Introduction of Monitoring & Observability
by DevOpsSchool.com
Rajesh Kumar
(Senior DevOps Manager & Principal Architect)

-
DevOps@RajeshKumar.xyz
www.rajeshkumar.xyz
/RajeshKumarLog
/RajeshKumarIN
/RajeshKumarIN
Rajesh Kumar — an award-winning academician and consultant trainer, with 15+ years’ experience in diverse skill management, who has more than a decade of experience in training large and diverse groups across multiple industry sectors.
Monitoring
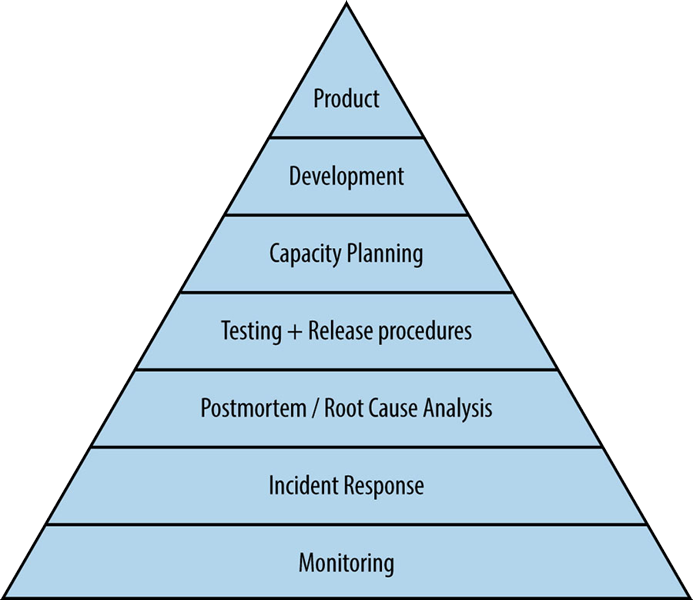
Monitoring is the most basic component in their reliability pyramid and enables incident response and postmortems.

"Monitoring tells you whether a systems is working, observability lets you ask why it isn't working."
Observability means assembling all fragments from logs, monitoring tools and
organize them in such a way which gives actionable knowledge of the whole
enviroment, thus creating an insight.
Taken from Article, Observability Working Architecture and Benifits
