- Explain in brief about Elasticsearch?

Elasticsearch Apache Lucene search engine is a database that stores retrieve and manages document-oriented and semi-structured data. It provides real-time search and analytics for structured or unstructured text, numerical or geospatial data.
2. Can you state the stable Elasticsearch version currently available for download?
The latest stable version of Elasticsearch is 7.5.0.
3. Can you please give step by step procedures to start an Elasticsearch server?
The server can be started from the command line.
4. To install Elasticsearch, what software is required as a prerequisite?
Latest JDK 8 or Java version 1.8.0 is recommended as the software required for running Elasticsearch on your device.
5. Name 10 companies that have an Elasticsearch as their search engine and database for their application?
Following are the list of some companies that use Elasticsearch along with Logstash and Kibana:
- Uber
- Instacart
- Slack
- Shopify
- Stack Overflow
- DigitalOcean
- Udemy
- 9GAG
- Wikipedia
- Netflix
- Accenture
- Fujitsu
6. Please explain Elasticsearch Cluster?
It is a group of one or more node instances connected responsible for the distribution of tasks, searching and indexing across all the nodes.
7. What is an index in an Elasticsearch cluster?
An Elasticsearch cluster can contain multiple indices, which are database as compared with a relational database, these indices contain multiple types (tables). The types (tables) contain multiple Documents (records/rows) and these documents contain Properties (columns).
8. What is a Node in Elasticsearch?
A node is an instance of Elasticsearch. Different node types are Data nodes, Master nodes, Client nodes and Ingest nodes.
These are explained as follows:
- Data nodes hold data and perform an operation such as CRUD (Create/Read/Update/Delete), search and aggregations on data.
- Master nodes help in configuration and management to add and remove nodes across the cluster.
- Client nodes send cluster requests to the master node and data-related requests to data nodes,
- Ingest nodes for pre-processing documents before indexing.
9. Can you please define Mapping in an Elasticsearch?
Mapping is the outline of the documents stored in an index. The mapping defines how a document is indexed, how its fields are indexed and stored by Lucene.
10. What is a Document with respect to Elasticsearch?
A document is a JSON document that is stored in Elasticsearch. It is equivalent to a row in a relational database table.
11. Can you define REPLICA and what is the advantage of creating a replica?
A replica is an exact copy of the Shard, used to increase query throughput or achieve high availability during extreme load conditions. These replicas help to efficiently manage requests.
12. Can you explain SHARDS with regards to Elasticsearch?
When the number of documents increases, hard disk capacity, and processing power will not be sufficient, responding to client requests will be delayed. In such a case, the process of dividing indexed data into small chunks is called Shards, which improves the fetching of results during data search.
13. Please explain the procedure to add or create an index in Elasticsearch Cluster?
To add a new index, create an index API option should be used. The parameters required to create the index is Configuration setting of an index, Fields mapping in the index as well as Index aliases.
14. What is the syntax or code to delete an index in Elasticsearch?
You can delete an existing index using the following syntax:
______________________
DELETE /<index_name>
__________________
Code language: HTML, XML (xml)_all or * can be used to remove/delete all the indices
15. Can you tell me the syntax or code to add a Mapping in an Index?
You can add a mapping in an index using the following syntax:
___________________________
POST /_<index_name>/_type/_id
____________________
Code language: HTML, XML (xml)16. What is the syntax or code to retrieve a document by ID in Elasticsearch?
GET API retrieves the specified JSON document from an index.
Syntax:
_______________________________
GET <index_name>/_doc/<_id>
_______________________
Code language: HTML, XML (xml)17. What are the various possible ways in which we can perform a search in Elasticsearch?
Mentioned below are the various possible ways in which we can perform a search in Elasticsearch:
Applying search API across multiple types and multiple indexes: Search API, we can search an entity across multiple types and indices.
Search request using a Uniform Resource Identifier: We can search requests using parameters along with URI i.e. Uniform Resource Identifier.
Search using Query DSL i.e. (Domain Specific Language) within the body: DSL i.e. Domain Specific Language is utilized for JSON request body.
