Site Reliability Engineering (SRE): The Big Picture
INTRODUCING SITE RELIABILITY ENGINEERING
by DevOpsSchool.com
Rajesh Kumar
(Senior DevOps Manager & Principal Architect)

-
DevOps@RajeshKumar.xyz
www.rajeshkumar.xyz
/RajeshKumarLog
/RajeshKumarIN
/RajeshKumarIN
Rajesh Kumar — an award-winning academician and consultant trainer, with 15+ years’ experience in diverse skill management, who has more than a decade of experience in training large and diverse groups across multiple industry sectors.
What is SRE?
An approach to operations which uses software as the primary tool for managing systems

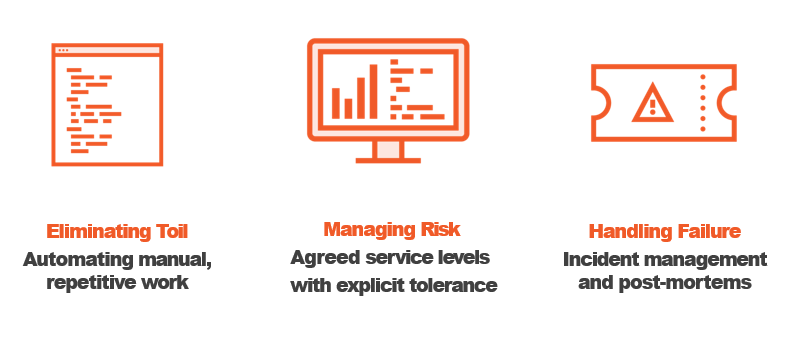
Functions of Site Reliability Engineering
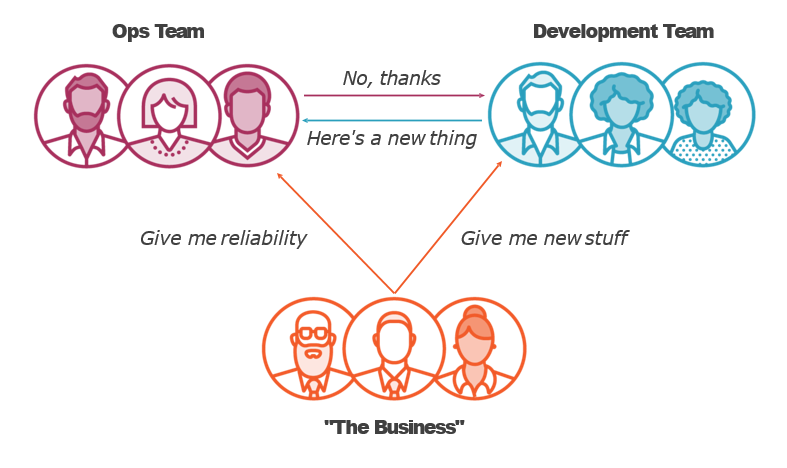
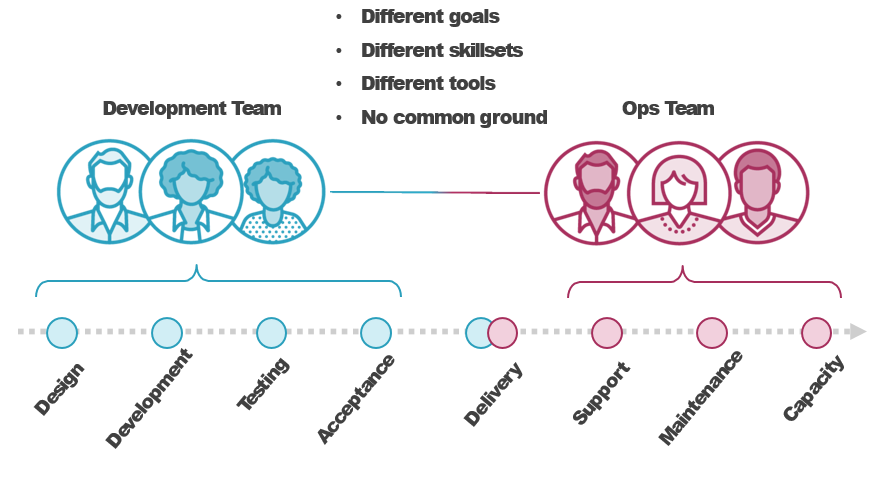
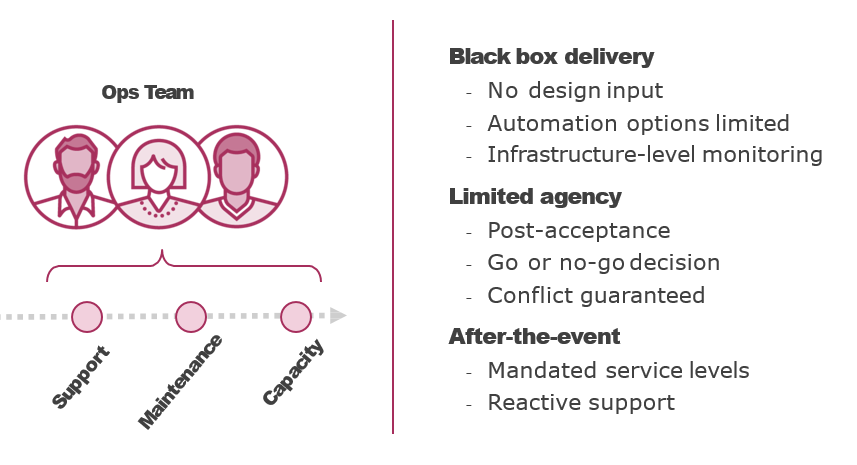
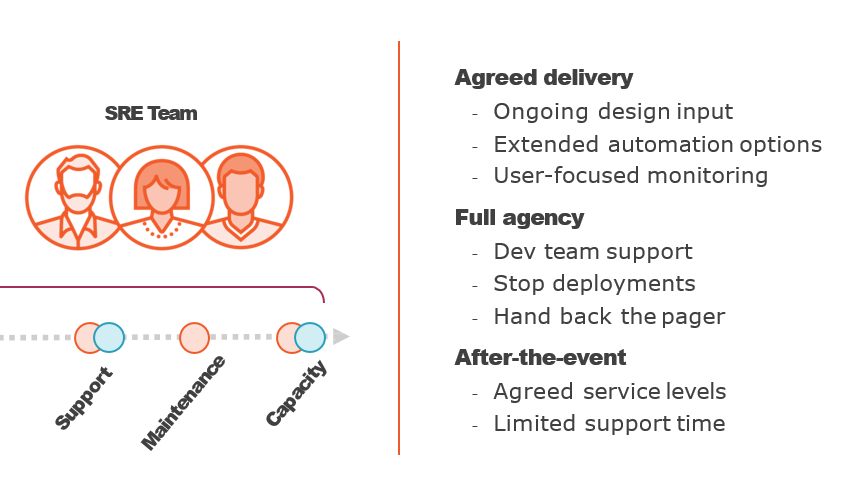
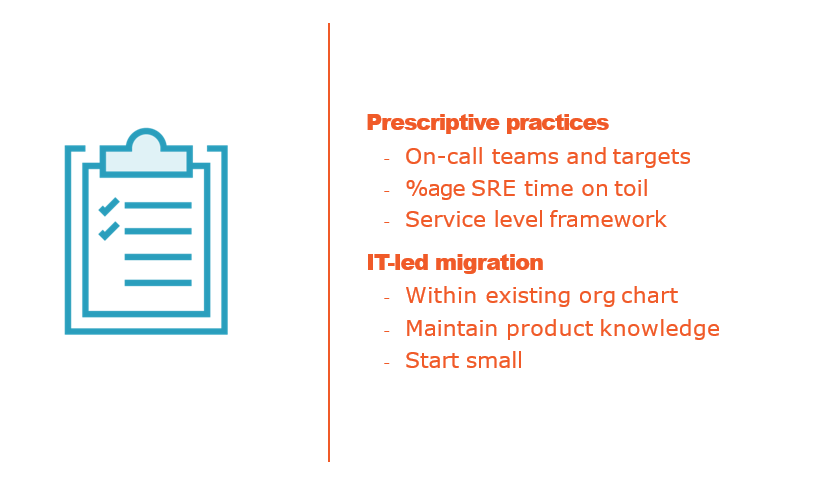
Comparing Traditional Ops and SRE
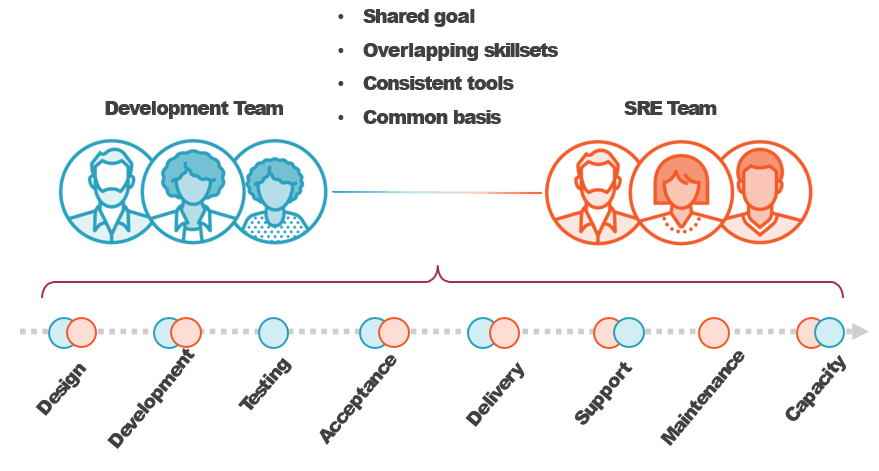
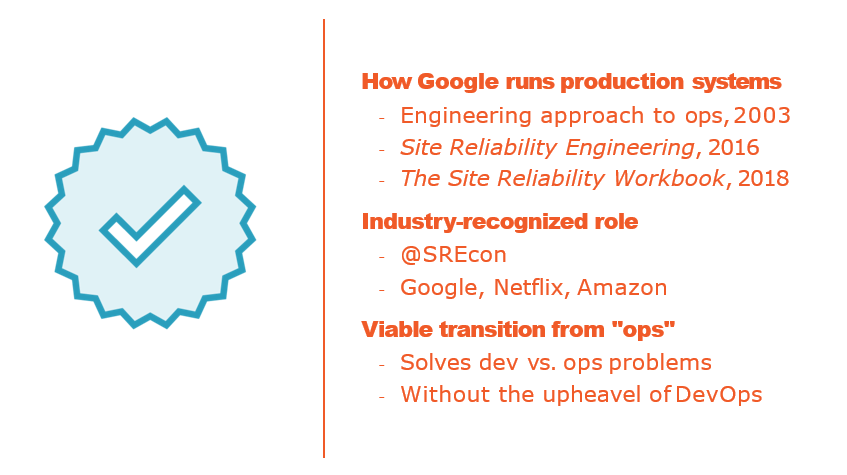
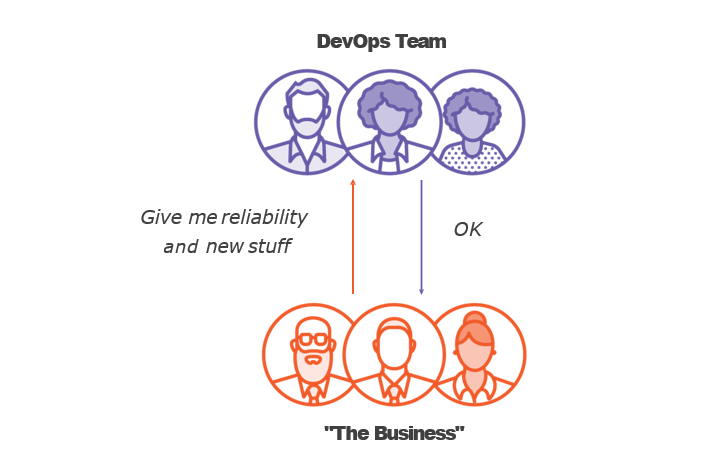
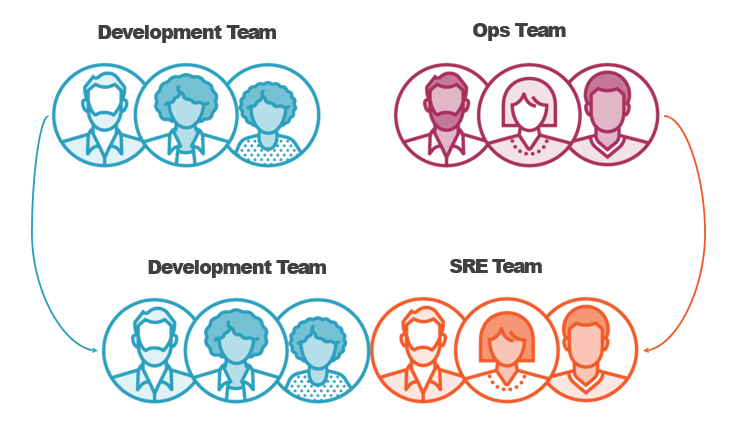
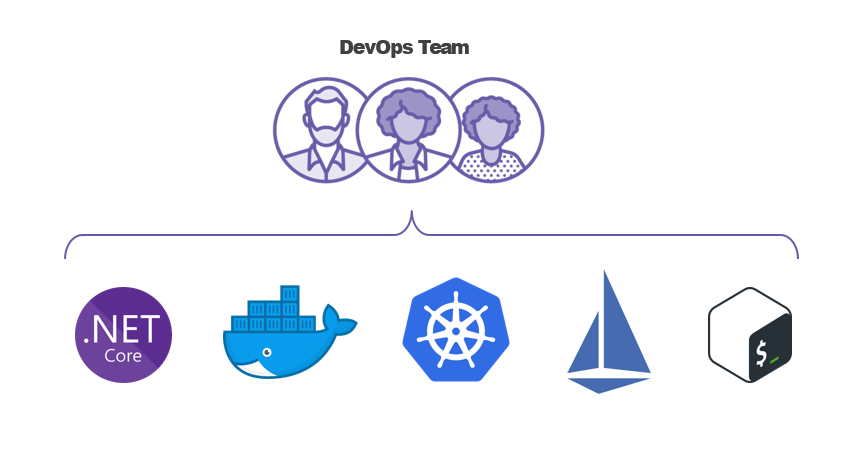
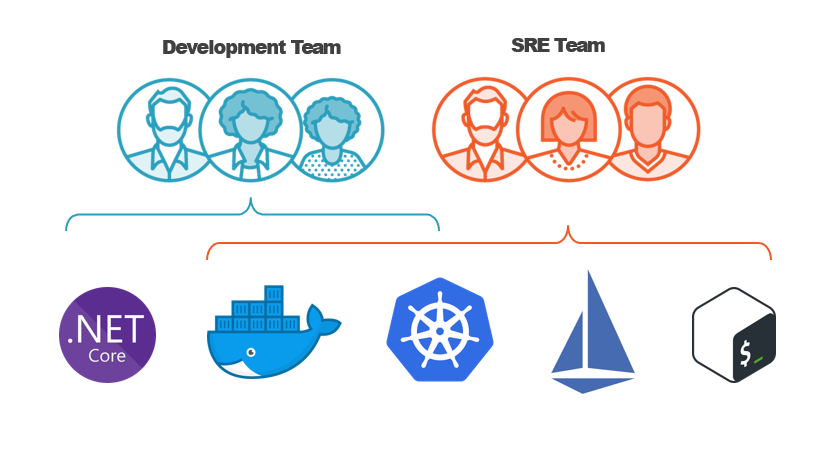
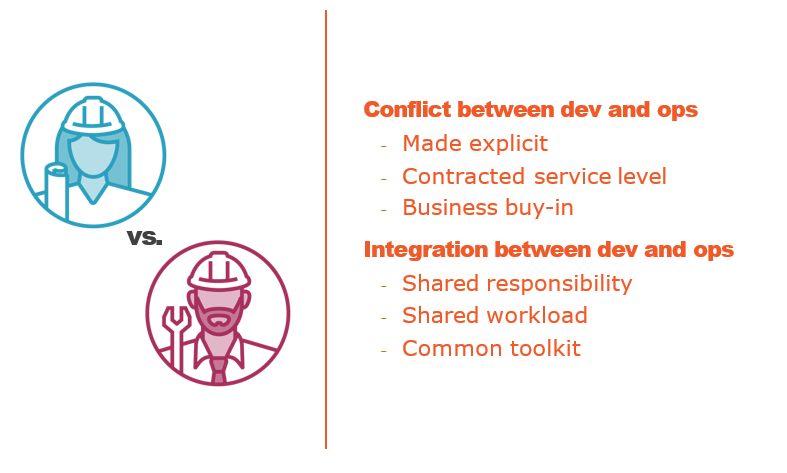
Comparing DevOps and SRE
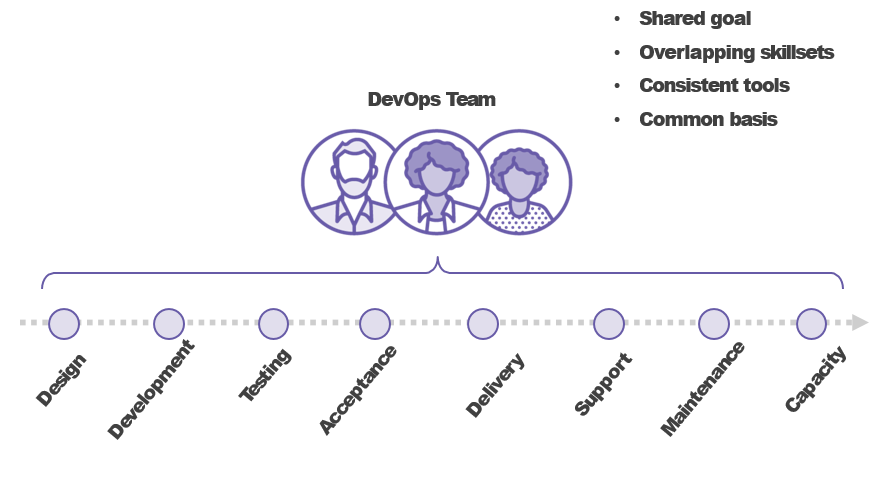
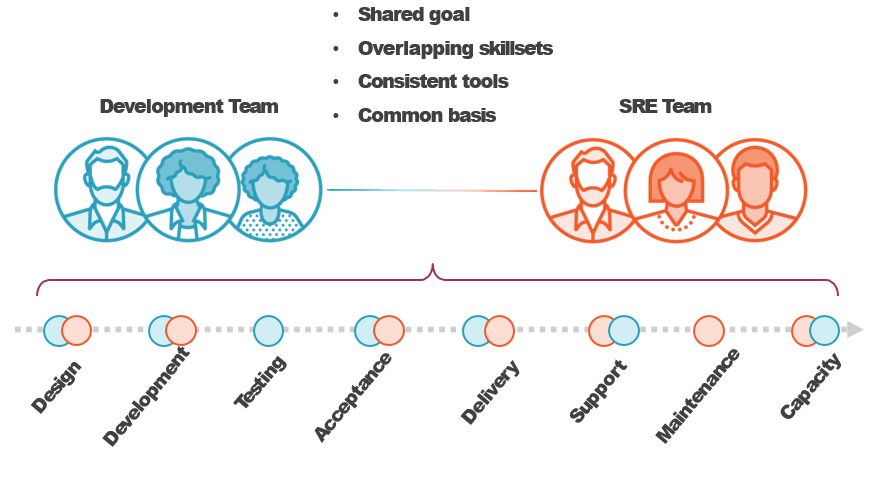
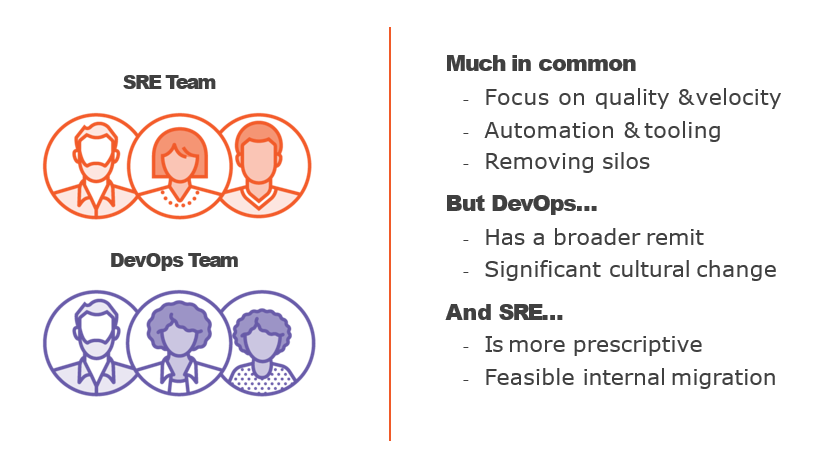
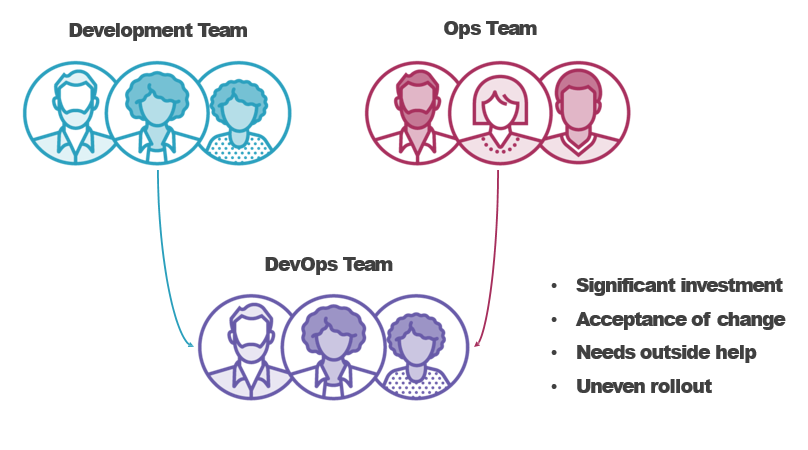
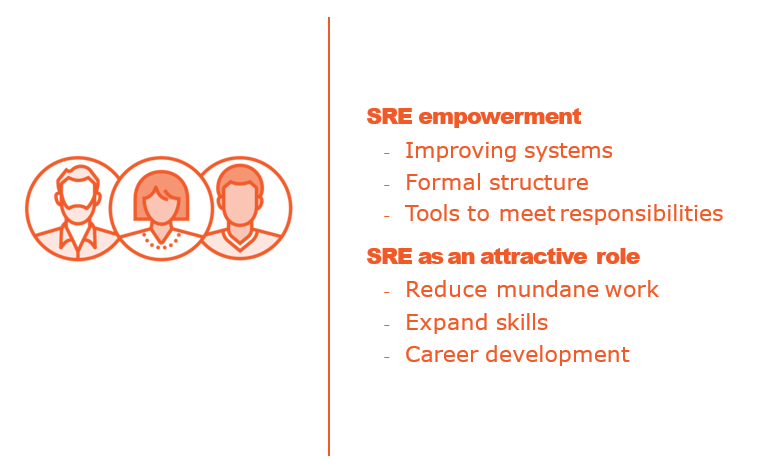
Exploring the Key Tenets of SRE