Monitoring and Observability
Once upon a time there was “Monitoring”
Observability is a superset of monitoring. It provides not only high-level overviews of the system’s health but also highly granular insights into the implicit failure modes of the system.
In addition, an observable system furnishes ample context about its inner workings, unlocking the ability to uncover deeper, systemic issues.
Monitoring, on the other hand, is best suited to report the overall health of systems and to derive alerts.
Observability
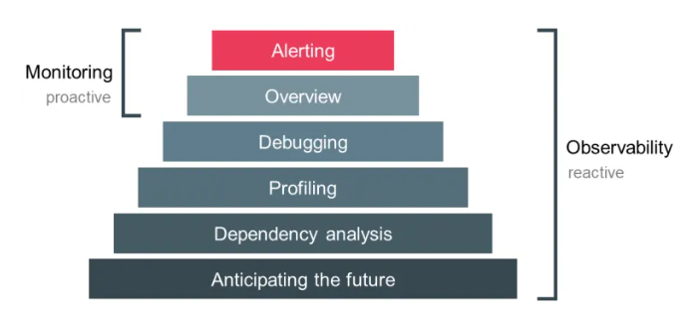
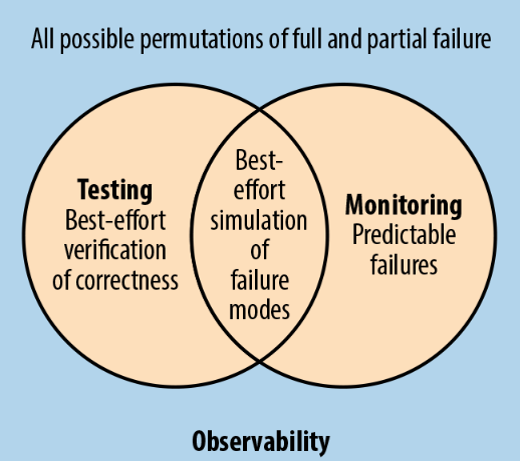

The Observability Hierarchy
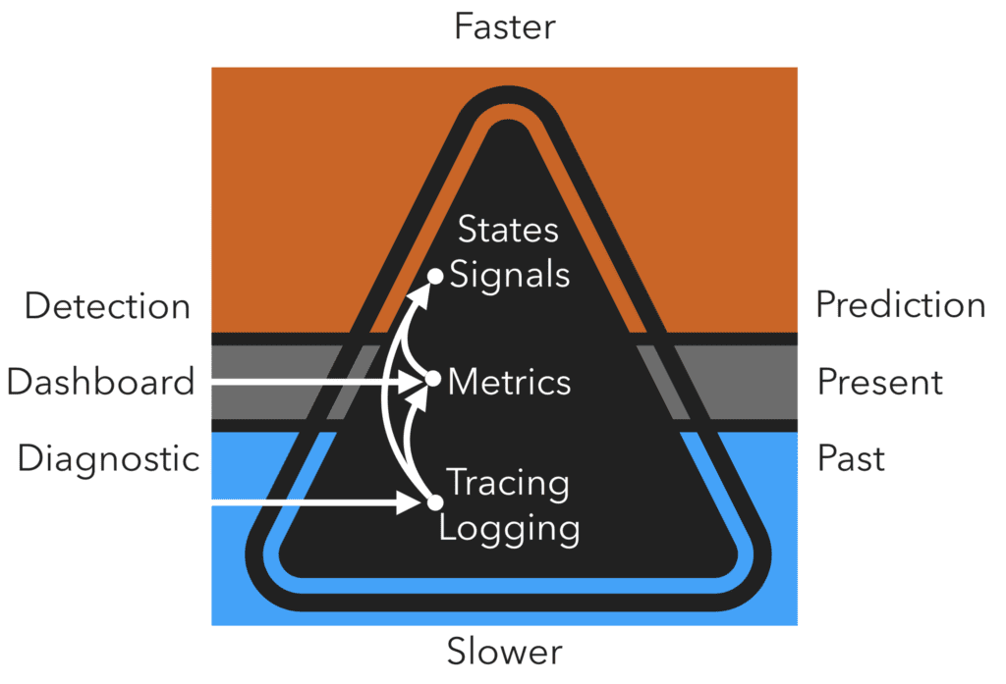
Telemetry
Telemetry is the collection of measurements or other data at remote points and their automatic transmission to receiving equipment for monitoring. The word is derived from the Greek roots tele, "remote", and metron, "measure".
