
Pilot Light
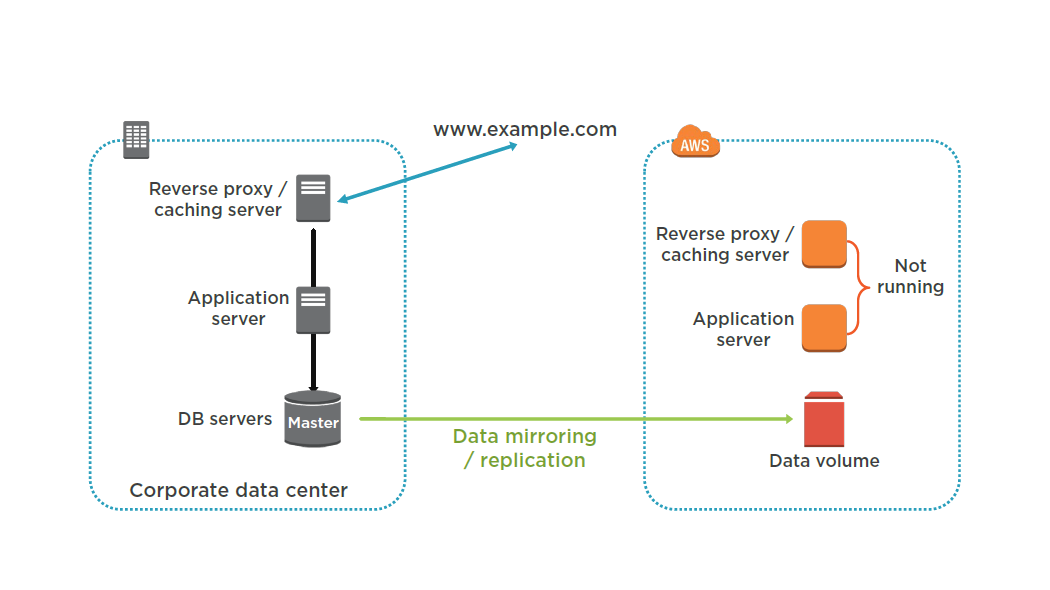
Set up Amazon EC2 instances to replicate or mirror data.
Ensure that you have all supporting custom software packages available in AWS.
Create and maintain AMIs of key servers where fast recovery is required.
Regularly run these servers, test them, and apply any software updates and configuration changes.
Consider automating the provisioning of AWS resources.
Pilot Light
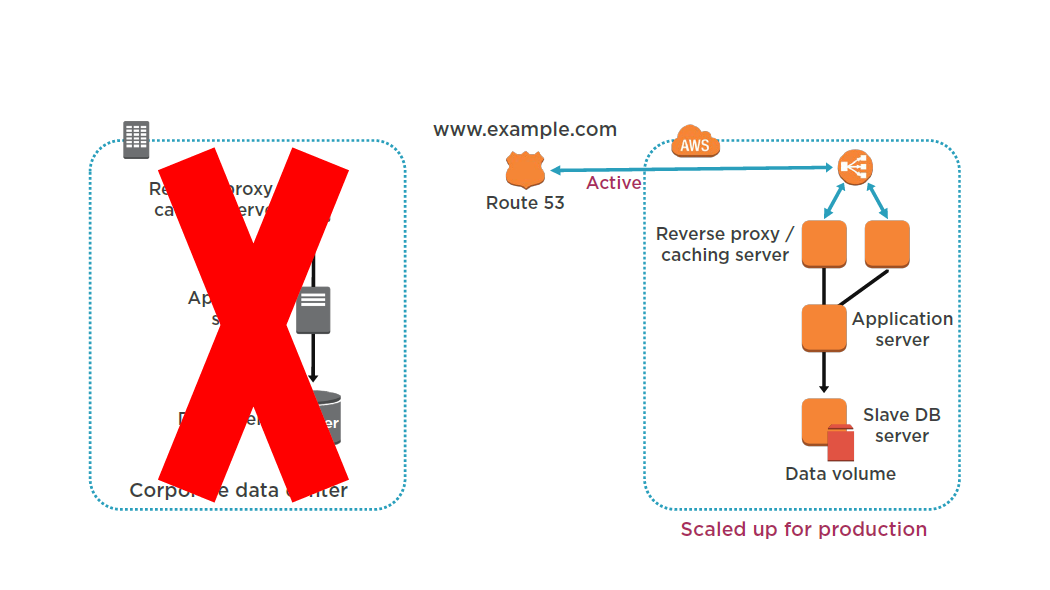
Start your application Amazon EC2 instances from your custom AMIs.