18. Please explain relevancy and scoring in Elasticsearch?
When you search on the internet about say, Apple. It could either display the search results about fruit or company with name as an Apple. You may want to buy fruit online, check the recipe from the fruit or health benefits of eating fruit, apple.
In contrast, you may want to check Apple.com to find the latest product range offered by the company, check Apple Inc.’s stock prices and how a company is performing in NASDAQ in the last 6 months, 1 or 5 years.
Similarly, when we search for a document (a record) from Elasticsearch, you are interested in getting the relevant information that you are looking for. Based on the relevance, the probability of getting the relevant information is calculated by the Lucene scoring algorithm.
The Lucene technology helps to search a particular record i.e. document which is indexed based on the frequency of the term in search appearing in the document, how often its appearance across an index and query which is designed using various parameters.
19. What are the various types of queries that Elasticsearch supports?
Queries are mainly divided into two types: Full Text or Match Queries and Term based Queries.
Text Queries such as basic match, match phrase, multi-match, match phrase prefix, common terms, query-string, simple query string.
Term Queries such as term exists, type, term set, range, prefix, ids, wildcard, regexp and, fuzzy.
20. Please explain the working of aggregation in Elasticsearch?
Aggregations help in the collection of data from the query used in the search. Different types of aggregations are Metrics, Average, Minimum, Maximum, Sum and stats, based on different purposes.
21. Can you compare between Term-based queries and Full-text queries?
Domain Specific Language (DSL) Elasticsearch query which is known as Full-text queries utilizes the HTTP request body, offers the advantage of clear and detailed in their intent, over time it is simpler to tune these queries.
Term based queries utilize the inverted index, a hash map-like data structure that helps to locate text or string from the body of email, keyword or numbers or dates, etc. used in analysis purposes.
22. What is an Elasticsearch Analyzer?
Analyzers are used for Text analysis, it can be either built-in analyzer or custom analyzer. The analyzer consists of zero or more Character filters, at least one Tokenizer and zero or more Token filters.
Character filters break down the stream of string or numerical into characters by stripping out HTML tags, searching the string for key and replacing them with the related value defined in mapping char filter as well as replace the characters based on a specific pattern.
Tokenizer breaks the stream of string into characters, For example, whitespace tokenizer breaks the stream of string while encountering whitespace between characters.
Token filters convert these tokens into lower case, remove from string stop words like ‘a’, ‘an’, ‘the’. or replace characters into equivalent synonyms defined by the filter.
23. Can you tell me data storage functionality in Elasticsearch?
Elasticsearch is a search engine used as storage and searching complex data structures indexed and serialized as a JSON document.
24. Can you list various types of analyzers in Elasticsearch?
Types of Elasticsearch Analyzer are Built-in and Custom.
Built-in analyzers are further classified as below:
- Standard Analyzer: This type of analyzer is designed with standard tokenizer which breaks the stream of string into tokens based on maximum token length configured, lower case token filter which converts the token into lower case and stops token filter, which removes stop words such as ‘a’, ‘an’, ‘the’.
- Simple Analyzer: This type of analyzer breaks a stream of string into a token of text whenever it comes across numbers or special characters. A simple analyzer converts all the text tokens into lower case characters.
- Whitespace Analyzer: This type of analyzer breaks the stream of string into a token of text when it comes across white space between these string or statements. It retains the case of tokens as it was in the input stream.
- Stop Analyzer: This type of analyzer is similar to that of the simple analyzer, but in addition to it removes stop words from the stream of string such as ‘a’, ‘an’, ‘the’. The complete list of stop words in English can be found from the link.
- Keyword Analyzer: This type of analyzer returns the entire stream of string as a single token as it was. This type of analyzer can be converted into a custom analyzer by adding filters to it.
- Pattern Analyzer: This type of analyzer breaks the stream of string into tokens based on the regular expression defined. This regular expression acts on the stream of string and not on the tokens.