MELT
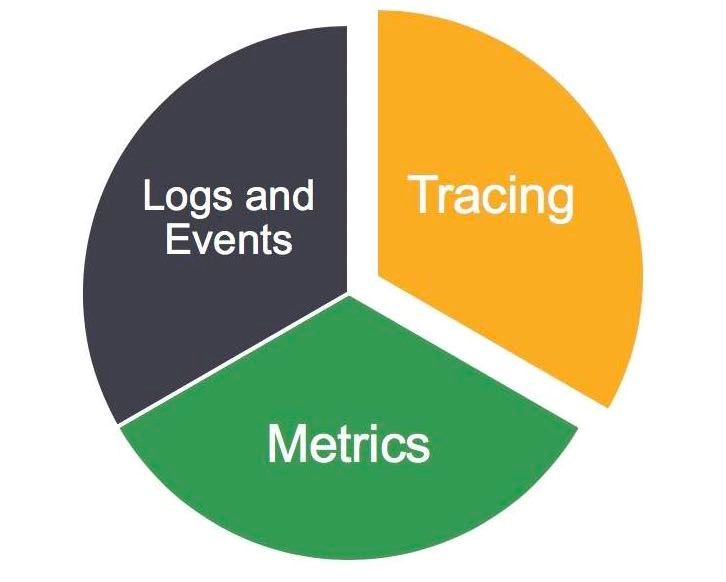
Four essential telemetry data types
- Metrics
- Events
- Logs
- Traces
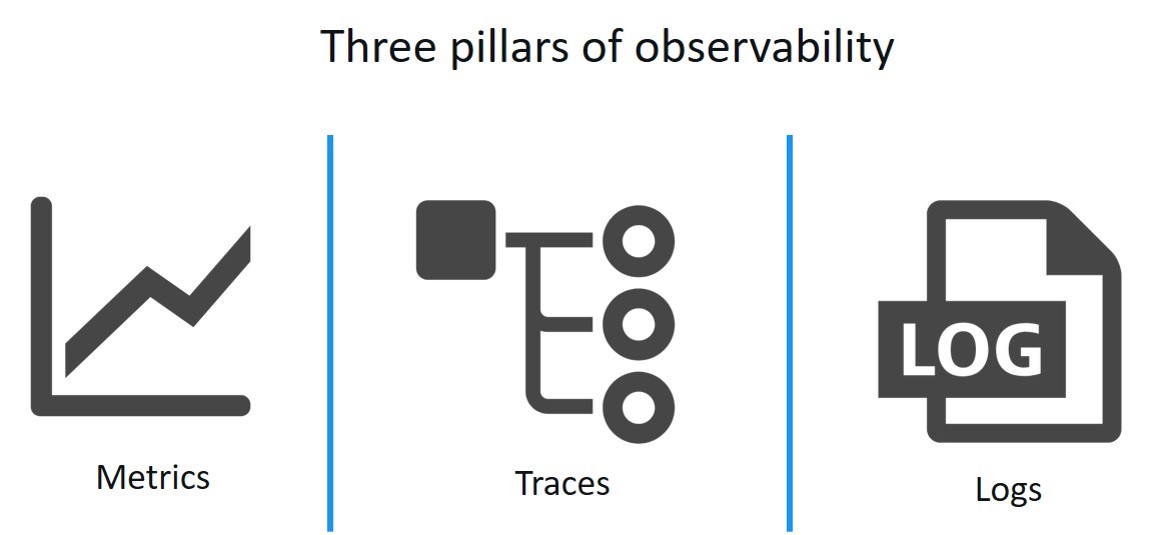
How to achieve Observability?
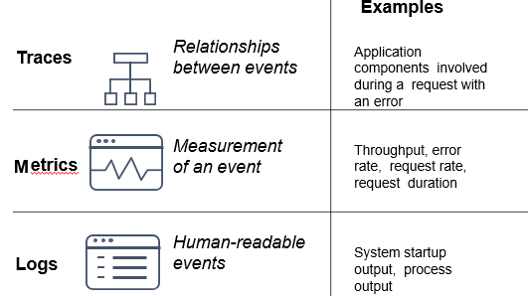

These are the types of data that a system should produce to be observable.
- Health checks: they are often custom HTTP endpoints, help orchestrators, like Kubernetes or Cloud Foundry, they are performed to maintain the excellent health of the system.
- Metrics: they are a numeric representation of data that is collected at regular intervals into a time series. The Numerical time series data is straightforward to store and can query quickly; it helps when looking for historical trends.
- Log entries: they represent discrete events. The Log entries are essential for debugging, as they often include stack traces and other contextual information that can help identify the root cause of observed failures.
- Distributed, request or end-to-end tracing: they capture the end-to-end flow of an application through the system. Tracing essentially captures both relationships between services (the services the request touched), and the structure of work through the system (synchronous or asynchronous processing, child-of or follows-from relations).