Resize existing database/data store instances to process the increased traffic.
Add additional database/data store instances to give the DR site resilience in the data tier; If you are using Amazon RDS, turn on Multi-AZ to improve resilience.
Change DNS to point at the Amazon EC2 servers.
Install and configure any non-AMI based systems, ideally in an automated way
Warm Standby
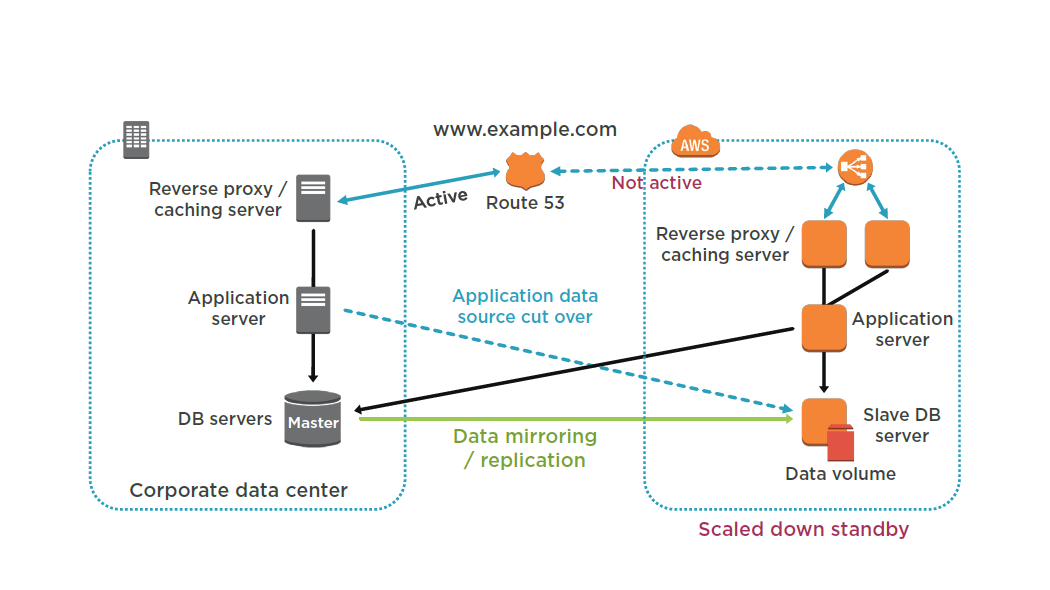
Set up Amazon EC2 instances to replicate or mirror data.
Create and maintain AMIs.
Run your application using a minimal footprint of Amazon EC2 instances or AWS infrastructure.
Patch and update software and configuration files in line with your live environment.
Warm Standby
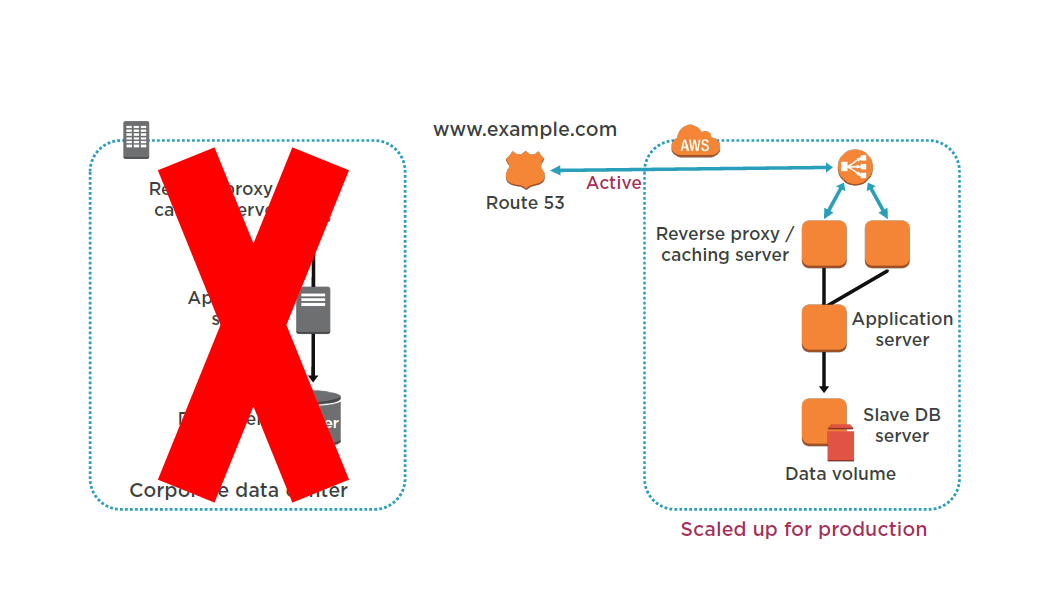
Increase the size of the Amazon EC2 fleets in service with the load balancer (horizontal scaling).