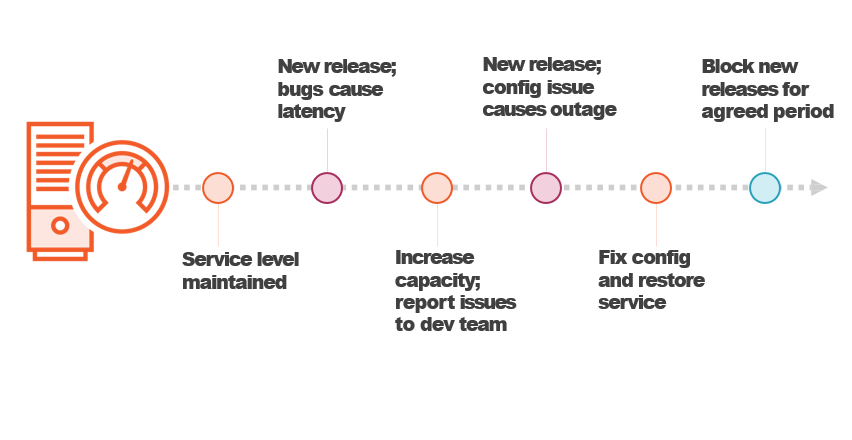
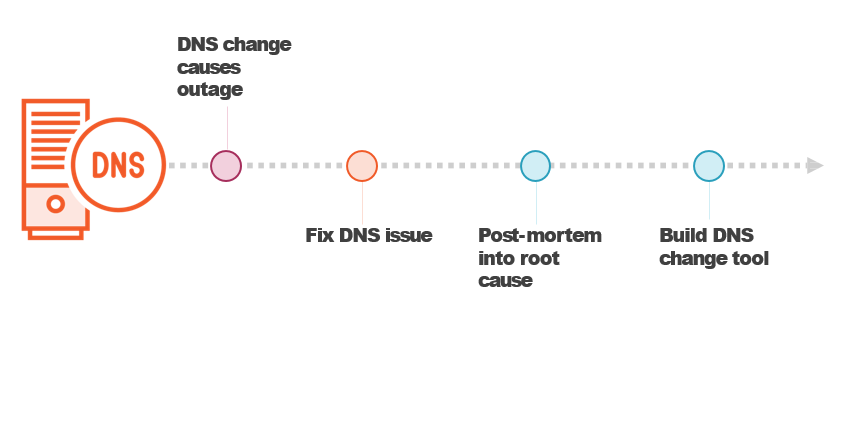
Understanding Why SRE Works
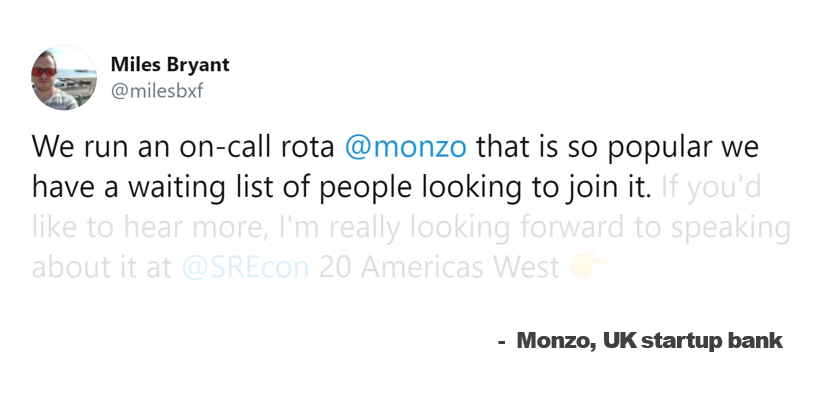
“It's what happens when you ask a software engineer to design an operations function.”
Ben Treynor Sloss, VP Engineering, Founder of Google SRE