What is Metrics?
Metrics represent the data in your system, monitoring is the process of collecting, aggregating, and analyzing those values to improve awareness of your components' characteristics and behavior.
Metrics capture a value pertaining to your systems at a specific point in time — for example, the number of users currently logged in to a web application. Therefore, metrics are usually collected once per second, one per minute, or at another regular interval to monitor a system over time.
What is Metrics?
There are two important categories of metrics in our framework: work metrics and resource metrics.

Work Metrics
Work metrics indicate the top-level health of your system by measuring its useful output. It’s often helpful to break them down into four subtypes:
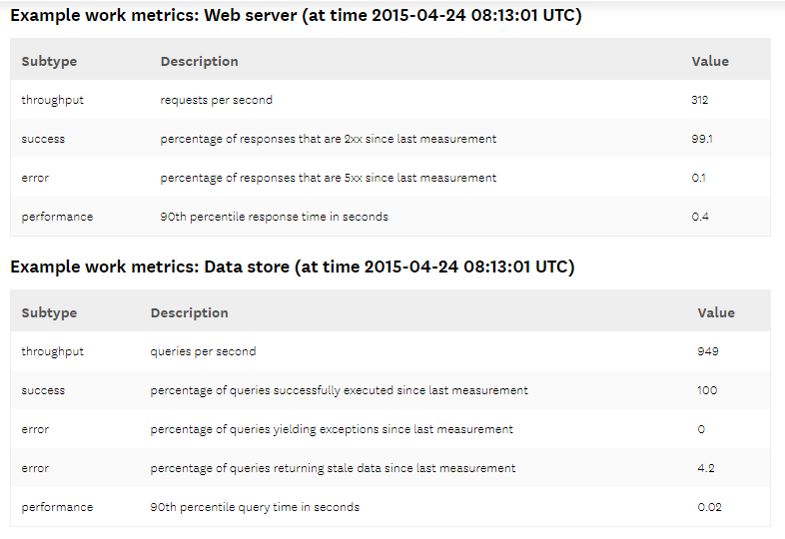
- throughput is the amount of work the system is doing per unit time. Throughput is usually recorded as an absolute number.
- success metrics represent the percentage of work that was executed successfully.
- error metrics capture the number of erroneous results, usually expressed as a rate of errors per unit time or normalized by the throughput to yield errors per unit of work. Error metrics are often captured separately from success metrics when there are several potential sources of error, some of which are more serious or actionable than others.
- performance metrics quantify how efficiently a component is doing its work. The most common performance metric is latency, which represents the time required to complete a unit of work. Latency can be expressed as an average or as a percentile, such as “99% of requests returned within 0.1s”.
Example of
Work Metrics
Resources Metrics
A server’s resources include such physical components as CPU, memory, disks, and network interfaces. Including a database or a geolocation microservice, can also be considered a resource if another system requires that component to produce work. For each resource in your system, try to collect metrics that cover four key areas:
- utilization is the percentage of time that the resource is busy, or the percentage of the resource’s capacity that is in use.
- saturation is a measure of the amount of requested work that the resource cannot yet service, often queued.
- errors represent internal errors that may not be observable in the work the resource produces.
- availability represents the percentage of time that the resource responded to requests. This metric is only well-defined for resources that can be actively and regularly checked for availability.
Resources Metrics Example

Events
In addition to metrics, which are collected more or less continuously, some monitoring systems can also capture events: discrete, infrequent occurrences that can provide crucial context for understanding what changed in your system’s behavior. Some examples:
- Changes: Internal code releases, builds, and build failures
- Alerts: Internally generated alerts or third-party notifications
- Scaling events: Adding or subtracting hosts
An event usually carries enough information that it can be interpreted on its own. Events capture what happened, at a point in time, with optional additional information.