Start applications on larger Amazon EC2 instance types as needed (vertical scaling).
Either manually change the DNS records, or use Amazon Route 53 automated health checks so that all traffic is routed to the AWS environment.
Consider using Auto Scaling to right-size the fleet or accommodate the increased load.
Add resilience or scale up your database.
Multi Site
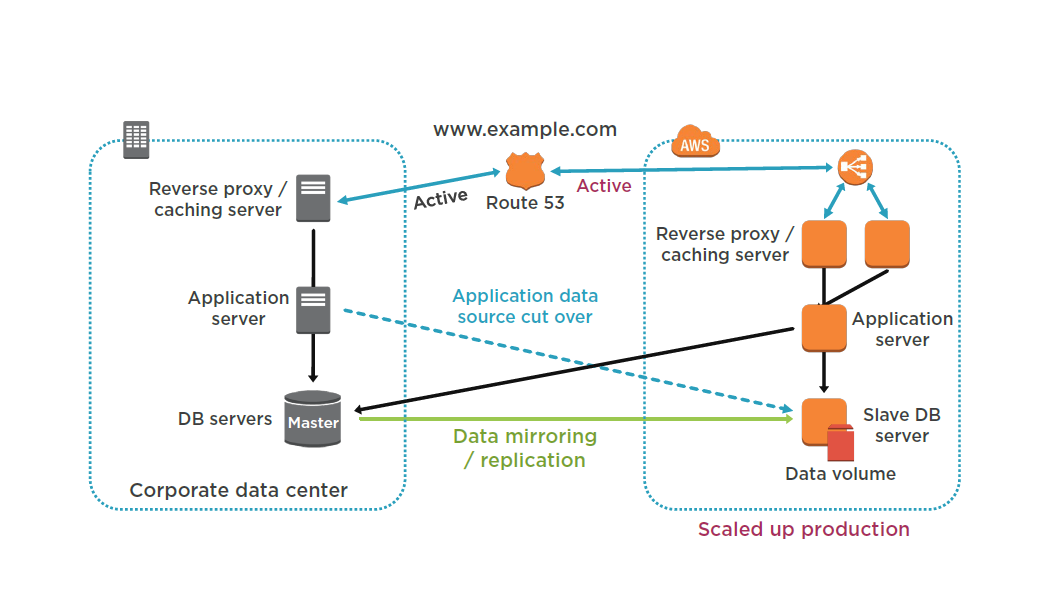
Set up your AWS environment to duplicate your production environment.
Set up DNS weighting, or similar traffic routing technology to distribute incoming requests to both sites.
