Version control systems play a vital role in the success of a software development team. This blog aims to provide a simple branching and merging strategy to manage the code in a fast paced team development environment.
When do you need branching?
You may need to adopt branching in many different scenarios. Let us assume that on a day to day basis you use agile methodologies such as extreme programming or scrum and you have finally released a reasonably complex project with Version 1.0.0.0. Couple of days after the release, you get a request for a new feature that must go as Version 1.1.0.0. You envision it will take couple of weeks to get that feature coded, tested and released. Meanwhile, simple modifications and patches are requested on a day to day basis in the Version 1.0.0.0.
Essentially, with the changing business needs you are required to do a deployment every other day or so i.e. your deployment cycle is 2 days or less.
SVN branching strategy
With a team of 10 developers it will be a nightmare in the absence of a proper branching strategy.
Trunk, branch, and tag are the 3 main divisions in subversion repository.
Trunk:
The code in trunk is always maintained as close to release state as possible. Any developer making changes to the trunk must be absolutely certain that his or her part can be coded, tested and is ready to deploy within 2 days (can vary depending on your length of deployment cycle). If it takes more than 2 days, they are not allowed to directly change the code in the trunk. They have to create a branch.
Branch:
Developer Branch:
Each developer must create his or her own branch if their code will take more time to program than your normal deployment cycle. It is the responsibility of the developer to regularly (timeframe depends on your development environment) merge changes from trunk to his branch.
Feature branch:
Create a feature branch if 2 or more developers are going to work on a new feature that will take considerable time to complete. It is the responsibility of the team lead to merge changes from trunk to this feature branch on a regular basis.
It is always beneficial to merge changes from trunk frequently. Because, after a couple of days conflict between trunk version and branch version can get out of hand and merging will practically be impossible.
When the developer branch or feature branch is ready for release, merge changes back from the branch to trunk.
Tags:
Tag is similar to branch. When you create a branch simply rename the folder from branch/branches to tag. I always use Tags to tag a release whenever a new release version is deployed. This will come in handy if a very minor patch has to be made on the release version when your trunk is temporarily dirty. Ideally, you do not merge from trunk to the tag.
Finally, remember that there is no ideal branching and merging strategy. It pretty much depends on your unique development environment. If you have any other strategy, I would like to hear about that.
It is an exciting time for Subversion as its adoption continues at a dizzying pace in enterprises. I’m out there helping that adoption so I’m a bit late in posting the questions and answers I promised around the three basic branching strategies that I covered in the last two webinars in which I presented (Branching and Merging Strategies for Subversion 1.5 and Advanced Merge Tracking and Branching with Subversion 1.5). Hopefully these will be useful to many of you.
First, a quick reminder on what the three branching strategies were:
- The unstable trunk which mimics the way that Subversion itself is developed. In this model, development is done on the trunk and a release branch is created around the time of feature completion with the formal promotion process carried out on that branch.
- The stable trunk where development is done on system version branches and the promotion process is also conducted on that branch. The trunk is the branch point where the production releases are merged in and parallel development efforts are branched out.
- The agile release strategy where development is done on individual feature branches and a release branch is created late in the process with the feature branches merged to it that will define that release. The formal promotion process is conducted on the release branch and the production version merged to the trunk as well as to all remaining active feature branches.
When should i create a new branch in SVN?
You should create a new branch when you’re doing development work that is somewhat experimental in nature. So in your scenario definitely create a new branch and not a folder within master. If you created your sandbox work as a directory in the master, it’s going to reside there until you remove it using git. Having dead code sitting in the master branch is not ideal by any means, since it can confuse other developers and may just sit there rotting for the lifetime of the application.
If your team were to experience a bug, you wouldn’t want them to waste time exploring the experimental work to determine if the bug existed within that directory. Creating a new branch allows you to isolate your changes from the master branch. If your experimentation goes well you always have the option to merge your changes into the master branch. If things don’t go so well you can always discard the branch or keep it within your local repository.
Main Only
The Main Only strategy can be folder-based or with the main folder converted to a Branch, to enable additional visibility features. You commit your changes to the main branch and optionally indicate development and release milestones with labels.