Events Example
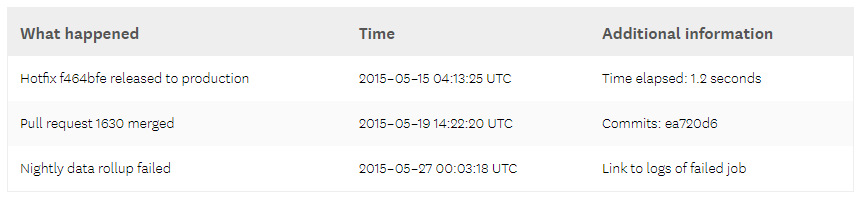
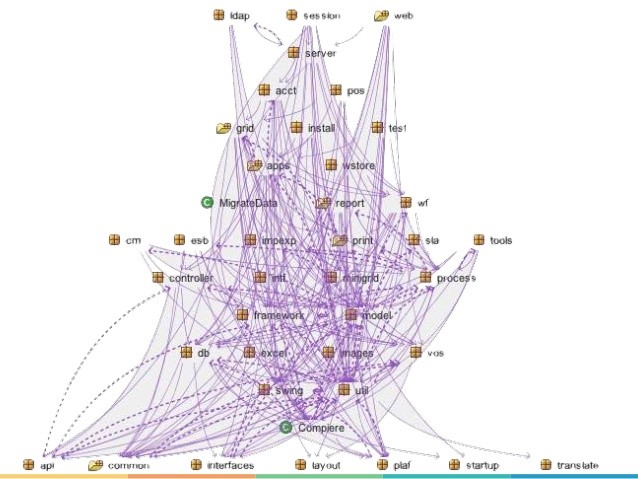
