In this blog, I am going to explain that Codebases grow as we write code to add new features. Over time, it can be difficult to know where a change needs to be made because the codebase is so large.
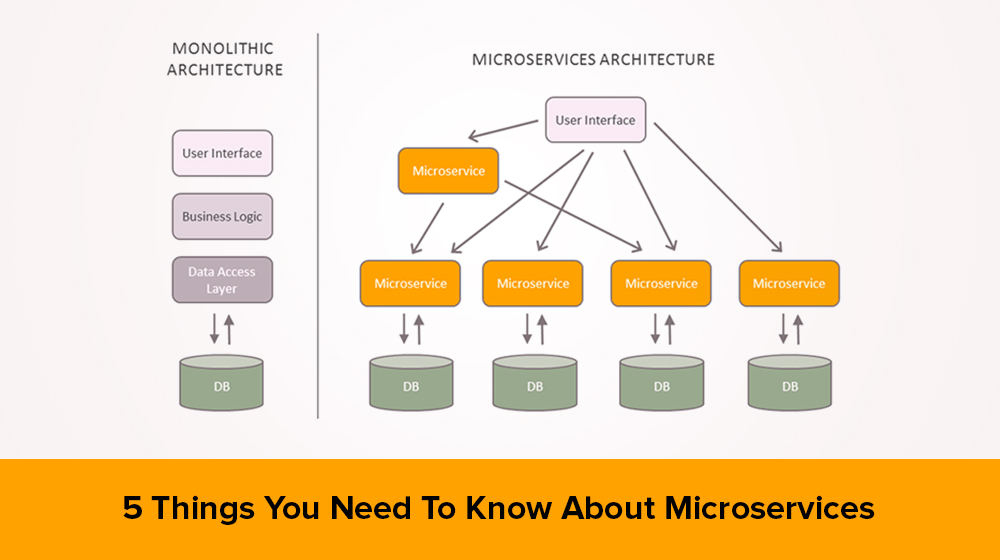
Despite a drive for clear, modular monolithic codebases, all too often these arbitrary in-process boundaries break down. Code related to similar functions starts to become spread all over, making fixing bugs or implementations more difficult.
Within a monolithic system, we fight against these forces by trying to ensure our code is more cohesive, often by creating abstractions or modules. Cohesion—the drive to have related code grouped together—is an important concept when we think about microservices. This is reinforced by Robert C.
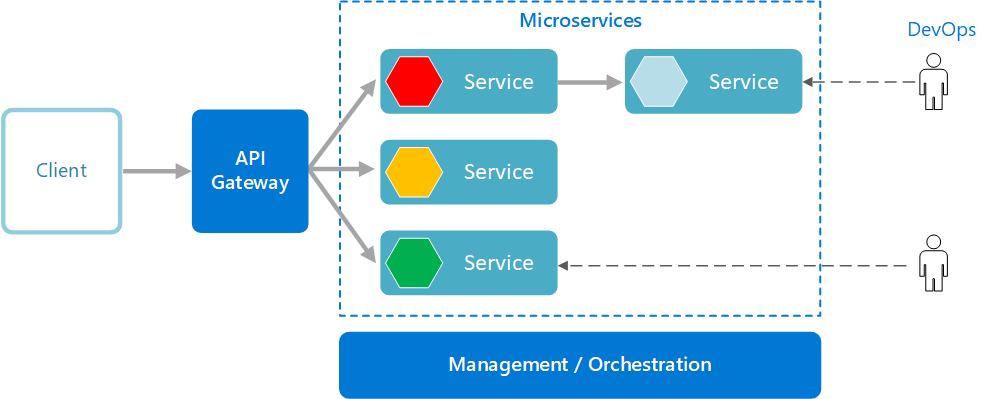
Martin’s definition of the Single Responsibility Principle, which states “Gather together those things that change for the same reason, and separate those things that change for different reasons.” Microservices take this same approach to independent services.
We focus our service boundaries on business boundaries, making it obvious where code lives for a given piece of functionality. And by keeping this service focused on an explicit boundary, we avoid the temptation for it to grow too large, with all the associated difficulties that this can introduce.
The question I am often asked is how small is small? Giving a number for lines of therefore do more in fewer lines of code. We must also consider the fact that we could be pulling in multiple dependencies, which themselves contain many lines of code. In addition, some part of your domain may be legitimately complex, requiring more code.
Jon Eaves at RealEstate.com.au in Australia characterizes a microservice as something that could be rewritten in two weeks, a rule of thumb that makes sense for his particular context.
Another somewhat trite answer I can give is small enough and no smaller. When speaking at conferences, I nearly always ask the question who has a system that is too big and that you’d like to break down? Nearly everyone raises their hands. We seem to have a very good sense of what is too big, and so it could be argued that once a piece of code no longer feels too big, it’s probably small enough.
I’m Rajesh Kumar, a DevOps, SRE, DevSecOps, Cloud, and Platform Engineering expert passionate about sharing practical knowledge, real-world experiences, and industry best practices. I have worked at Cotocus and regularly write about technology, travel, investing, health, product reviews, and digital marketing through my various platforms.
I publish technical articles at DevOps School, travel stories at Holiday Landmark, stock market insights at Stocks Mantra, health and fitness guidance at My Medic Plus, product reviews at TrueReviewNow, and SEO and digital marketing strategies at Wizbrand.
Find Trusted Cardiac Hospitals
Compare heart hospitals by city and services — all in one place.
Explore Hospitals