Automation and Eliminating Toil
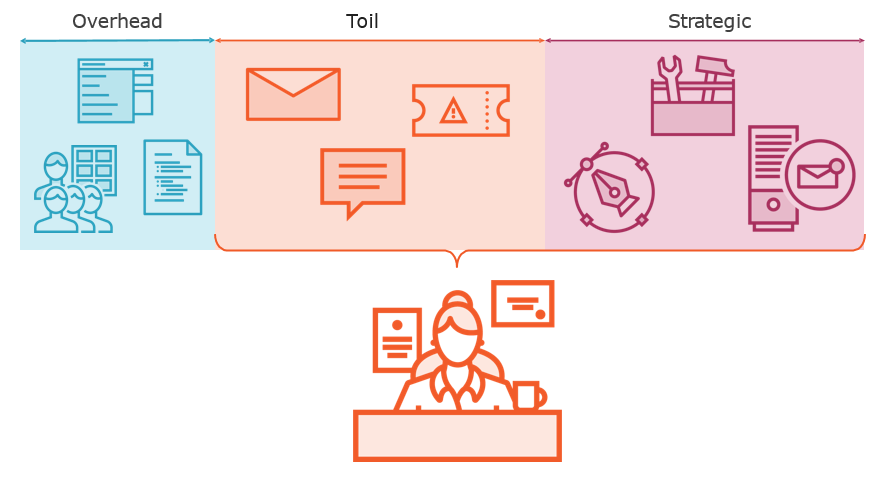
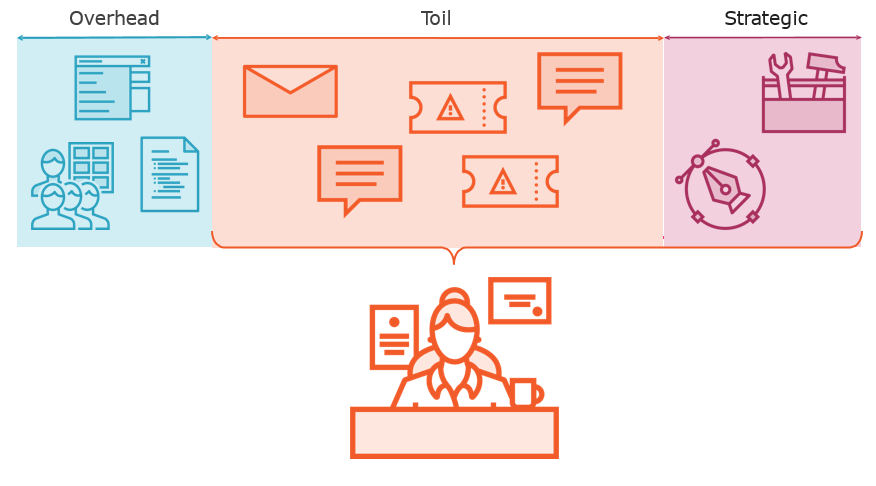
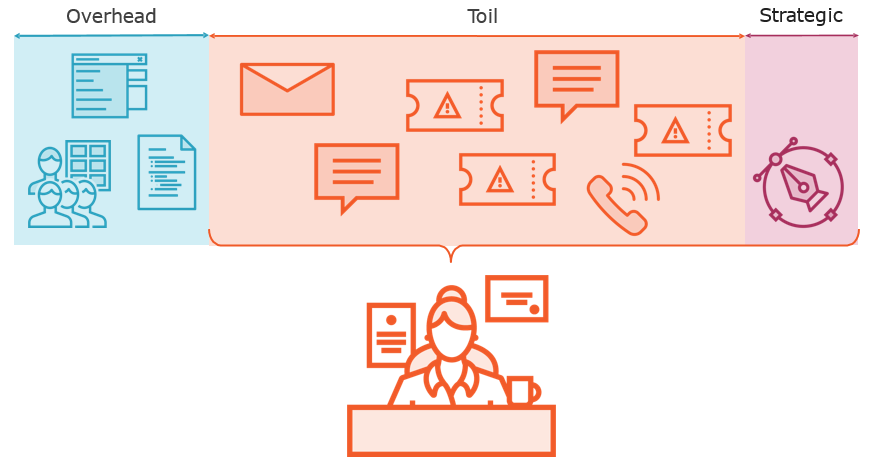
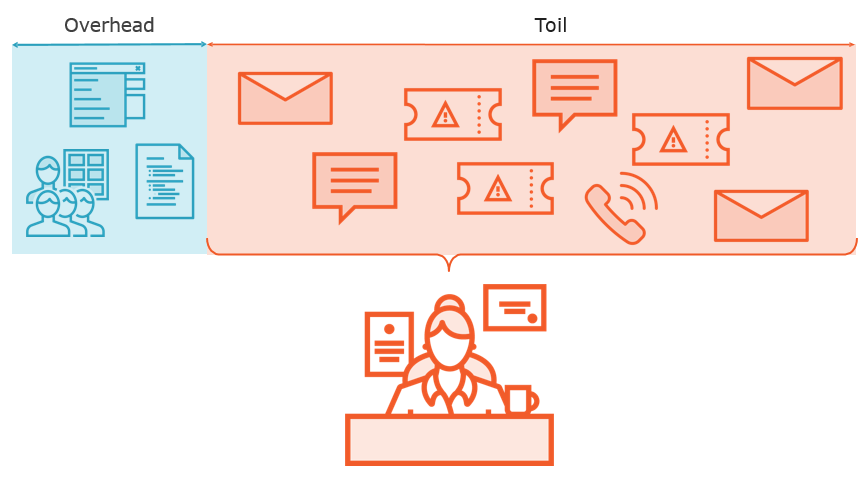
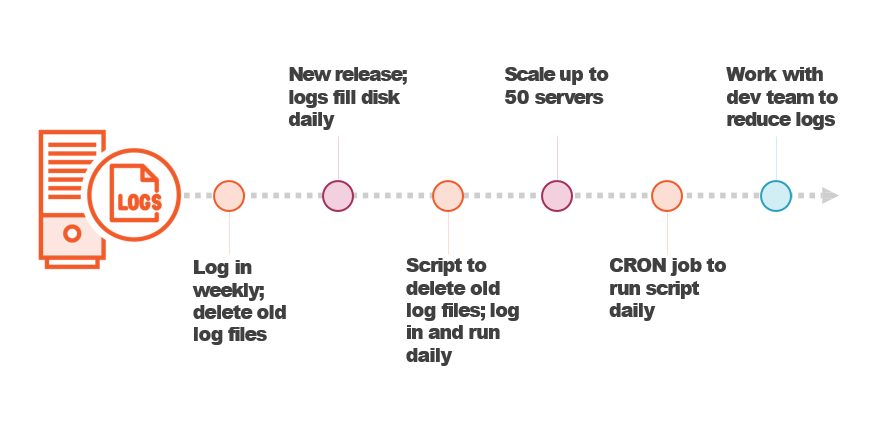
What is Toil?

Is it Toil?

Engineering in SRE
Engineering in SRE
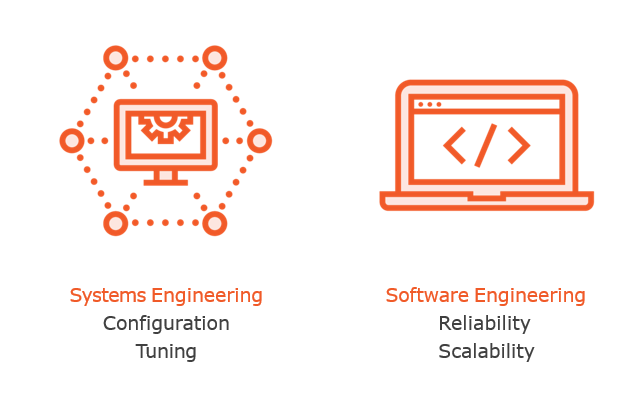
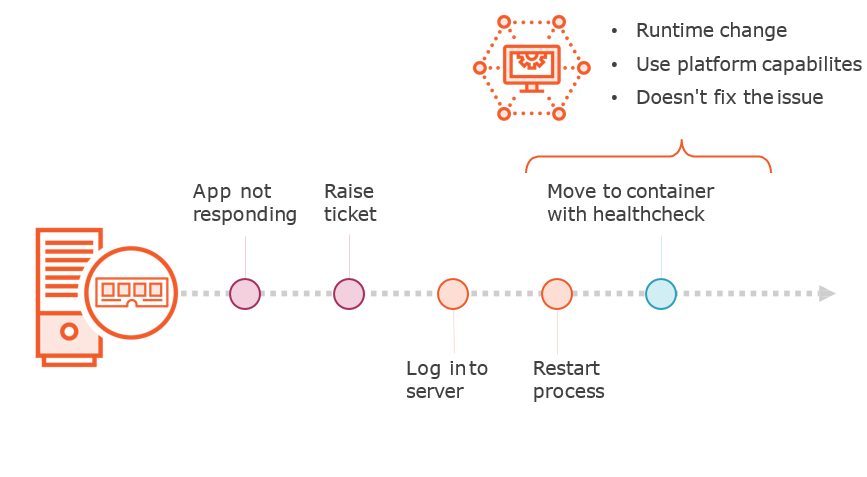
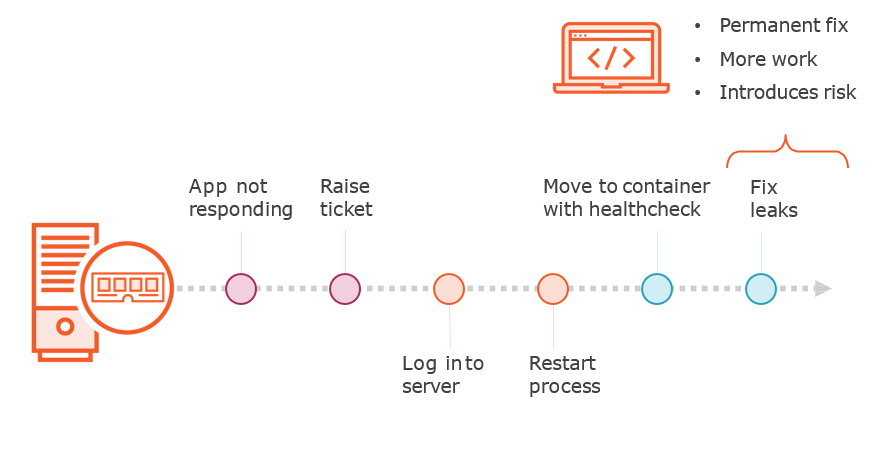
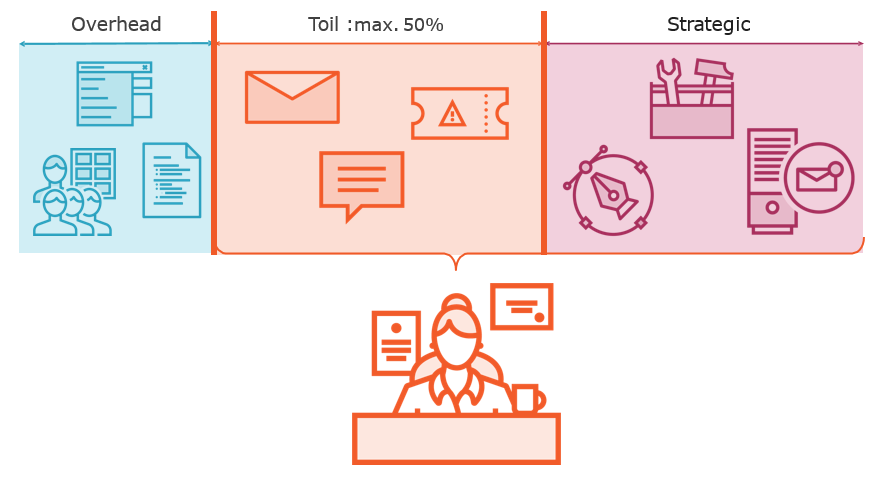
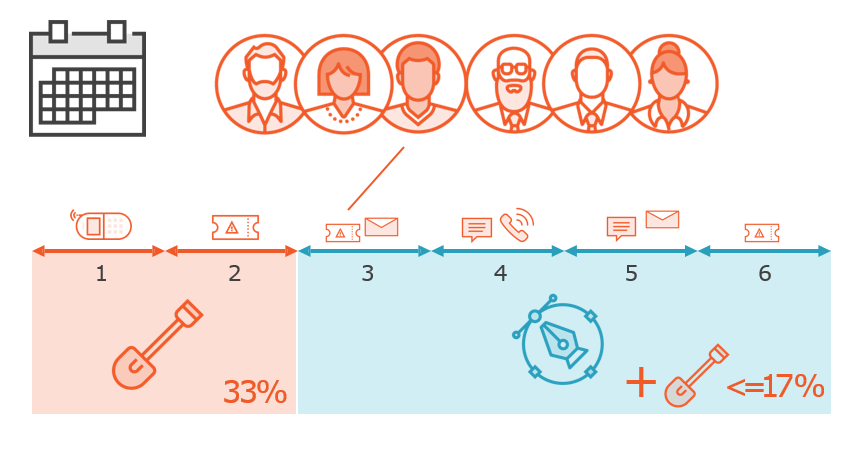
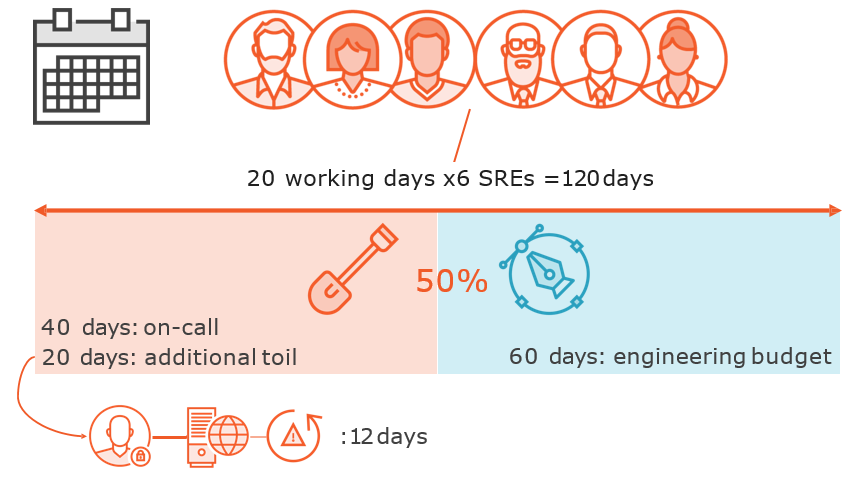
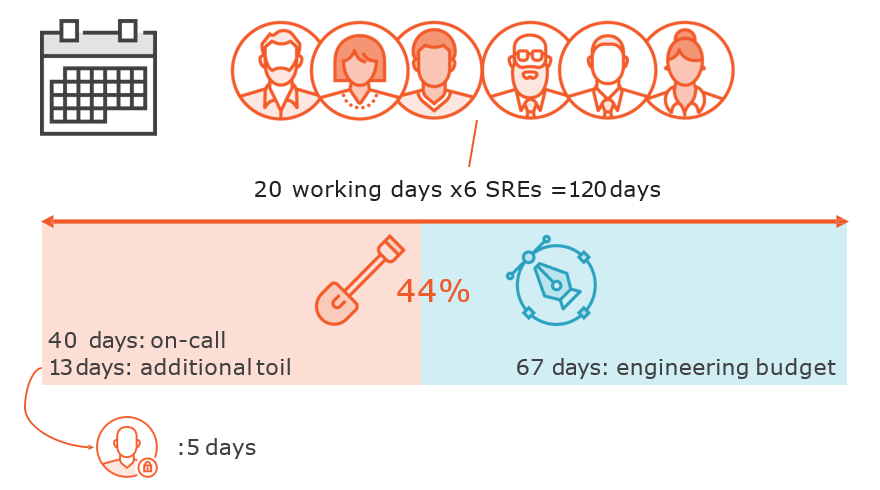
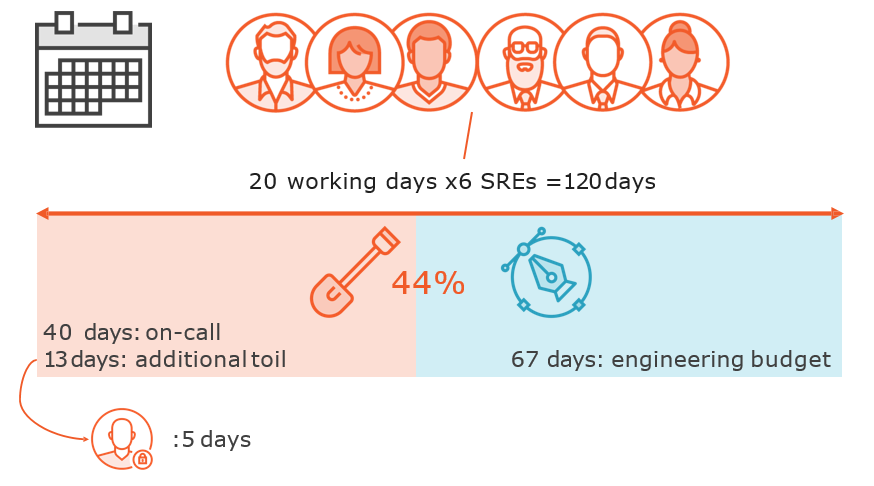
Restricting Toil to 50%


