Friends, in this blog I’m going to explain to you about Azure Data Factory, It is a service allowing companies to transform their big data from rational, non-rational to formulate companies’ strategies, where the job of ADF is to integrate the big data for using it with data-driven workflows that equip the companies to attain goals and drive the business value of the organization from the data that is stored on the Big data.

ADLA (Azure Data Lake Analytics ) is a highly-scalable batch data processing engine using a SQL-like declarative data flow language to prepare large amounts of data (stored mainly in ADLS Gen1, but also virtualizing SQL Server data and Azure Blob store data) and to provide users ways to scale out their custom code written in .NET or Python.
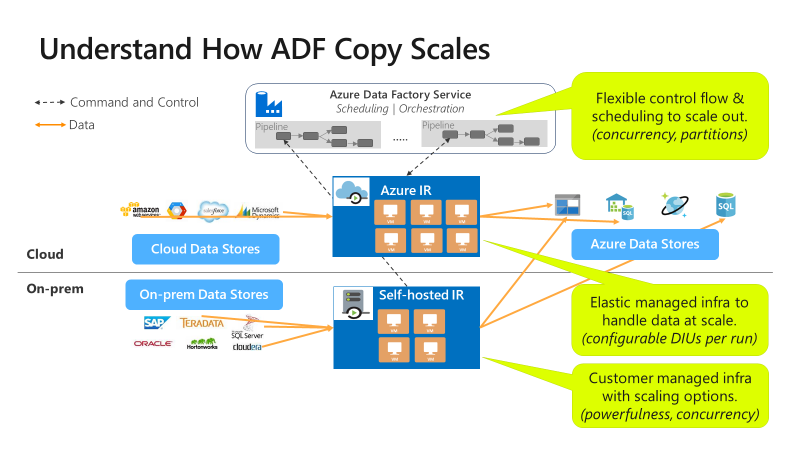
Advantages of using Azure Data Factory
- It fetches the data from various sources and converts them into a format as per user want.
- Azure Data factory connectors feature helps users to filter unwanted data. We can filter out the required data and remove the rest.
- Its copy activity feature helps copy data between various data stores located on-premises and in the cloud platforms.
- Azure Data Factory helps to promote excellent data management services.
- Using Data Factory, data structures can be stored at several data warehouses. And not only that, we can move the data from one warehouse to another by just setting the triggers.
What is the pipeline in Azure Data Factory?
Finally, I let you know about pipelines in Azure Data Factory, It can have one or more pipelines, It is a logical grouping of activities that together perform a task. Now, you can understand through example, a pipeline could contain a set of activities that ingest and clean log data, and then kick off a mapping data flow to analyze the log data.
I’m Rajesh Kumar, a DevOps, SRE, DevSecOps, Cloud, and Platform Engineering expert passionate about sharing practical knowledge, real-world experiences, and industry best practices. I have worked at Cotocus and regularly write about technology, travel, investing, health, product reviews, and digital marketing through my various platforms.
I publish technical articles at DevOps School, travel stories at Holiday Landmark, stock market insights at Stocks Mantra, health and fitness guidance at My Medic Plus, product reviews at TrueReviewNow, and SEO and digital marketing strategies at Wizbrand.
Find Trusted Cardiac Hospitals
Compare heart hospitals by city and services — all in one place.
Explore Hospitals