Why is Observability hard?
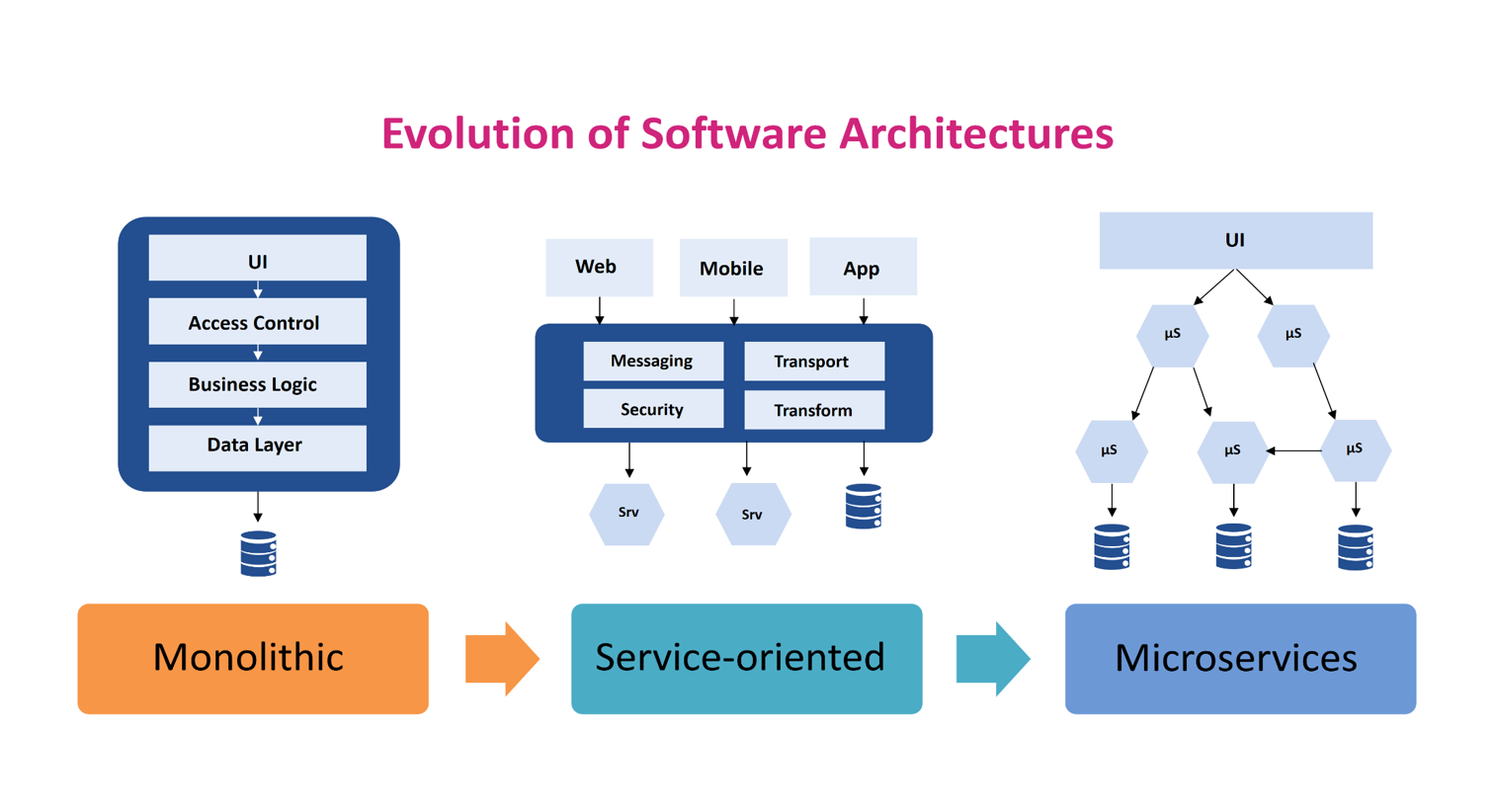
Service Oriented Architecture
SOA
Architecture Diagram