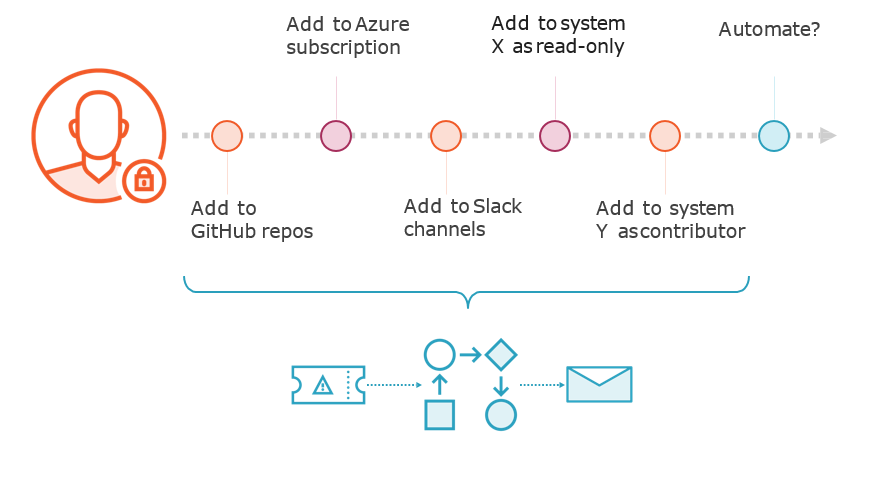
Identifying and Measuring Toil

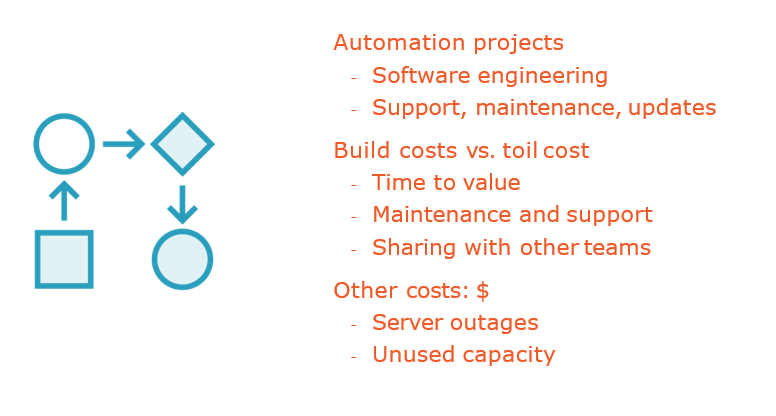
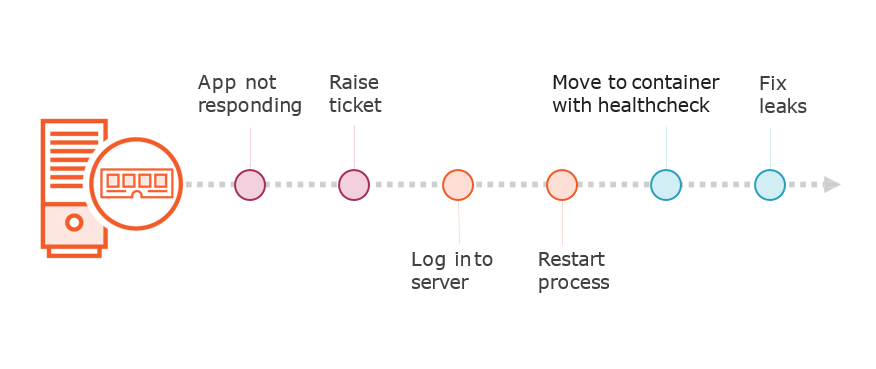
Engineering Away Toil
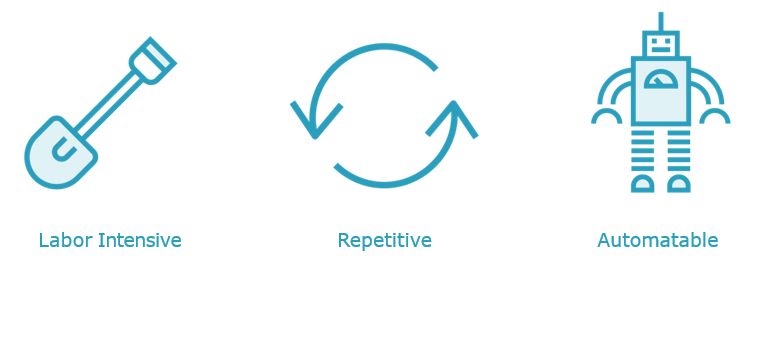
Identifying Automation Candidates

Top Toil Targets

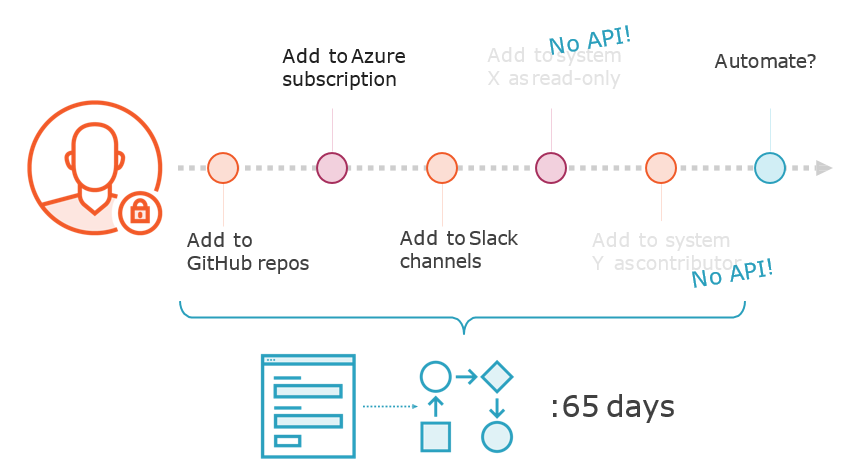
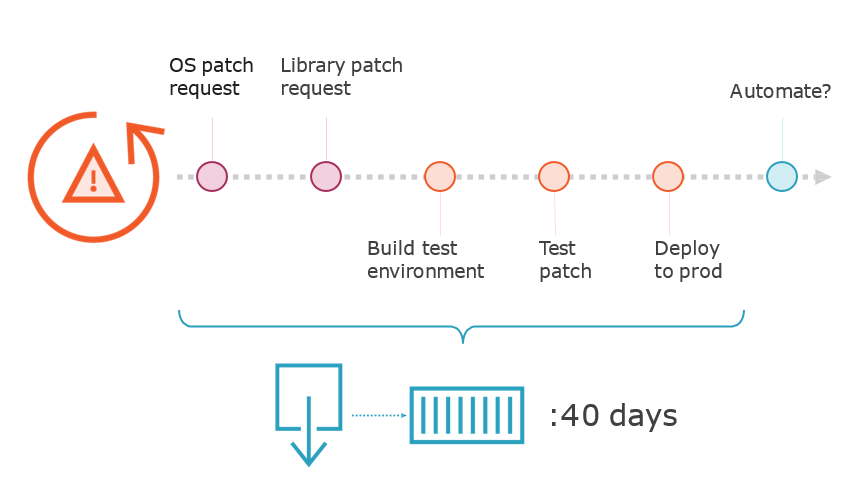
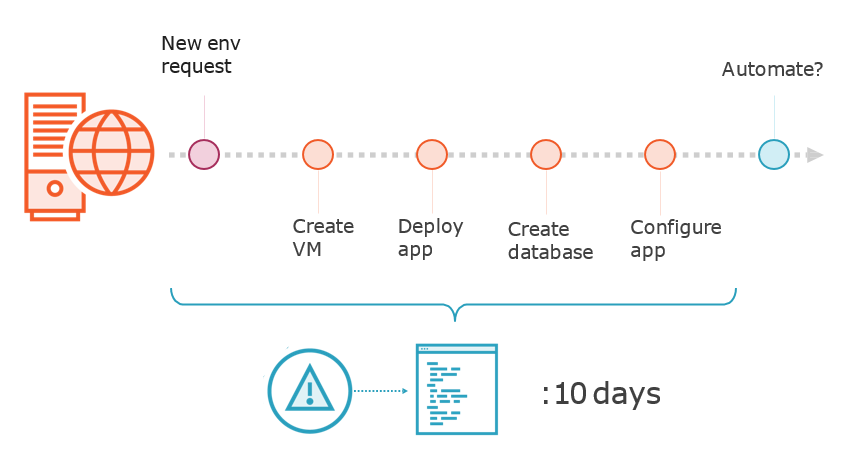
Prioritising Toil-Reducing Projects
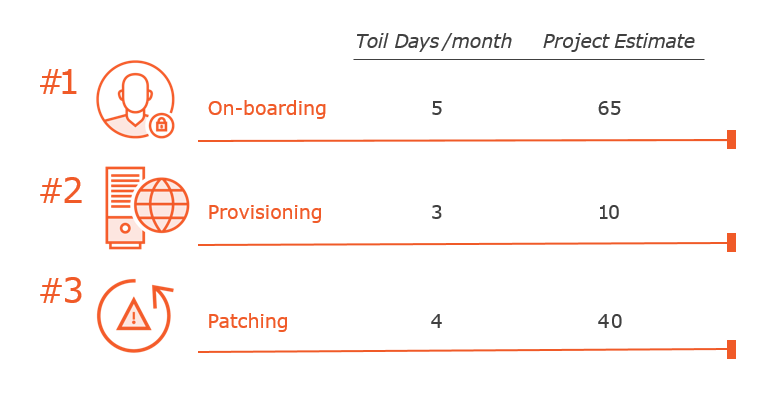
Top Toil Projects

