Short intro About Apache Kafka
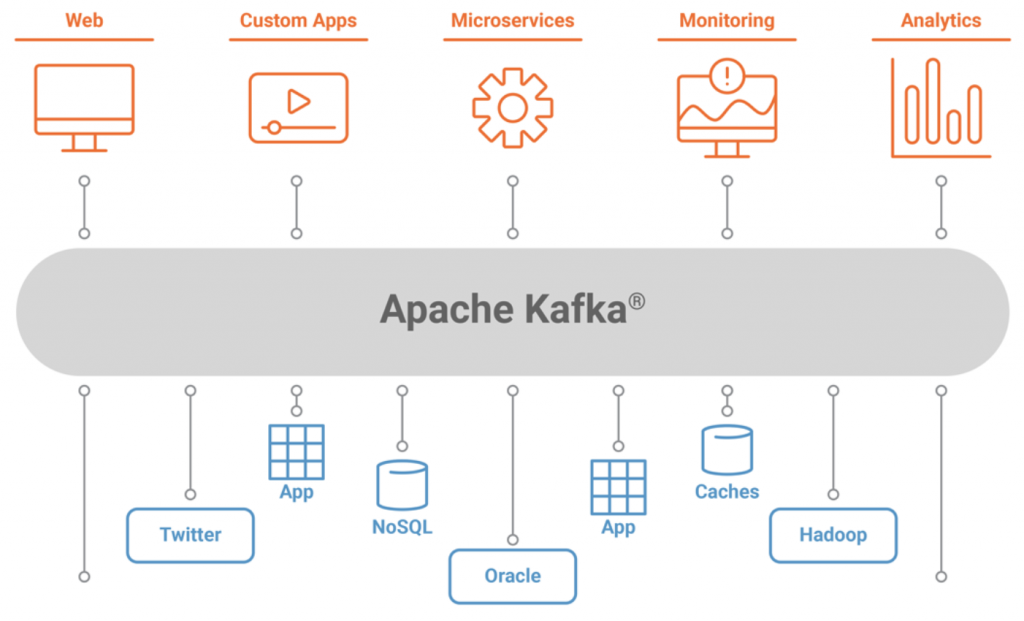
Apache Kafka is a popular tool for developers because it is easy to pick up and provides a powerful event streaming platform complete with 4 APIs: Producer, Consumer, Streams, and Connect.
Often, developers will begin with a single-use case. This could be using Apache Kafka as a message buffer to protect a legacy database that can’t keep up with today’s workloads or using the Connect API to keep the said database in sync with an accompanying search indexing engine, to process data as it arrives with the Streams API to surface aggregations right back to your application.
In short, Apache Kafka and its APIs make building data-driven apps and managing complex back-end systems simple. Kafka gives you peace of mind knowing your data is always fault-tolerant, replayable, and real-time. Helping you quickly build by providing a single event streaming platform to process, store, and connect your apps and systems with real-time data.
let’s move to questions and answers,
1. What is Apache Kafka?
Answer: Apache Kafka is a publish-subscribe open-source message broker application. This messaging application was coded in “Scala”. Basically, this project was started by the Apache software. Kafka’s design pattern is mainly based on the design of the transactional log.
2. Explain the role of the offset.
Answer: There is a sequential ID number given to the messages in the partitions what we call, an offset. So, to identify each message in the partition uniquely, we use these offsets.
3. What is the role of the ZooKeeper in Kafka?
Answer: Apache Kafka is a distributed system is built to use Zookeeper. Although, Zookeeper’s main role here is to build coordination between different nodes in a cluster. However, we also use Zookeeper to recover from previously committed offset if any node fails because it works as a periodically commit offset.
4. What is a Consumer Group?
Answer: The concept of Consumer Groups is exclusive to Apache Kafka. Basically, every Kafka consumer group consists of one or more consumers that jointly consume a set of subscribed topics.