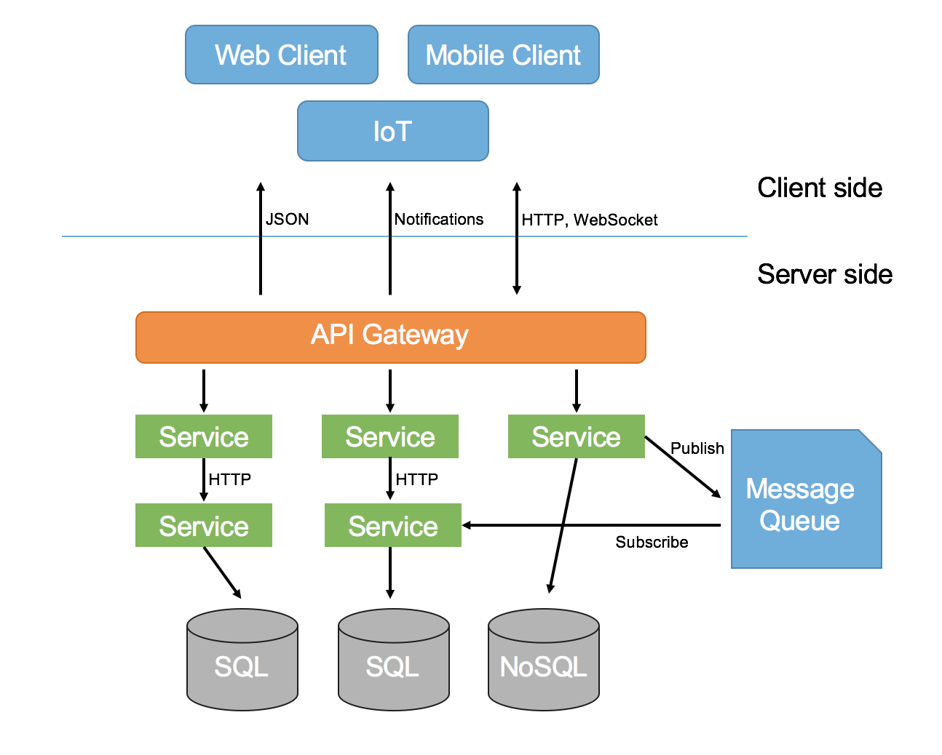
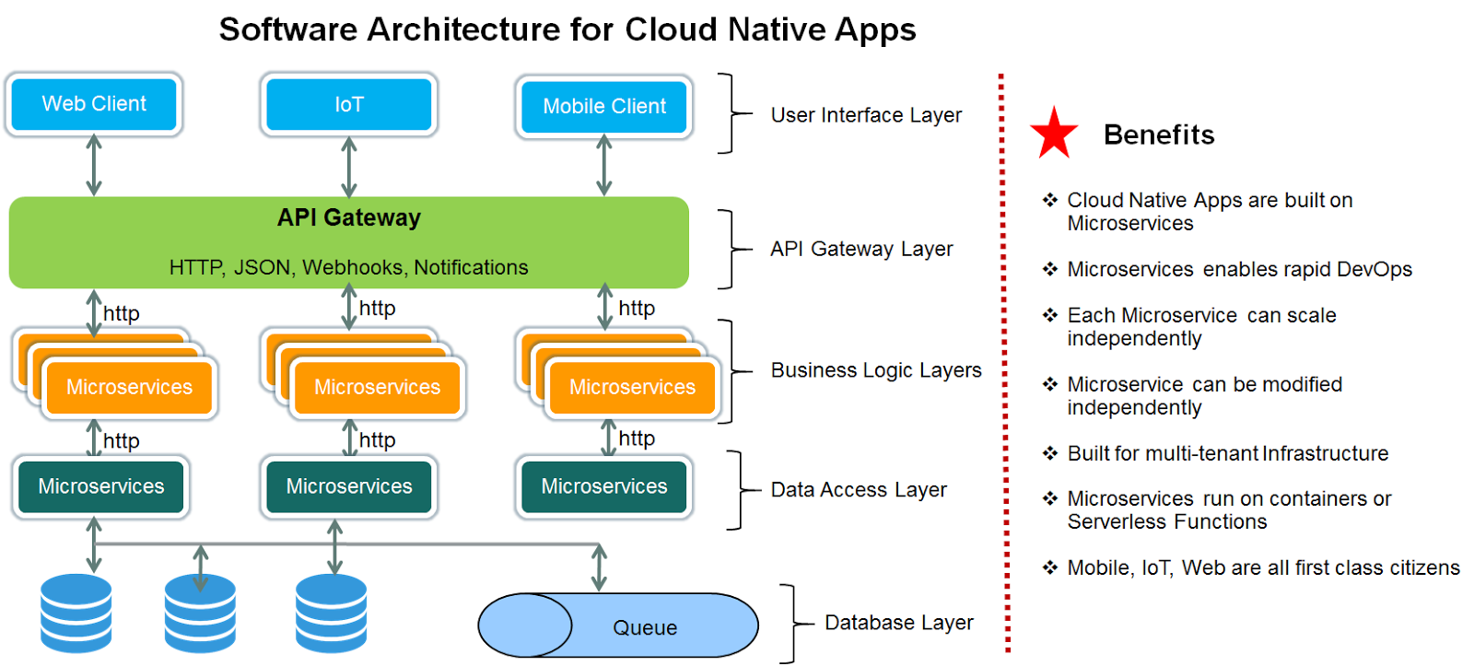
Too many
Micro services!!!!