Top Toil Projects

We Cannot Introduce DevSecOps Because…
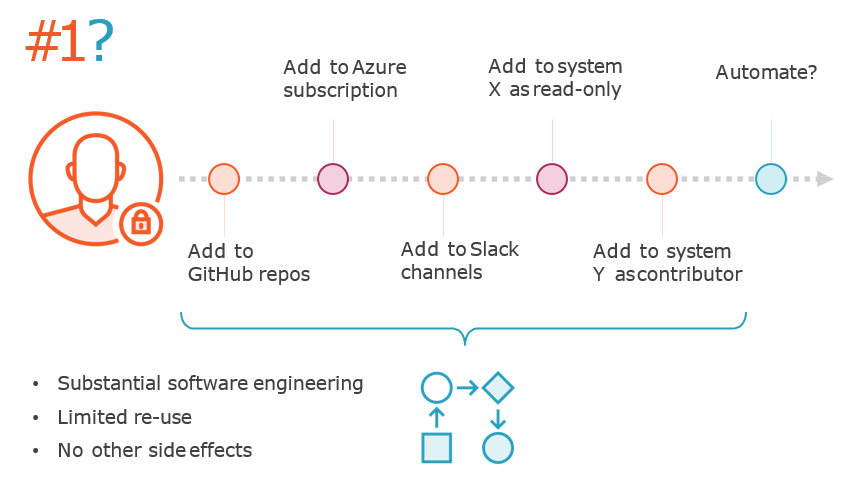
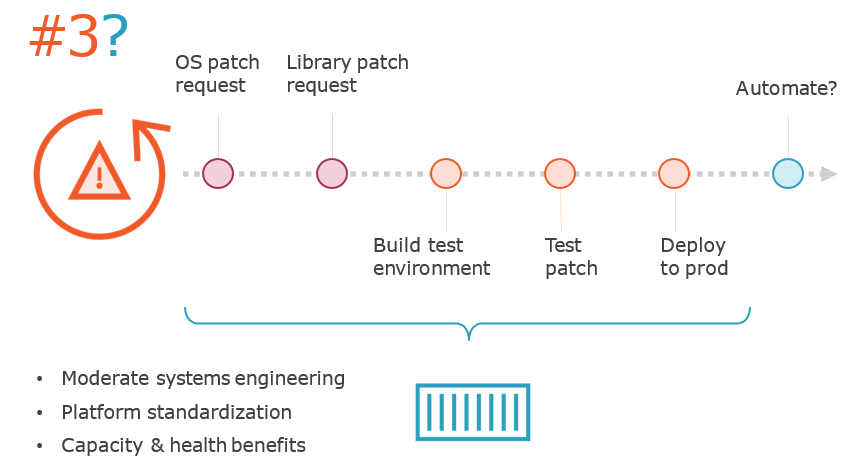
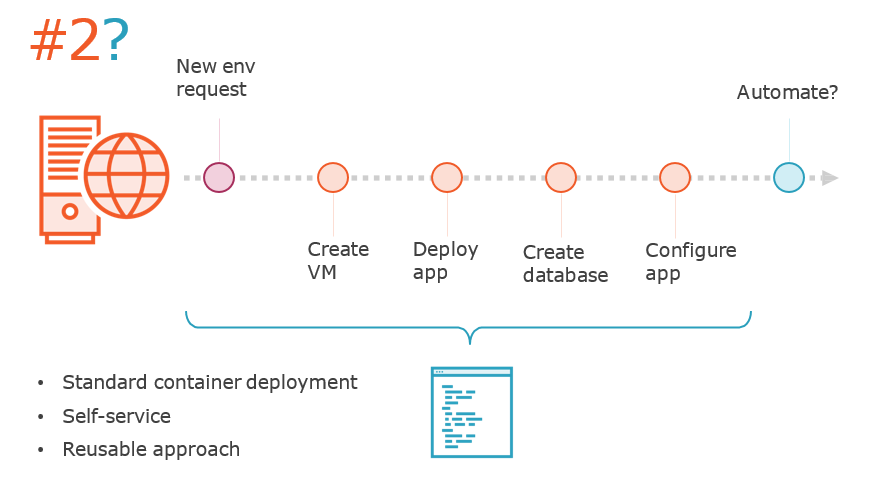
Top Toil Projects
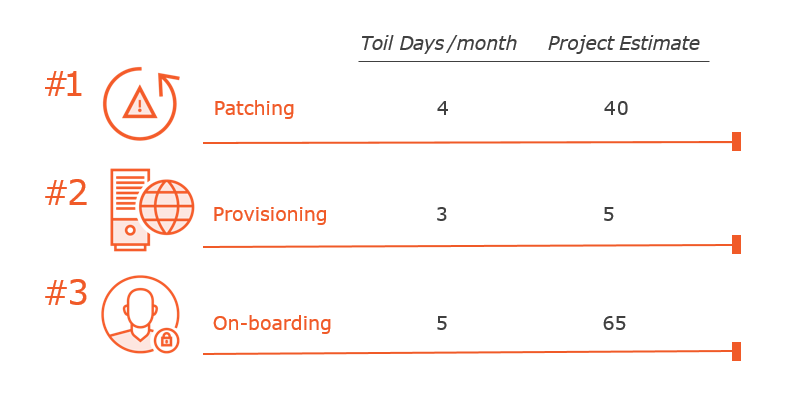
Top Toil Projects
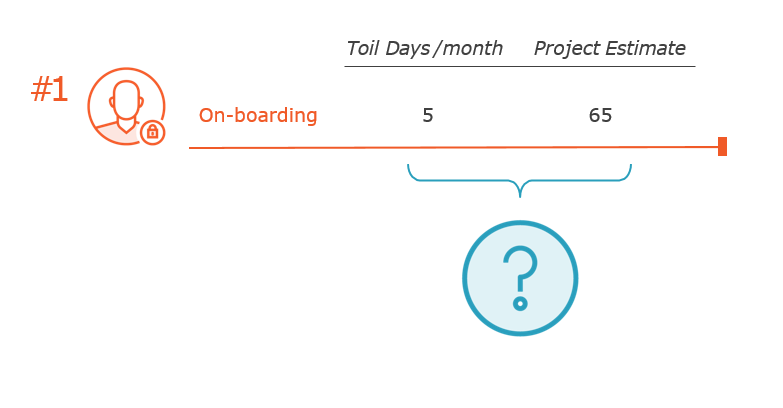
Dealing with the Remaining Toil
Impact Reduction Techniques

Impact Reduction Techniques


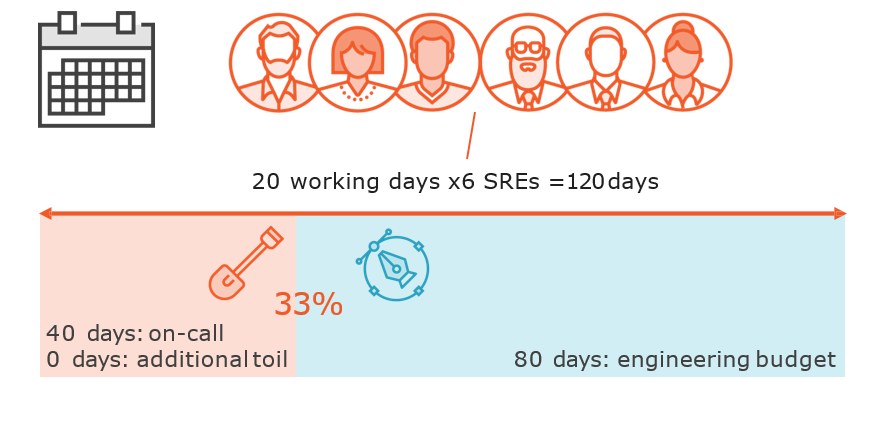
Up Next:
Service Levels, Monitoring and Alerting
Service Levels, Monitoring, and Alerting
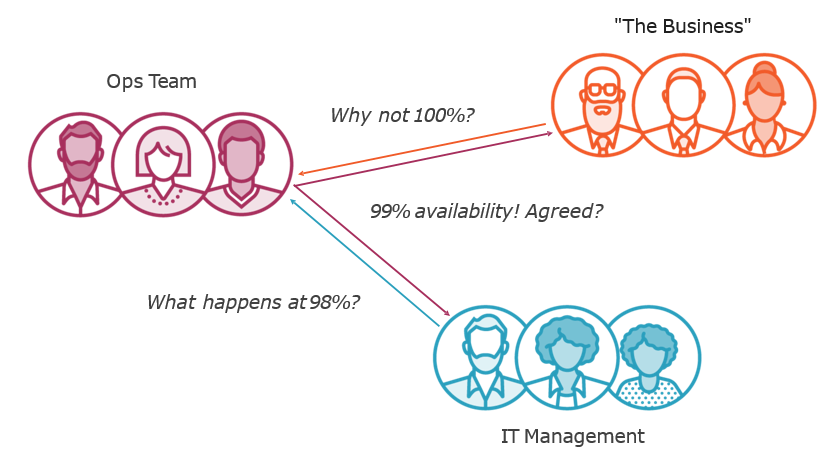
Service Level Objectives

Service Level Objectives

Service Level Objectives
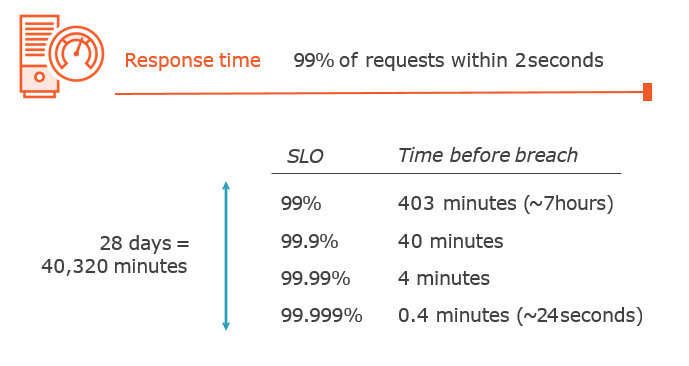
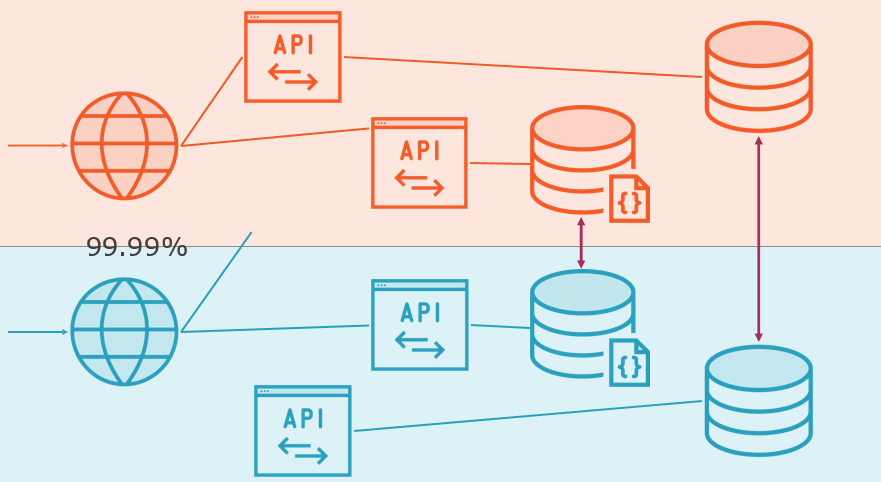
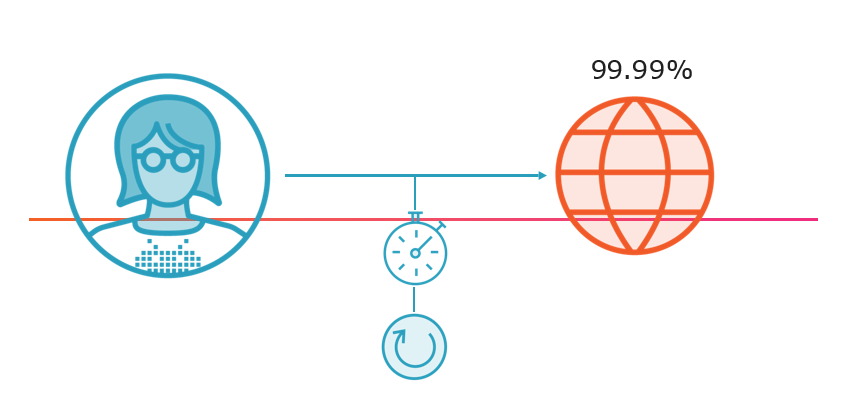
Service Level Objectives

Service Level Objectives
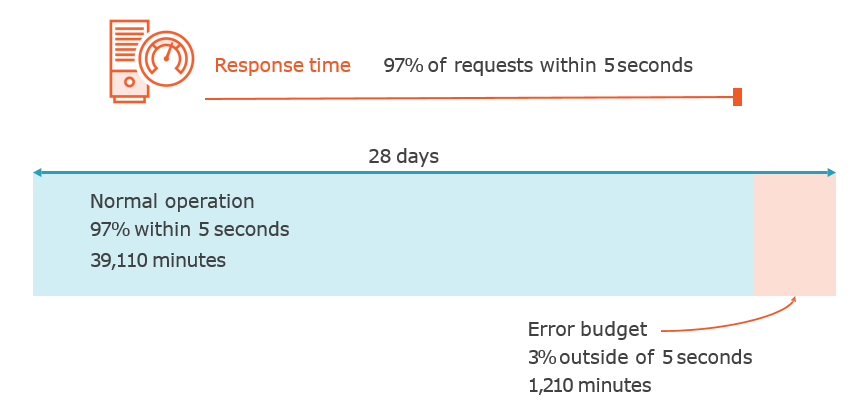
Service Level Objectives
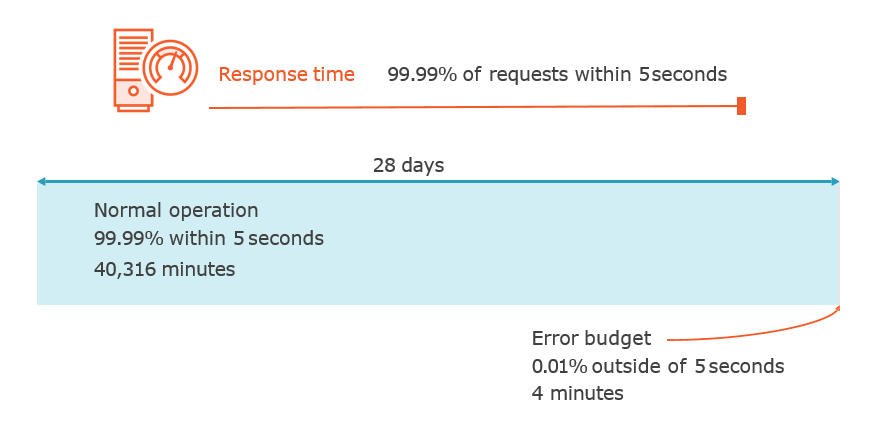