Configure automated failover to re-route traffic away from the affected site
Multi Site
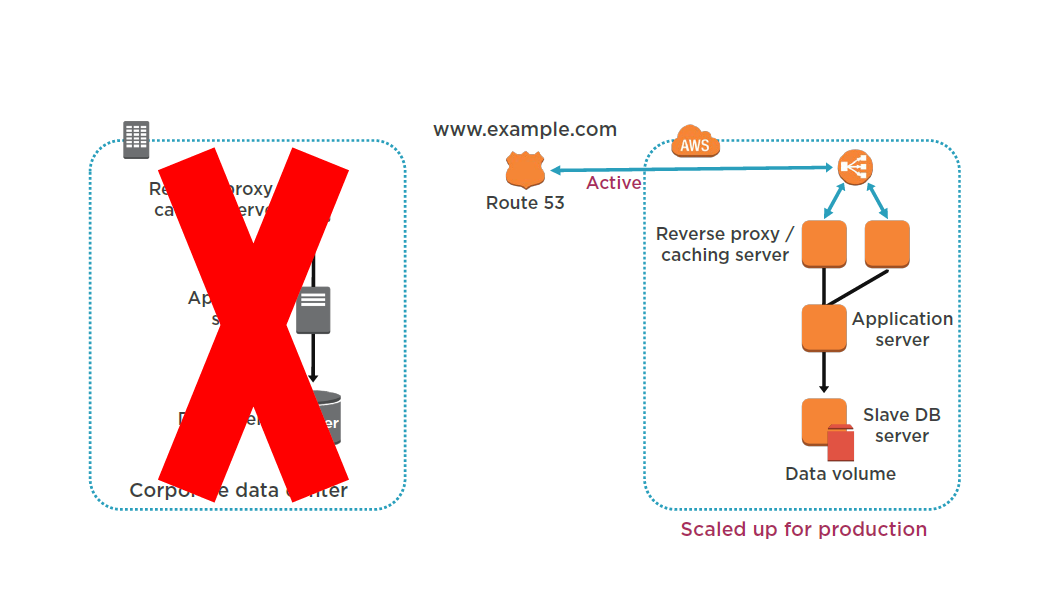
Either manually or by using DNS failover, change the DNS weighting so that all requests are sent to the AWS site.
Have application logic for failover to use the local AWS database servers for all queries.
Consider using Auto Scaling to automatically right-size the AWS fleet.
Suggested Reading
Using Amazon Web Services for Disaster Recovery:
http://d36cz9buwru1tt.cloudfront.net/AWS_Disaster_Recovery.pdf
Import/Export
Low bandwidth
Large data sets
Can be used to import to:
- S3
- Glacier
- EBS
Can only export from:
- S3
If bucket versioning is enabled, only most recent version will be exported
Encryption, Wiping & Destructing
- Encryption is optional when sending data
- By default AWS will encrypt all data it
- exports using TrueCrypt
- AWS will wipe the device after downloading the data
- AWS will not destroy the device
HA for Databases
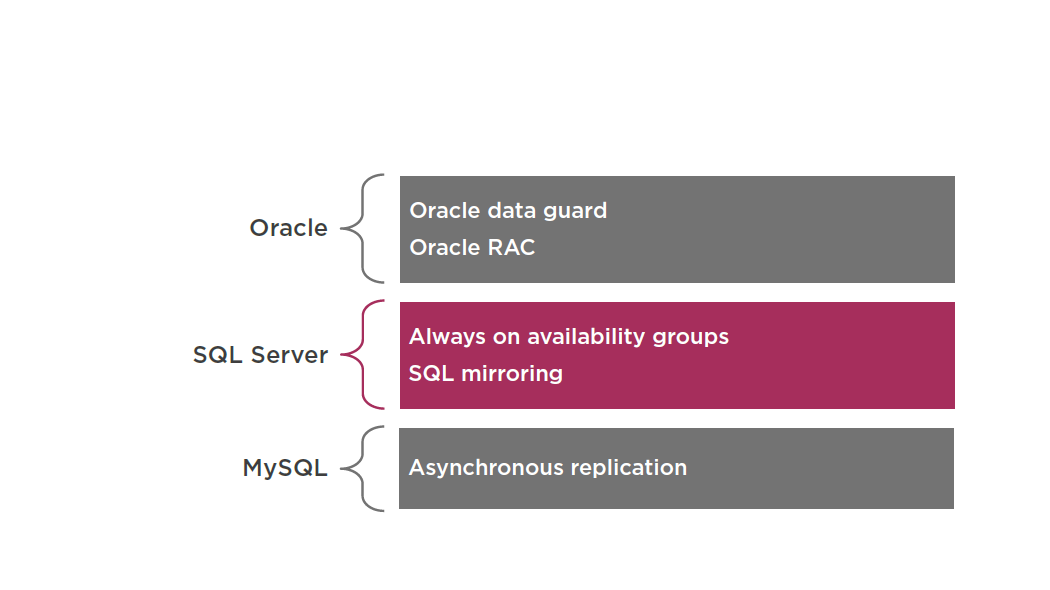
Automatic RDS Multi-AZ Failover

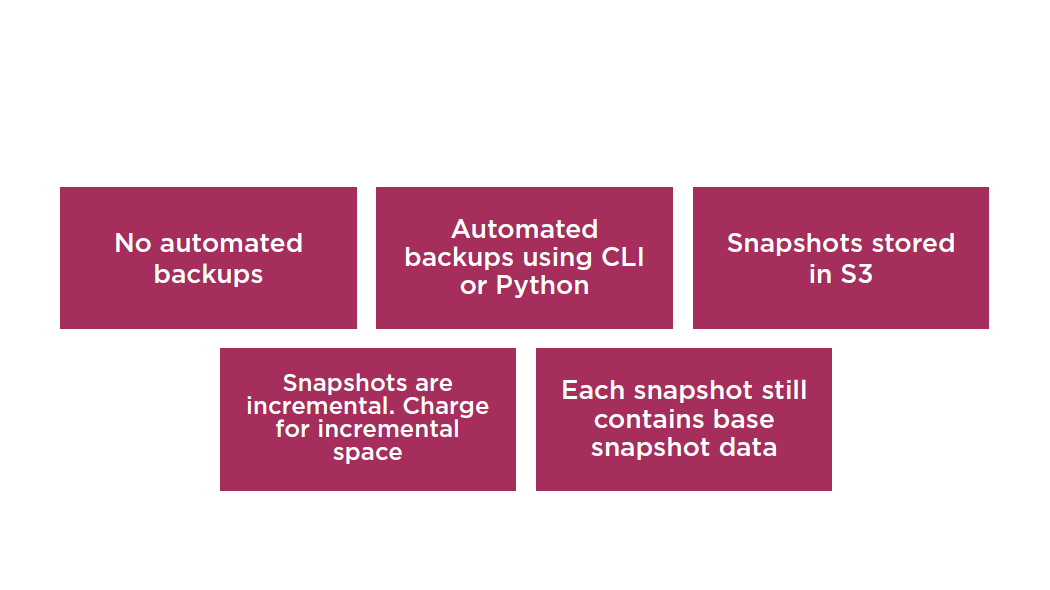
Automated Backups

RDS Automated Backups
- All backups stored on S3
- MySQL DB engine, only the InnoDBstorage engine is supported
- MariaDB DB engine, only the XtraDBstorage engine is supported
- Deleting a DB instances deletes all automated backups
- Manual snapshots are not deleted