- Language Analyzer: This type of analyzer is used for specific language texts analysis. There are plug-ins to support language analyzers. These plug-ins are Stempel, Ukrainian Analysis, Kuromoji for Japanese, Nori for Korean and Phonetic plugins. There are additional plug-ins for Indian as well as non-Indian languages such as Asian languages ( Example, Japanese, Vietnamese, Tibetan) analyzers.
25. What are the important features of Elasticsearch?
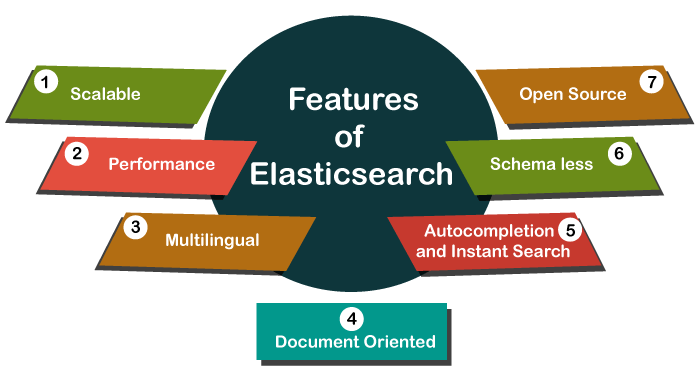
Here are important features of Elasticsearch:
- An open-source search server written using Java.
- Used to index any kind of heterogeneous data
- Has REST API web-interface with JSON output
- Full-Text Search
- Near Real-Time (NRT) search
- Sharded, replicated searchable, JSON document store.
- Schema-free, REST & JSON based distributed document store
- Multi-language & Geolocation support
26. Explain Index?
A node is an elastic search Instance. It is created when an elasticsearch instance begins.
27. What is a document in Elastic Search?
In an Elastic search, a document is a basic unit of information that can be indexed. It is expressed in JSON (key: value) pair. ‘{“user”: “nullcon”}’. Every single Document is associated with a type and a unique id.
28. What are the important advantages of Elastic Search?

Here are the important advantages of Elasticsearch:
- Store schema-less data and also creates a schema for your data.
- Manipulate your data record by record with the help of Multi-document APIs
- Perform filtering and querying your data for insights
- Based on Apache Lucene and provides RESTful API
- It provides horizontal scalability, reliability, and multitenant capability for real-time use of indexing.
- Helps you to scale vertically and horizontally
29. Explain Tokenizer in ElasticSearch?
A Tokenizer breakdown fields which values of a document into a stream. Inverted indexes are created and updated by using these values. After that, these stream of values are stored in the document.
30. What Are The Main Operations You Can Perform On A Document?
Here, are important operation performed on documents:
- Indexing a document
- Fetching documents
- Updating documents
- Deleting documents
31. What are the primary operations performed in a Document?
Here, are important operation performed on documents:
- Indexing a document
- Fetching documents
- Updating documents
- Deleting documents
32. What are the various ways of searching in Elasticsearch?
We have different ways of searching in Elasticsearch:
- Multi-index, Multitype search: A user can search APIs that can be applied across several indices through a multi-index support system.
- URI (uniform resource identifier) search: A user can execute a search request using a URI by providing the requested parameters.
- Request body search: A search request needs to be executed by a search DSL.
33. Where is Elastic search stored?
Elastic search results are stored in a distributed document in different directories. Also, a user can retrieve complex data structures that are serialized as JSON documents.
34. What are some of the configuration management tool supported by Elasticsearch?
Some important configuration management tool supported by Elasticsearch is as follows:
- Puppet – puppet-elastic search
- Chef – cookbook-elastic search
- Ansible – ansible-elastic search
35. What is Apache Lucene?
Apache Lucene is an open-source information retrieval software library written in Java language.
36. What is NRT in Elasticsearch?

NRT stands for Near Real-Time Search. It is a near real-time search platform ie. there will be a slight latency (approx. one second) from indexing a document until it becomes searchable.
37. List out different commands available in Elasticsearch cat API?
Command using with cat API are:
- Cat aliases, cat field data, cat allocation, cat count
- Cat health, pending tasks, cat plugins, cat indices, cat master, cat recovery
- cat repositories, cat templates, cat snapshots
38. What do you mean by ingest node?
Ingest node is used to pre-process the documents before the actual document indexing is done. It intercepts bulk and index requests and applies transformations to pass the documents back to the bulk API and index.