Defining Service Level Indicators and Service Level Objectives
Service Level Measurement

Service Level Indicators

Mapping SLIs to SLOs

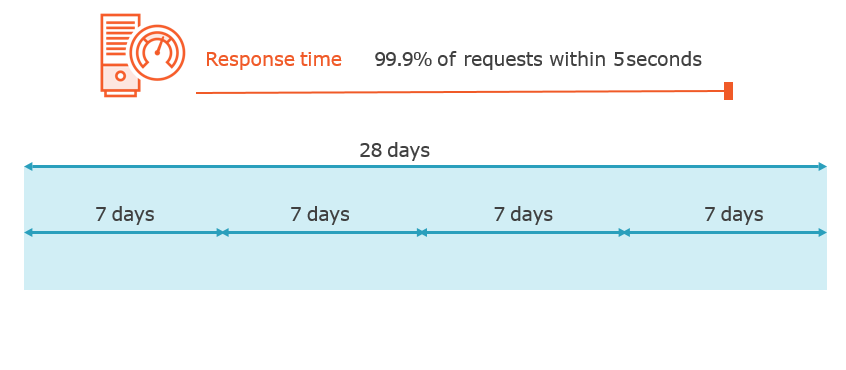
Service Level Period
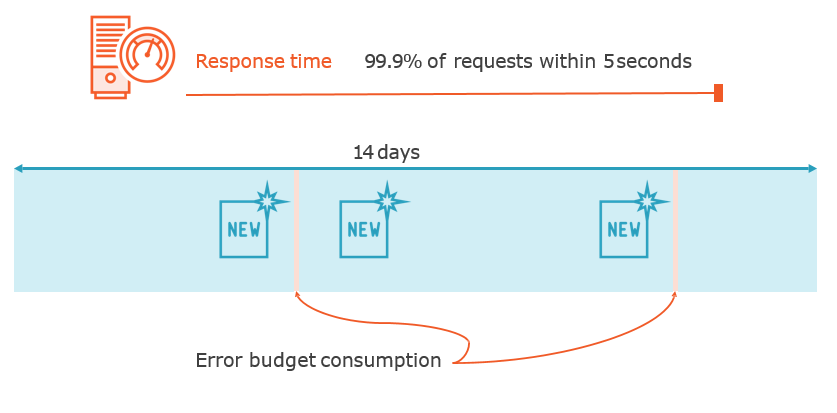
Service Level Period
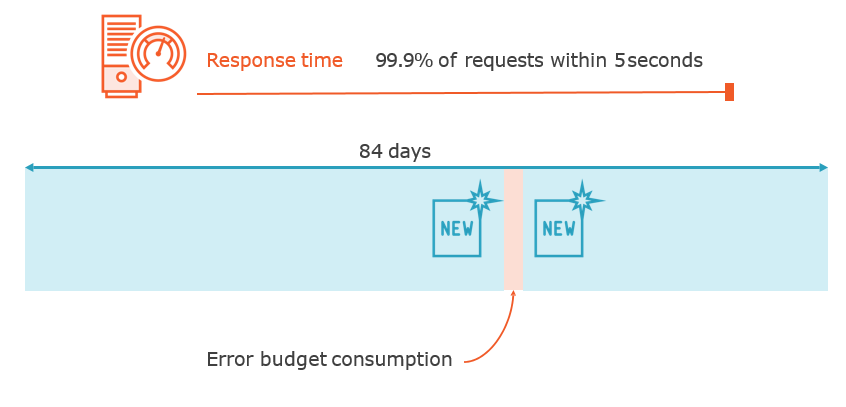
Service Level Period
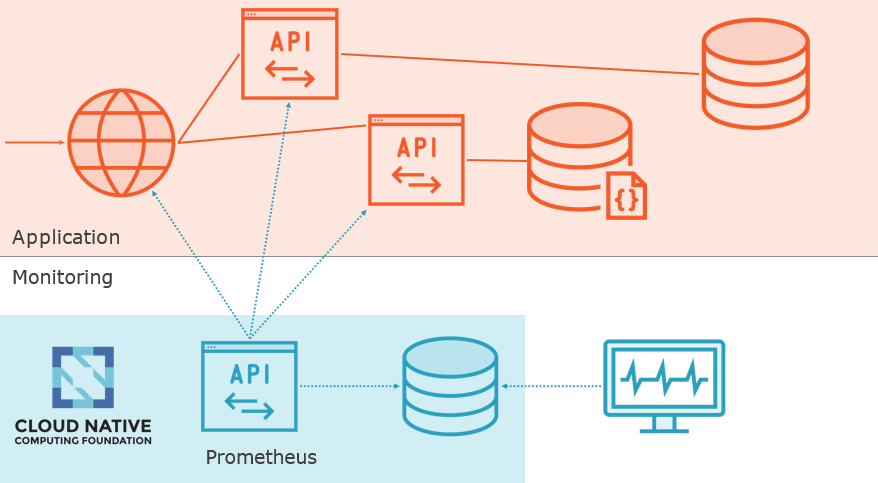
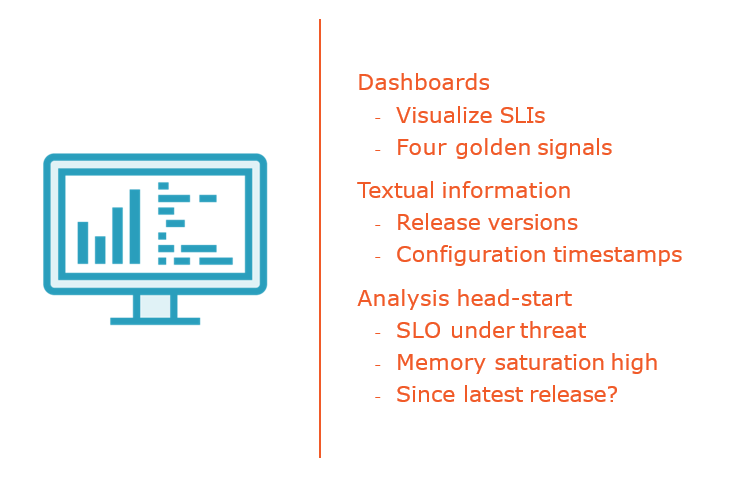
Monitoring Service Level Indicators
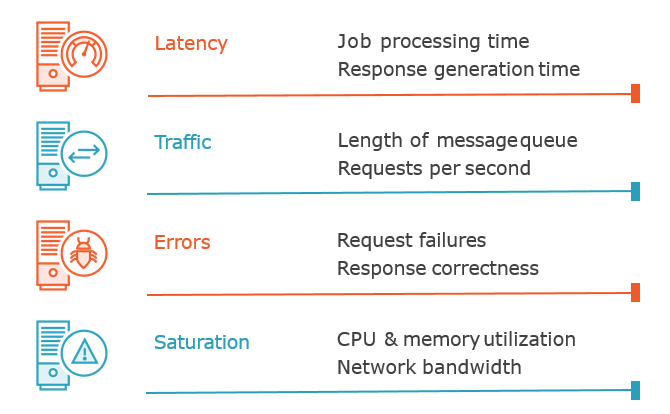
Four Golden Signals
Implementing SLIs




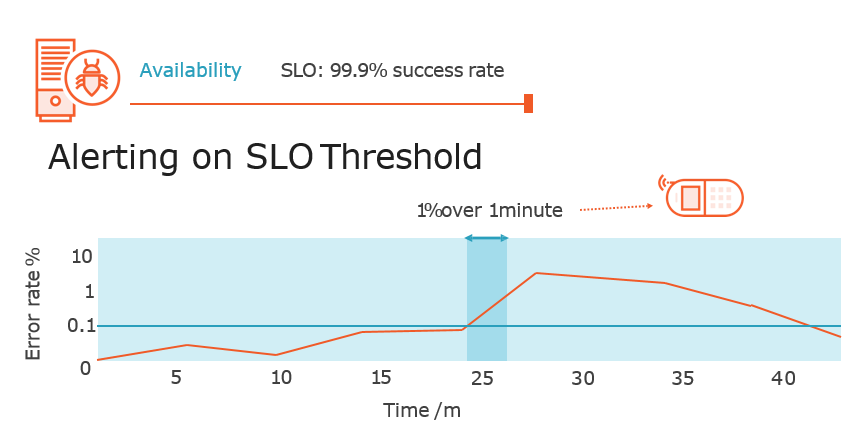
Alerting on Service Level Objectives
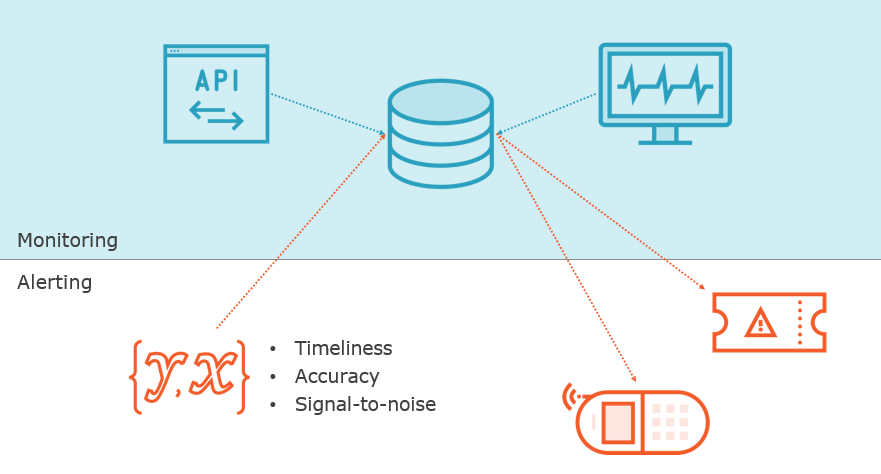
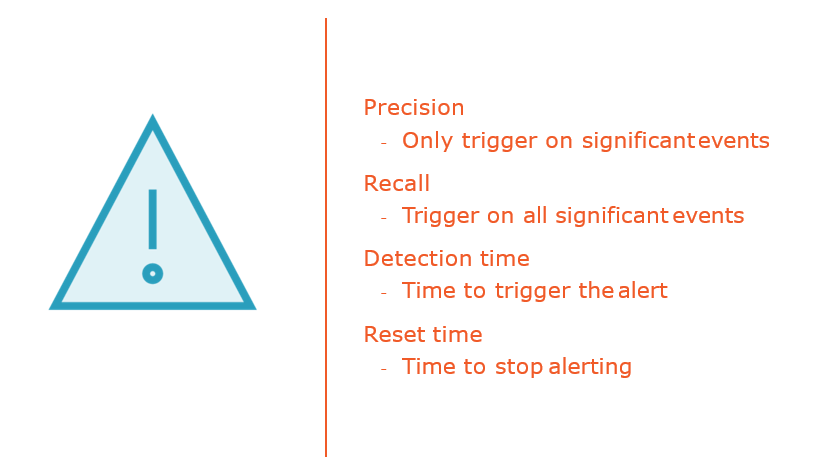
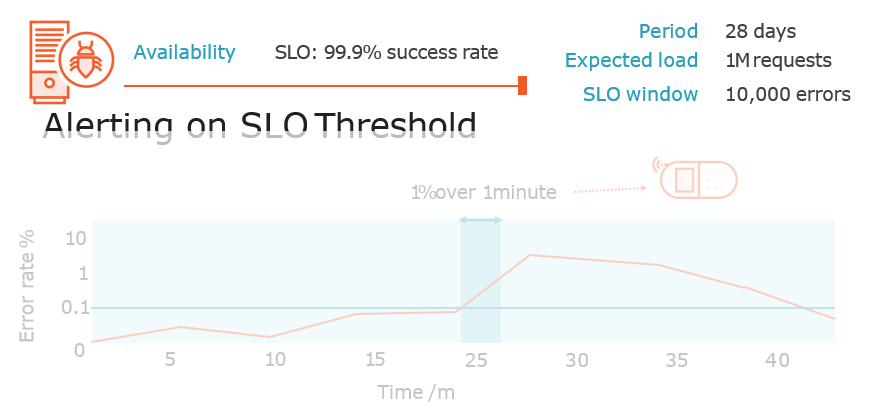
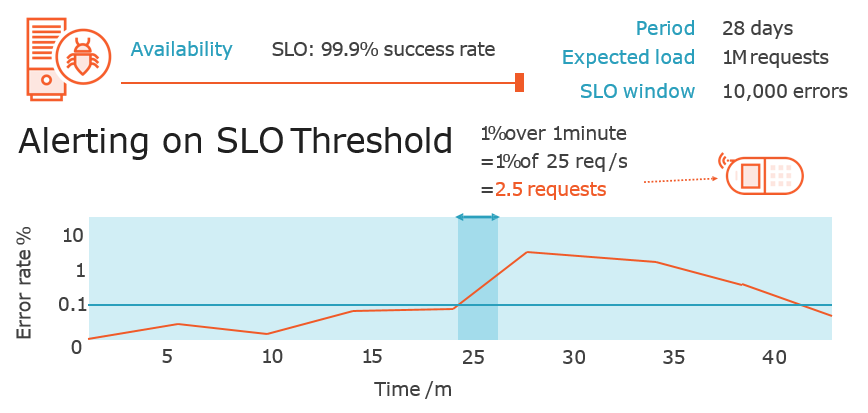
Alerting on Error Budget Burn
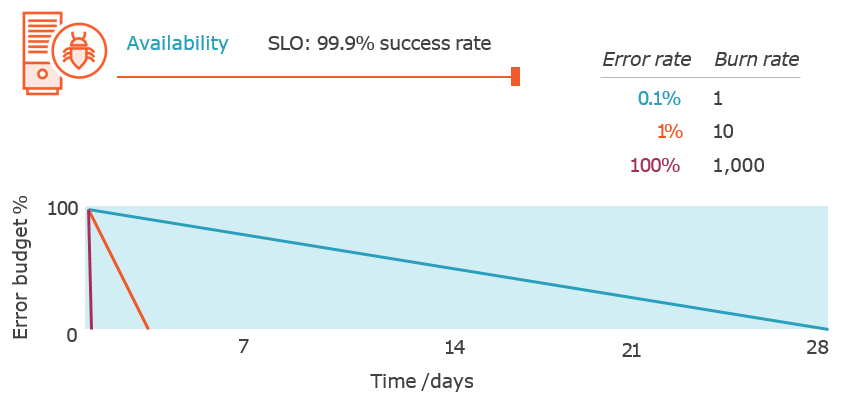
Alerting on Error Budget Burn
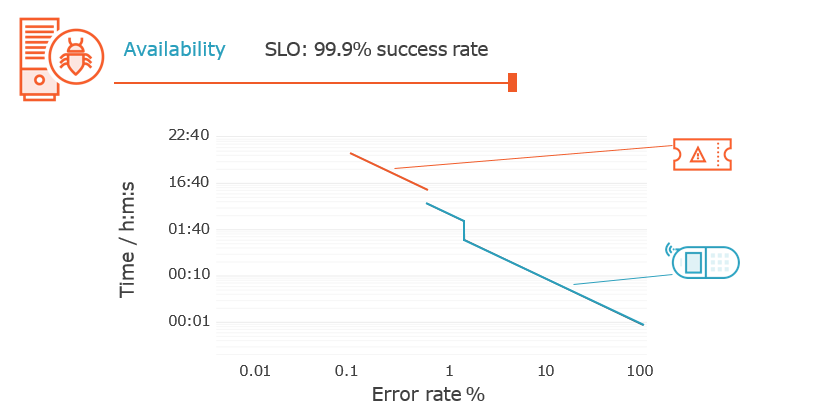
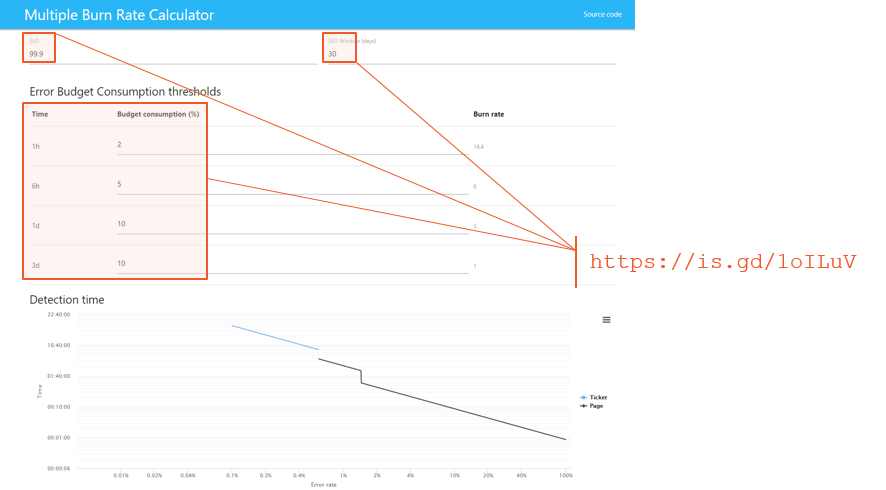