- RDS uses a default retention period of one day
- Values are 0 (for no backup retention) to a maximum of 35 days
- Manual snapshot limits (50 per region) do not apply to automated backups
- Restore allows you to change the engine type (SQL Standard to SQL Enterprise)
EC2 Backup Overview
Summary
- DR with AWS
- Import/export
- Automated backups
Understanding AWS Data Pipeline and Integration with VMware
AWS Data Pipeline
A web service that helps you reliably process and move data between different AWS compute and storage services, as well as on-premises data sources, at specified intervals.
Create, access, and manage using:
- AWS Management Console
- CLI
- SDKs
- Query API
Supported compute services:
- EC2
- EMR
Supported services to store data:
- DynamoDB
- RDS
- Redshift
Key Concepts
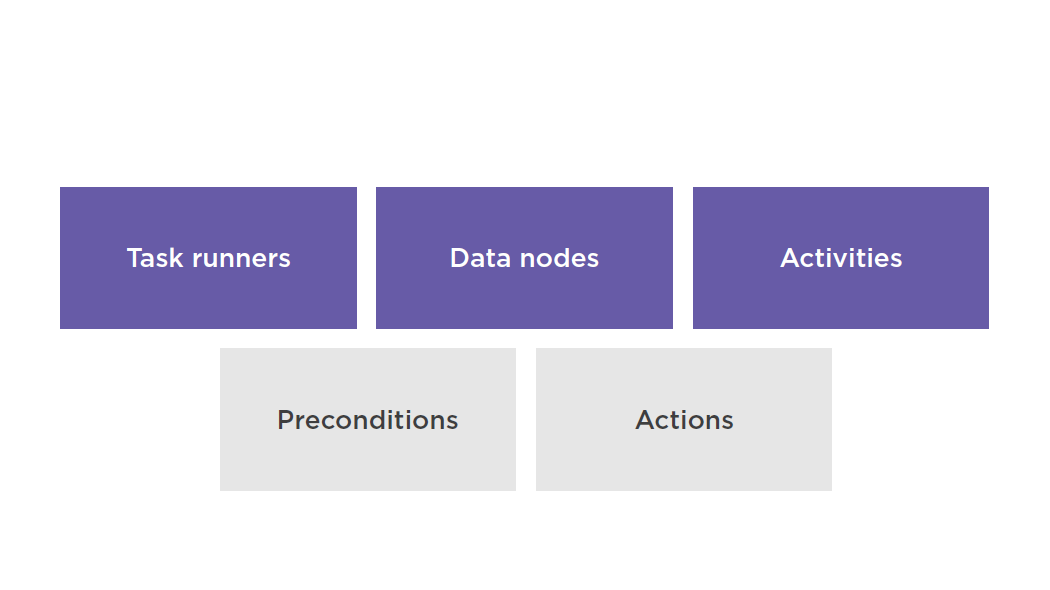
Task Runner

Data Nodes
Define the location and type of data that a pipeline activity uses as input or output
For example:
- A DynamoDB table that contains data for HiveActivityor EmrActivityto use
- A MySQL table and database query that represents data for a pipeline activity to use
- An Amazon Redshift table that contains data for RedshiftCopyActivityto use
- An Amazon S3 location that contains one or more files for a pipeline activity to use
Activities
A pipeline component that defines the work to perform
AWS Data Pipeline provides pre-packaged activities such as moving data from one location to another or running Hive queries