39. What is Single document APIs in Elasticsearch?
- Get API
- Index API
- Delete API
- Update API
40. What do you mean by fuzzy query Elasticsearch?
The fuzzy query returns the document that contains terms similar to the search terms. To find similar terms, a fuzzy query creates a set of possible variations of search terms within a specified edit distance. When a user searches for some terms using a fuzzy query, the system returns the most resembling terms for each expansion.
41. Can you name five companies that have an elastic search as their search engine and database for their application?
- Uber
- Stack Overflow
- DigitalOcean
- Udemy
- Wikipedia
- Netflix
42. What is the syntax/code to retrieve a document by ID in Elasticsearch?
GET API fetches the specified JSON document from an index.
Syntax:
__________________________-
GET <index_name>/_doc/<_id>
____________________
Code language: HTML, XML (xml)43. Where and how Kibana will be useful in Elasticsearch?
Kibana is part of the ELK Stack – log analysis solution. It is an open-source visualization tool used to analyze data available in graph formats such as pie bar, coordinate map, line, etc.
44. How Beats can be used with Elasticsearch?
Beats is an open-source tool used to transfer data to Elasticsearch where data is processed before being viewed using Kibana. Data such as audit data, log files, window event logs, cloud data, and network traffic are transported.
45. Does ElasticSearch have a schema?
Yes, ElasticSeach can have mappings that can be used to enforce a schema on documents.
46. What is a Tokenizer in ElasticSearch?
A Tokenizer breakdown fields values of a document into a stream, and inverted indexes are created and updated using these values, and these stream of values are stored in the document.
47. What is a Filter in ElasticSearch?
A Filter is all about implementing some conditions in the query to reduce the matching result set. When we use a query in Elasticsearch, the query computes a relevance score for matching the documents. But in some situations, we don’t need relevance scores when the document falls in the range of two provided timestamps.
So, for this yes/no criteria, we use Filters. We use Filters for matching particular criteria, and they are cacheable to allow faster execution. The Token filters receive a flow of tokens from a tokenizer, and they can change, add, and delete the tokens.
48. What is the query language of ElasticSearch?
Elasticsearch provides a query DSL(Domain Specific Language) on the basis of JSON for defining the queries. Query DSL contains two kinds of clauses:
1) Leaf Query Clauses
Leaf Query Clauses search for a specific value in a specific field, like the term, range, or match queries.
2) Compound Query Clauses
Compound Query Clauses enclose other compound or leaf queries, and we use them for logically combining queries.
49. Who developed Elasticsearch and when?
Elasticsearch was first launched in Feb 2010. It is developed by Shay Banon. Elasticsearch is licensed under Apache 2.0.
50. What is the is use of attributes- enabled, index and store ?
- The enabled attribute applies to various ElasticSearch specific/created fields such as _index and _size. User-supplied fields do not have an “enabled” attribute.
- Store means the data is stored by Lucene will return this data if asked. Stored fields are not necessarily searchable. By default, fields are not stored, but full source is. Since you want the defaults (which makes sense), simply do not set the store attribute.
- The index attribute is used for searching. Only indexed fields can be searched. The reason for the differentiation is that indexed fields are transformed during analysis, so you cannot retrieve the original data if it is required.
I’m Rajesh Kumar, a DevOps, SRE, DevSecOps, Cloud, and Platform Engineering expert passionate about sharing practical knowledge, real-world experiences, and industry best practices. I have worked at Cotocus and regularly write about technology, travel, investing, health, product reviews, and digital marketing through my various platforms.
I publish technical articles at DevOps School, travel stories at Holiday Landmark, stock market insights at Stocks Mantra, health and fitness guidance at My Medic Plus, product reviews at TrueReviewNow, and SEO and digital marketing strategies at Wizbrand.
Find Trusted Cardiac Hospitals
Compare heart hospitals by city and services — all in one place.
Explore Hospitals