“The SLO error rate is 0.1%. Owners get paged if their backend has returned more than
1.44% 5xx responses over the last 1h and over the last 5m. They also get paged if it has returned more than 0.6% 5xx responses over the last 6d and over the last 30m.”
Björn Rabenstein, SoundCloud https://is.gd/EhtIPT


SLO Review
SLO Review

Enhanced SLOs

Up Next
Incident Management: On-call and Postmortems
Incident Management: On-call and Postmortems

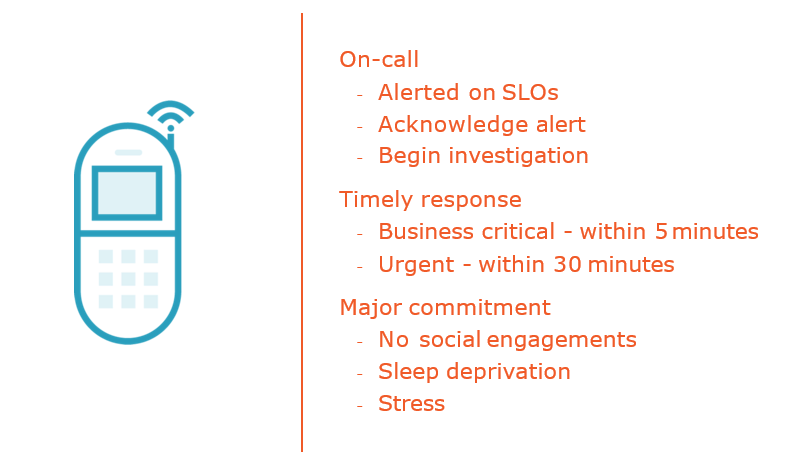
Control, Co-ordinate & Communicate
.png)
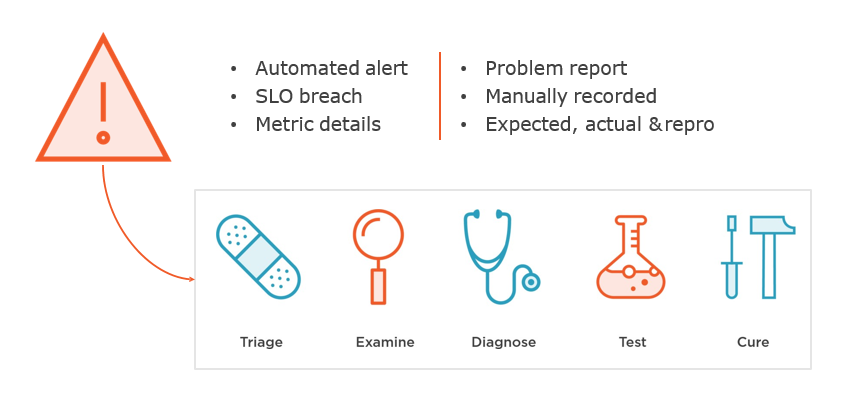
Is it an Incident?

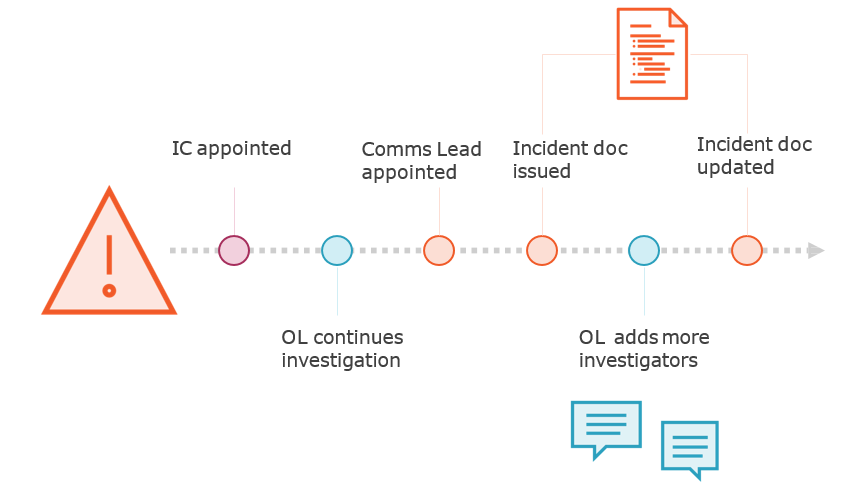
.png)
.png)
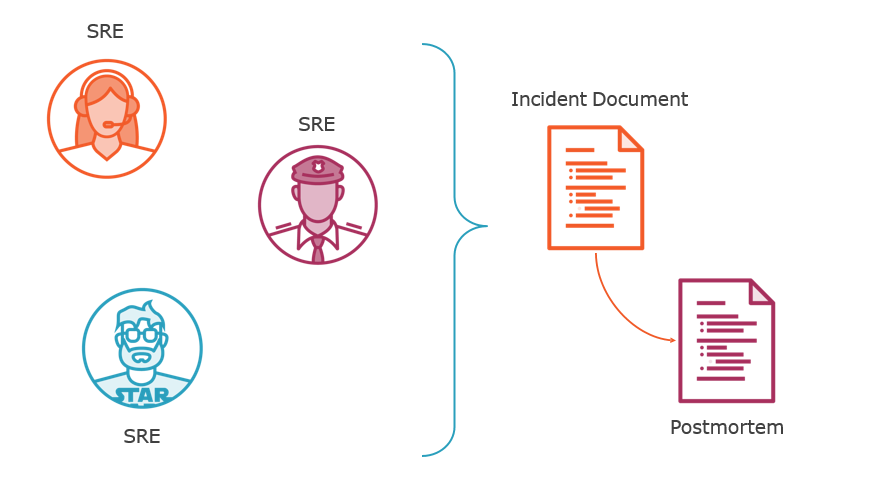
Working on Incidents Effectively
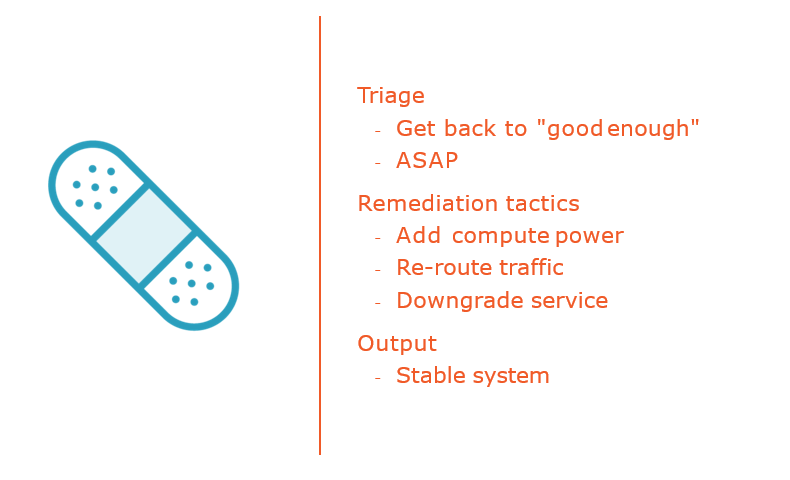
Incident Model