Development isolation
When you need to maintain and protect a stable main branch, you can branch one or more dev branches from main. It enables isolation and concurrent development. Work can be isolated in development branches by feature, organization, or temporary collaboration.

Feature isolation
Feature isolation is a special derivation of the development isolation, allowing you to branch one or more feature branches from main, as shown, or from your dev branches.

Release isolation
Release isolation introduces one or more release branches from main. The strategy allows concurrent release management, multiple and parallel releases, and codebase snapshots at release time.
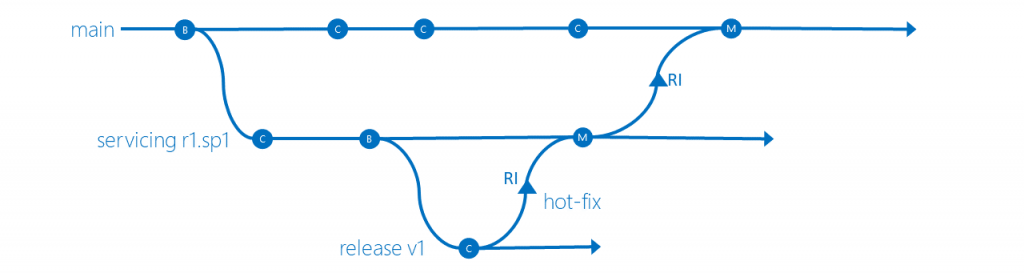
Servicing and release isolation
Servicing and Release Isolation strategy introduces servicing branches. This strategy allows concurrent service management of service packs, and codebase snapshots at release time.
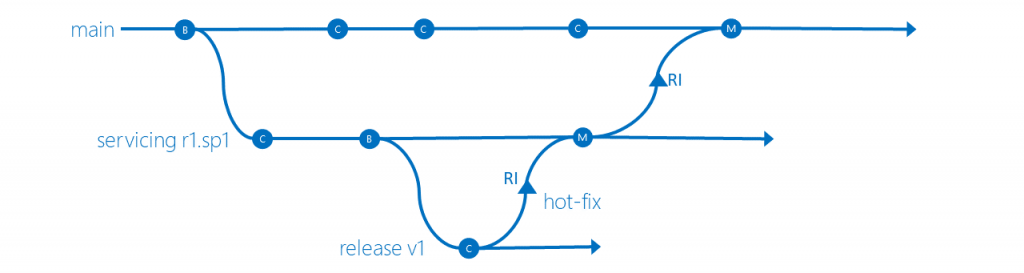
Servicing, hotfix, release isolation
Although not recommended, you can continue to evolve the strategies, by introducing additional hotfix branches and associated release scenarios.
FAQ on SVN Branching and Merging Strategy
Does the number of branches affect performance of the Subversion server?
No, branches are not just cheap in space and fast to create, they are alo just additional paths not unlike directories in the directory structure of your project. Of course, every tool has scalability issues at some point and Subversion logically has its limits, but in practical use, a scalability issue for Subversion around branches has not yet been experienced.
Can we use multiple strategies on one project?
Absolutely, there are many times when you may find a need to mix at least two branching models on the same project. For example, Internet applications may have very frequent releases focused primarily to address defects along with longer term release efforts to address broader feature development. The frequent releases may follow the unstable branch approach where they are worked primarily on the trunk and are branched, sometimes weekly or even more frequently, to do the formal QA to get to the release. The longer running enhancement releases may use the stable trunk philosophy though obviously the trunk isn’t actually stable, but the rest of the strategy is followed.
What strategy is best for a repository with multiple projects?
There is no need to have a single strategy in such a case. Instead one should use the appropriate method for each of the projects. Since each project should have its own top level directory for its branching model, there is no reason to force a particular method on all projects.
How does continuous integration affect branching strategies?
I’d hope that this isn’t the deciding factor in determining an appropriate branching strategy, but certainly the feasibility of continuous integration is impacted by the strategy chosen. With the unstable branch, continuous integration would be focused on the trunk and thus is stable as well as very useful as it identifies issues in the daily development commits. This is still relatively true when you look at the stable branch strategy where there may be multiple system version branches under development at the same time, but each is the focus of the majority of the development commits. The agile release model is the least accessible for this approach because of the number of active branches to try and monitor. That doesn’t mean continuous integration can’t be used but just that it is more difficult to implement and maintain.
