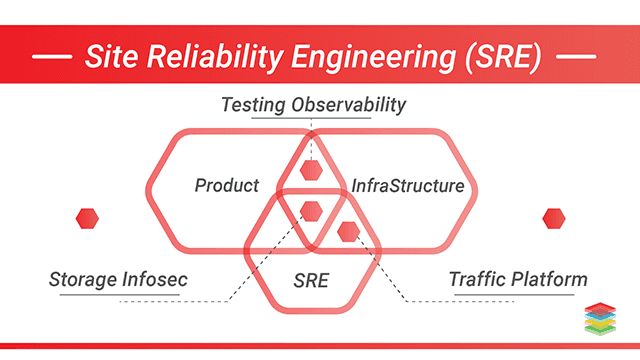
SRE(site reliability engineering) was first coined in 2003 at Google as a drive towards reliability. As Google asked their software engineers to prioritize reliability as they collectively worked towards efficiency and scalability goals, new approaches were needed to solve the underlying weaknesses in traditional paradigms. Over time, these approaches coalesced into Site Reliability Engineering as a general practice, with a primary focus on the leveraging of automation, tools, and processes.
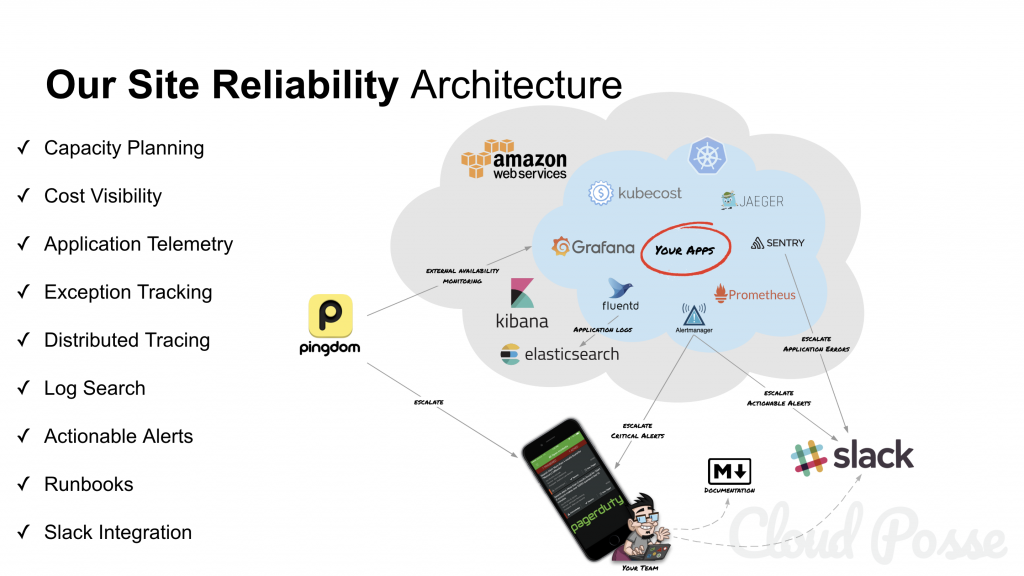
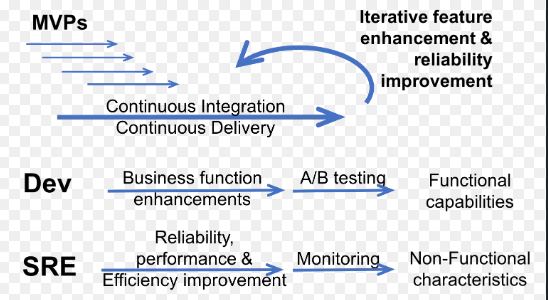
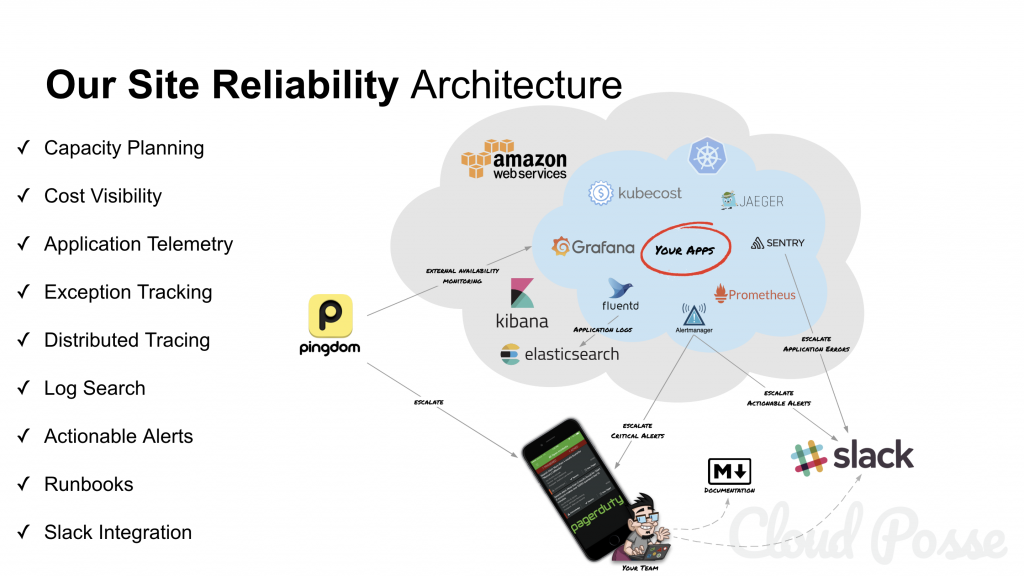
As SRE(site reliability engineering) evolved, solutions such as on-call monitoring, automation for capacity planning and scaling, and disaster response planning were added to the SRE playbook. These and a general concept of automation towards resolutions became core facets of the SRE approach. In basic terms, SRE is about improving operational reliability and efficiency.
Ben Traynor, VP of engineering at Google and founder of Google SRE, pinpointed the essence of the SRE role in this interview:
“SRE is fundamentally doing work that has historically been done by an operations team, but using engineers with software expertise and banking on the fact that these engineers are inherently both predisposed to, and have the ability to, substitute automation for human labor. In general, an SRE team is responsible for availability, latency, performance, efficiency, change management, monitoring, emergency response, and capacity planning.”
SRE(site reliability engineering) is what you get when you treat operations as if it’s a software problem. Our mission is to protect, provide for, and progress the software and systems behind all of Google’s public services — Google Search, Ads, Gmail, Android, YouTube, and App Engine, to name just a few — with an ever-watchful eye on their availability, latency, performance, and capacity.
DevOpsSchool’s (Site Reliability Engineer) SRE Certification is a roadmap to the principles & practices that allows an organization to reliably and economically scale Developement to Ops and Productions.


I’m Rajesh Kumar, a DevOps, SRE, DevSecOps, Cloud, and Platform Engineering expert passionate about sharing practical knowledge, real-world experiences, and industry best practices. I have worked at Cotocus and regularly write about technology, travel, investing, health, product reviews, and digital marketing through my various platforms.
I publish technical articles at DevOps School, travel stories at Holiday Landmark, stock market insights at Stocks Mantra, health and fitness guidance at My Medic Plus, product reviews at TrueReviewNow, and SEO and digital marketing strategies at Wizbrand.
Find Trusted Cardiac Hospitals
Compare heart hospitals by city and services — all in one place.
Explore Hospitals