Custom scripts support endless combinations
Supported Activities Types
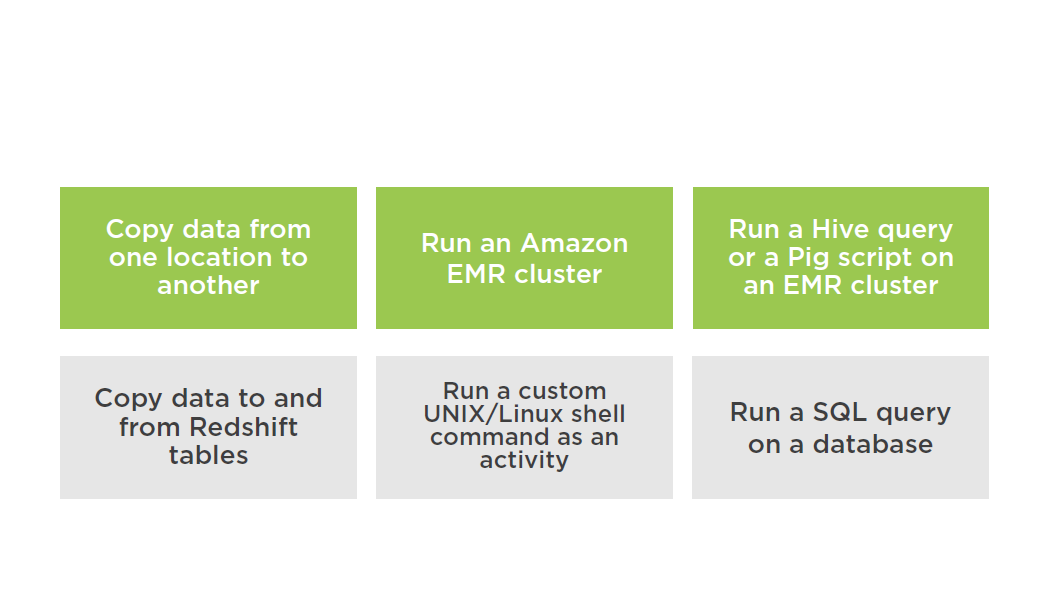
Preconditions
Pipeline component containing conditional statements that must be true before an activity can run
Support for Pre-packaged preconditions and custom scripts
Two types of preconditions:
- System-managed preconditions
- User-managed preconditions
Actions
Steps that a pipeline component takes when certain events occur, such as success, failure, or late activities
Following actions are supported:
- An action that sends an Amazon SNS notification to a topic based on certain events
- An action that triggers the cancellation of a pending or unfinished activity, resource, or data node
AWS Data Pipeline relies on Amazon SNS notifications as the primary way to indicate the status of pipelines and their components
Scheduling Pipelines
A schedule defines the timing of a scheduled event, such as when an activity runs. AWS Data Pipeline exposes this functionality through the Schedule pipeline component.
Integration with VMware
- AWS Management Portal for vCenter enables you to manage your AWS resources using VMware vCenter
- Installs as a vCenter plug-in
- Migrate VMware VMs to Amazon EC2
- Manage AWS resources from within vCenter
Use Cases

Summary
- AWS Data pipeline
- Integration with VMware
Questions