Incident Model
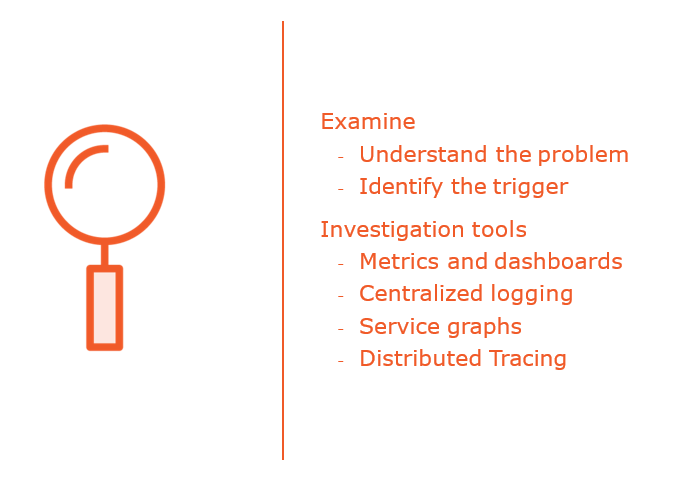


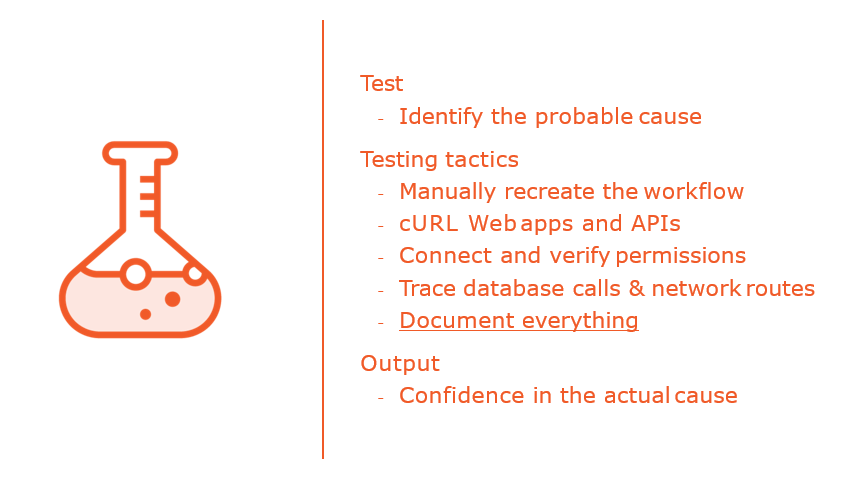
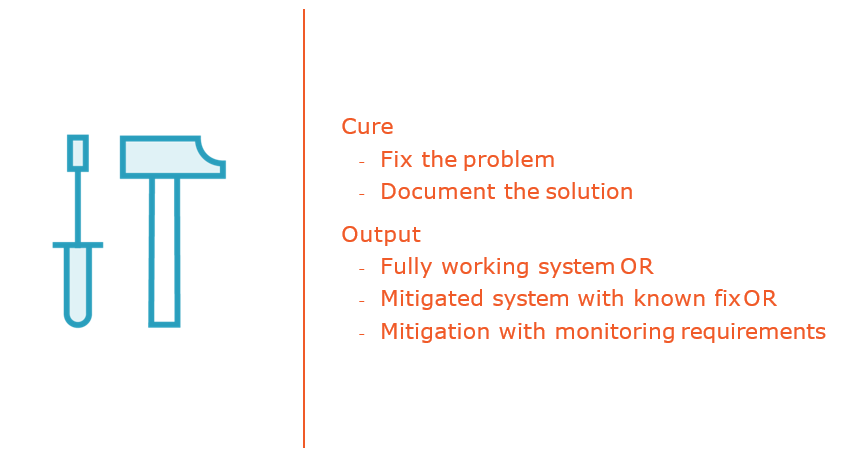
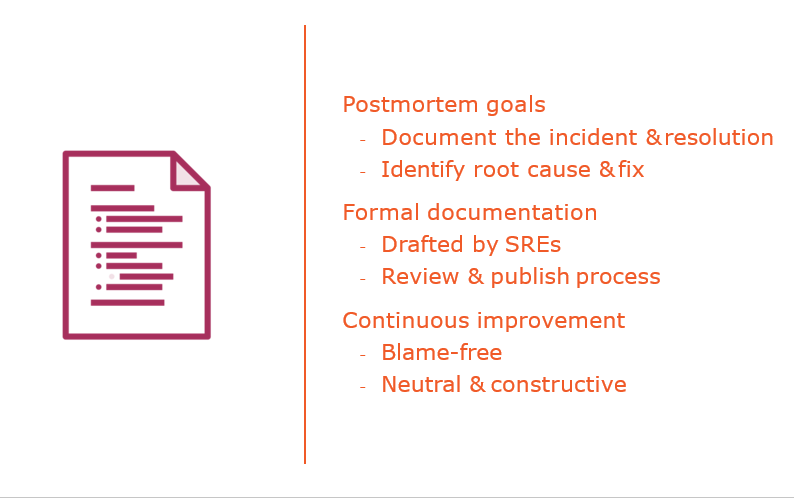
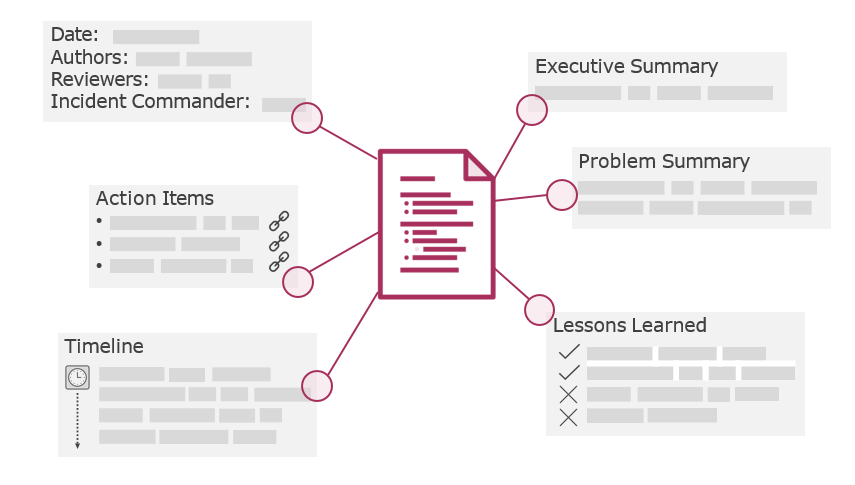
Producing and Publishing Postmortems
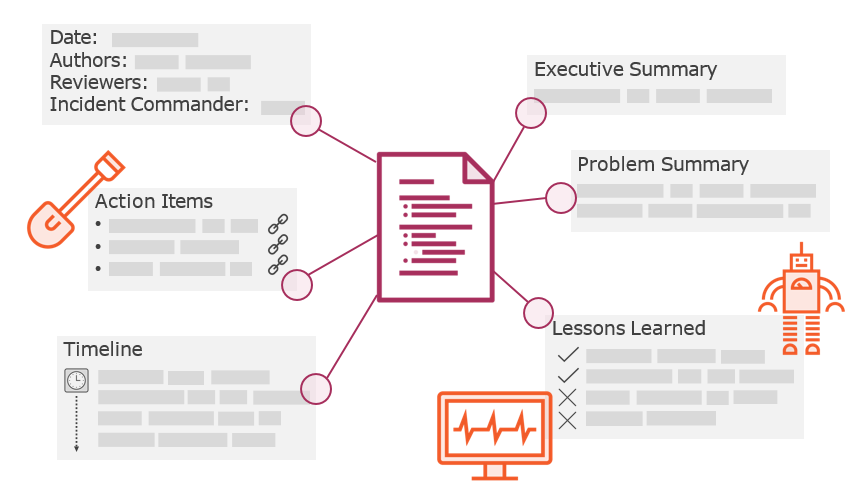

Avoiding Operational Overload

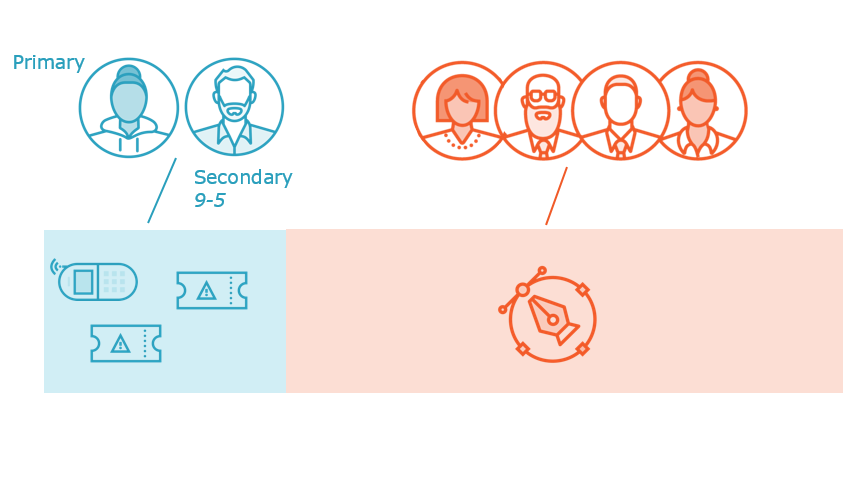
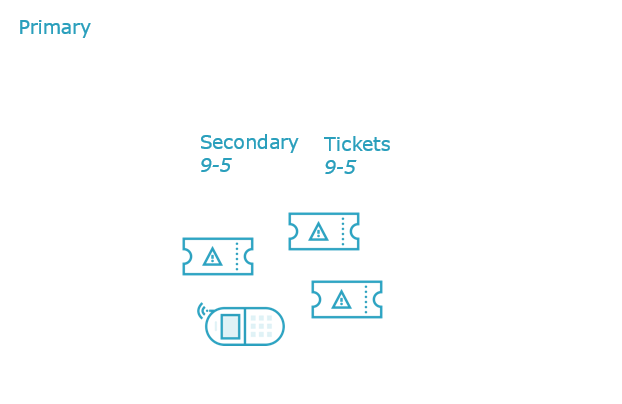
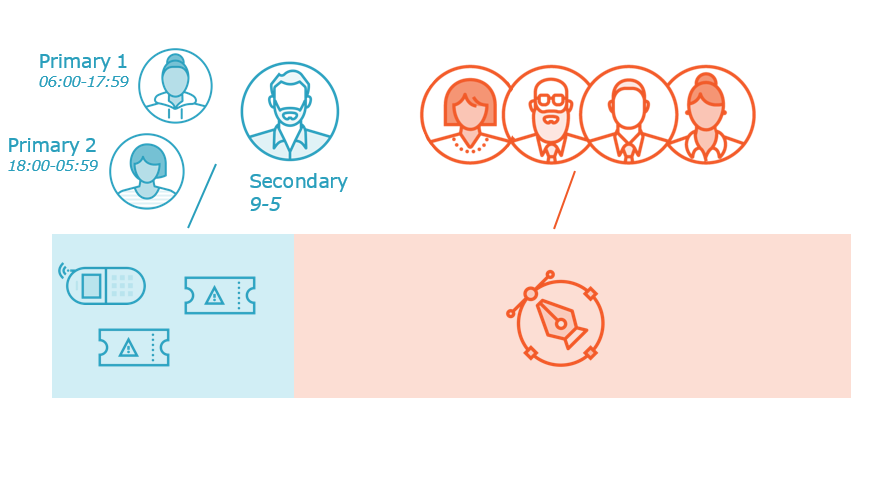

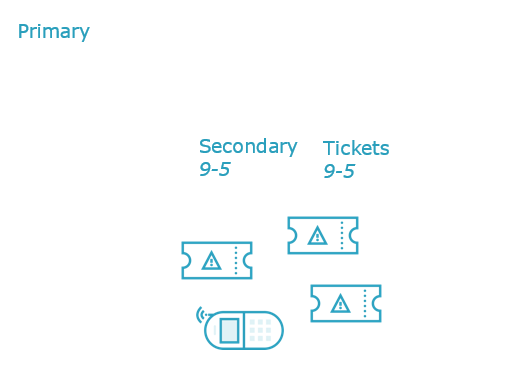
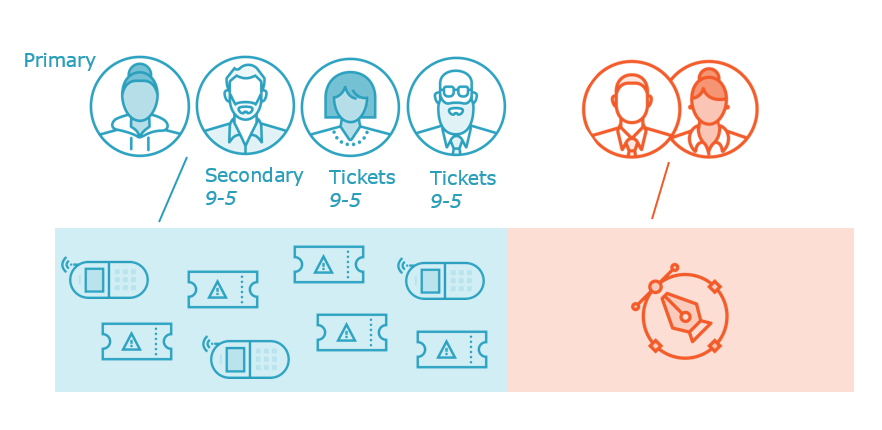
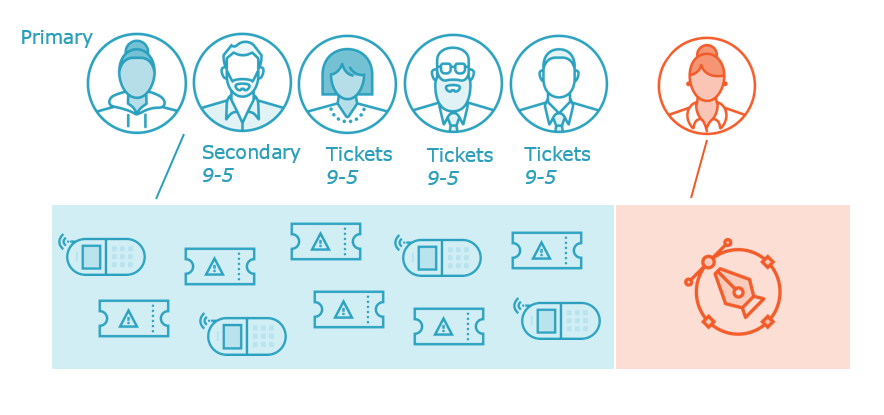
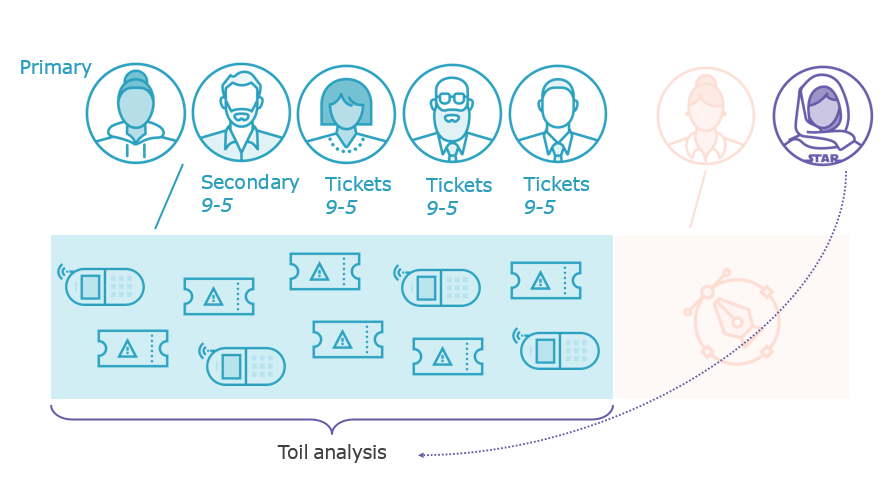
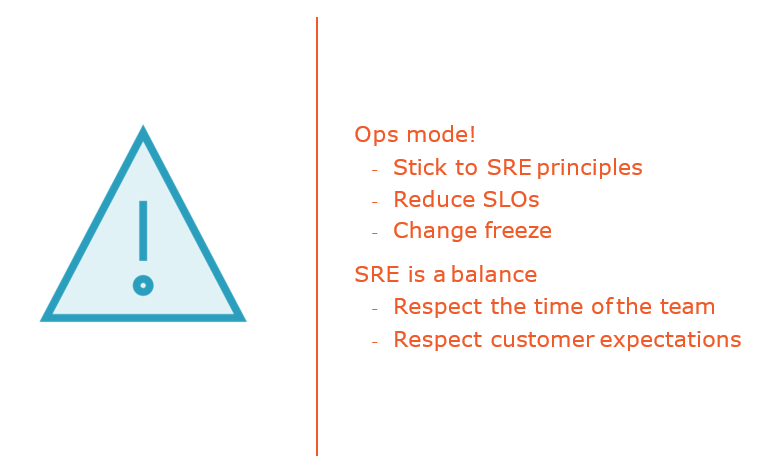
Incident management




Thank You!
DevOpsSchool — Lets Learn, Share & Practice DevOps