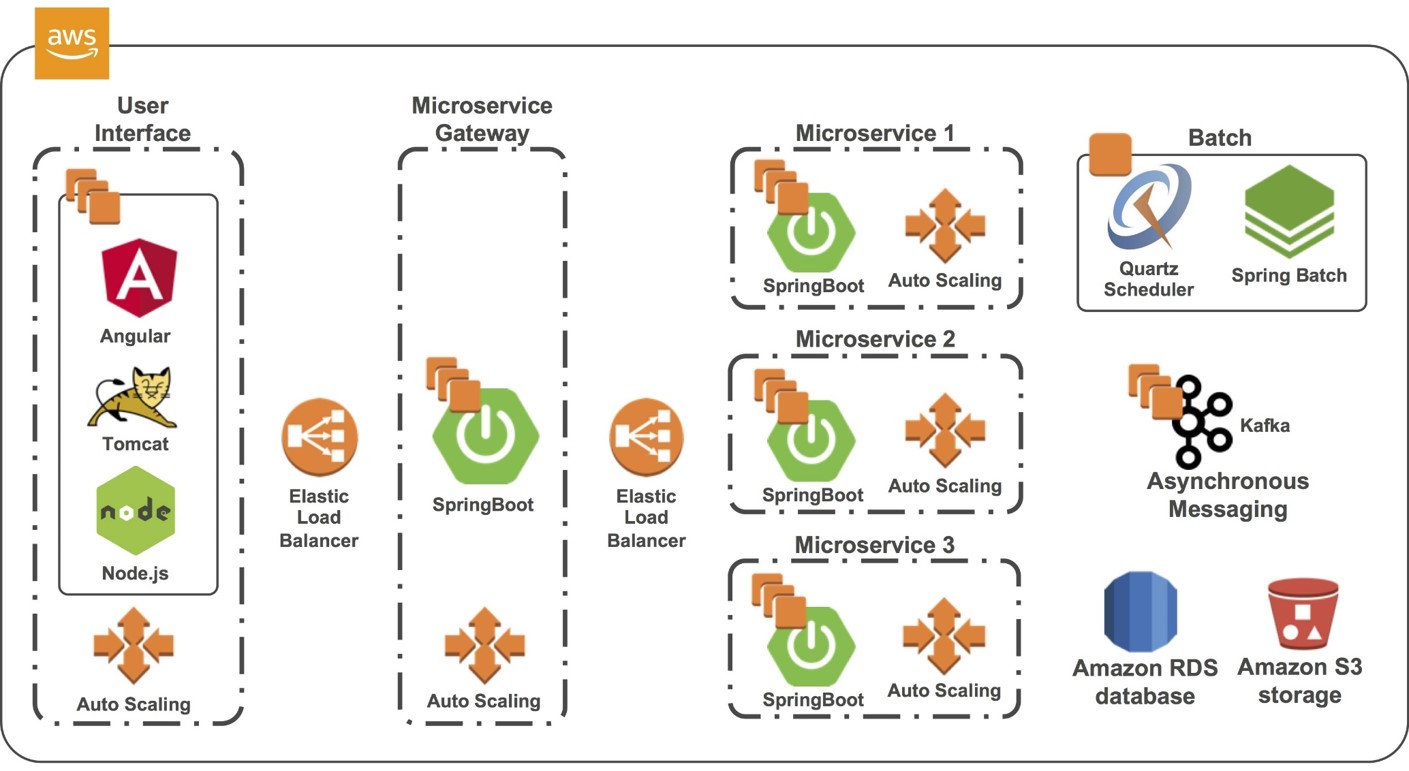
DevOpsSchool Community Networks
These platforms provide you the opportunity to connect with peers and industry DevOps leaders, where you can share, discuss or get information on latest topics or happenings in DevOps culture and grow your DevOps professionals network.
 |
|---|
| DevOps |
| Build & Release |
 |
|---|
| DevOps |
| Build & Release |
 |
|---|
| DevOpsSchool |
| DevOps Group |
 |
|---|
| BestDevOps.com |

Any Questions?

Thank You!
DevOpsSchool — Lets Learn, Share & Practice DevOps
Connect with us on
contact@devopsschool.com | +91 700 483 5930Next up:

Datadog Course
2. Datadog Infrastructure Monitoring