Can this model handle parallel development if it only happens occasionally?
Any model can be morphed to handle exceptional situations, but this isn’t recommended. It is important to use a strategy consistently so that everyone understands where to find things during development and historically. That said, we’ve already talked about the potential of using multiple strategies on the same project so that’s certainly a possibility where the parallel development need could be addressed like with the stable trunk strategy.
Do I ever recommend merging from the trunk to the branch?
Never say never, but the situation would be pretty rare. I could potentially envision where a nearly complete bug fix or even an enhancement of importance is completed quickly enough on the trunk that there could be a compelling reason to merge it into the unreleased, but branched version.
How would you handle branches for customers that will have ongoing customizations for individual customers in this model?
Branches for this purpose can really be applied to any of the three basic branches we’ve discussed. The concept is that the base product continues to evolve and the branching strategy addresses that evolution. As production releases are made, the new revisions are merged to the customer-specific branches which contain customizations for that customer. There is also the potential of customer customizations being merged into the base product. The customer branches support the unique nature of customer specific changes while allowing for an upgrade path and the potential of contributing back to the base product.
Version 1.0.1 didn’t get merged back into the trunk, shouldn’t it have been merged back?
Possibly, but I actually didn’t do so on purpose. With all the models, there is the potential that multiple releases are deployed in production and thus need to be supported. Therefore, there is the potential that bug fix releases are being made for multiple releases and merging all of them back to the trunk could mean intertwined versus serial releases. I therefore usually suggest that the actual production releases may be the only ones merged. Obviously, in my diagram that situation didn’t occur so it is a fair question.
There is a merge to the trunk outside of a release point, doesn’t that violate the stable trunk idea?
Yes, that can violate the stable trunk concept, but stability isn’t necessarily limited to just production releases. In this case, the purpose is to have a more up-to-date starting point for the system version branch. How strict you implement the idea of stability is up to you.
Should the development team develop the first version in the trunk or in a release branch?
Since my base principle is keeping it simple, I tend to say do the development on the trunk since there is no reason for creating a branch. The assumption is that parallel development won’t happen until the first release is made and other work won’t be merged until the release. This isn’t being pure to the strategy, but true to the base principle.
In this strategy, is there any attempt to keep the task branches in sync with each other?
No, there really isn’t any way to define how you would keep isolated tasks in sync since there is no idea what will be released together until we get to the definition of the release branch. There is a need to keep the branches sync’d with production releases, but no way to do more.
Is there any reason that an Internet application should NOT be using the agile release method?
Sure, there are still many such applications that are released in a waterfall manner and are unquestionably successful. For example, release agility may not be required if releases are being made frequently enough. Keep in mind that there is more to keep in sync in this model which has to be balanced against any benefits.
Where is the release package built from?
I think the package would be built from the release branch since that’s logically where the promotion model process is conducted, but it can certainly be argued that the testing can be done on the release branch and then the approved revision merged to be tagged from the trunk. My absolute expectation is that you be consistent where you do build and tag.
How can a CM manager make sure all task branches were merged to the release branch?
Today, I would suggest the use of svnmerge.py where merge tracking is recorded in a property for all branch merges. Obviously, this will be easier with 1.5 where the log command can expose this information. Another approach would come from integrating issue management with Subversion where the merges would be reflected in the record for the release.
I’m sure I’ll return to answer some more questions around these branching models and merge tracking before long. Right now, I’m off to help another enterprise successfully implement Subversion.
I’m Rajesh Kumar, a DevOps, SRE, DevSecOps, Cloud, and Platform Engineering expert passionate about sharing practical knowledge, real-world experiences, and industry best practices. I have worked at Cotocus and regularly write about technology, travel, investing, health, product reviews, and digital marketing through my various platforms.
I publish technical articles at DevOps School, travel stories at Holiday Landmark, stock market insights at Stocks Mantra, health and fitness guidance at My Medic Plus, product reviews at TrueReviewNow, and SEO and digital marketing strategies at Wizbrand.
Find Trusted Cardiac Hospitals
Compare heart hospitals by city and services — all in one place.
Explore Hospitals