5. What are main APIs of Kafka?
Answer: Apache Kafka has 4 main APIs:
- Producer API
- Consumer API
- Streams API
- Connector API
6. Explain the concept of Leader and Follower.
Answer: In every partition of Kafka, there is one server that acts as the Leader, and none or more servers play the role of Followers.
7. What roles do Replicas and the ISR play?
Answer: Basically, a list of nodes that replicate the log is Replicas. Especially, for a particular partition. However, they are irrespective of whether they play the role of the Leader.
In addition, ISR refers to In-Sync Replicas. On defining ISR, it is a set of message replicas that are synced to the leaders.
8. What ensures load balancing of the server in Kafka?
Answer: The main role of the Leader is to perform the task of all read and write requests for the partition, whereas Followers passively replicate the leader.
Hence, at the time of Leader failure, one of the Followers take over the role of the Leader. Basically, this entire process ensures load balancing of the servers.
9. Why are Replications critical in Kafka?
Answer: Because of Replication, we can be sure that published messages are not lost and can be consumed in the event of any machine error, program error, or frequent software upgrades.
10. If a Replica stays out of the ISR for a long time, what does it signify?
Answer: Simply, it implies that the Follower cannot fetch data as fast as data accumulated by the Leader.
11. In the Producer, when does QueueFullException occur?
Answer: whenever the Kafka Producer attempts to send messages at a pace that the Broker cannot handle at that time QueueFullException typically occurs. However, to collaboratively handle the increased load, users will need to add enough brokers, since the Producer doesn’t block.
12. What is the main difference between Kafka and Flume?.

Answer: The main difference between Kafka and Flume are:
- Types of tool
Apache Kafka– As Kafka is a general-purpose tool for both multiple producers and consumers.
Apache Flume– Whereas, Flume is considered as a special-purpose tool for specific applications.
- Replication feature
Apache Kafka– Kafka can replicate the events.
Apache Flume- whereas, Flume does not replicate the events.
13. Explain the role of the Kafka Producer API.
Answer: An API that permits an application to publish a stream of records to one or more Kafka topics is what we call Producer API.
14. Is Apache Kafka is a distributed streaming platform? if yes, what you can do with it?
Answer: Undoubtedly, Kafka is a streaming platform. It can help:
- To push records easily
- Also, can store a lot of records without giving any storage problems
- Moreover, it can process the records as they come in
15. What is the purpose of the retention period in the Kafka cluster?
Answer: However, the retention period retains all the published records within the Kafka cluster. It doesn’t check whether they have been consumed or not. Moreover, the records can be discarded by using a configuration setting for the retention period. And, it results as it can free up some space.
16. What can you do with Kafka?
Answer: It can perform in several ways, such as:
>>In order to transmit data between two systems, we can build a real-time stream of data pipelines with it.
>>Also, we can build a real-time streaming platform with Kafka, that can actually react to the data.
17. Explain the maximum size of a message that can be received by Kafka?
Answer: The maximum size of a message that can be received by Kafka is approx. 1000000 bytes.
18. What does ISR stand in Kafka’s environment?
Answer: ISR refers to In sync replicas. These are generally classified as a set of message replicas that are synced to be leaders.
19. What are the types of traditional methods of message transfer?
Answer: Basically, there are two methods of the traditional massage transfer method, such as:
Queuing: It is a method in which a pool of consumers may read a message from the server and each message goes to one of them.
Publish-Subscribe: Whereas in Publish-Subscribe, messages are broadcasted to all consumers.
20. What is Geo-Replication in Kafka?
Answer: For our cluster, Kafka MirrorMaker offers geo-replication. Basically, messages are replicated across multiple data centers or cloud regions, with MirrorMaker.So, it can be used in active/passive scenarios for backup and recovery; or also to place data closer to our users, or support data locality requirements.
21. Explain Multi-tenancy?
Answer: We can easily deploy Kafka as a multi-tenant solution. However, by configuring which topics can produce or consume data, Multi-tenancy is enabled. Also, it provides operations support for quotas.
22. Explain the role of Streams API?
Answer: An API that permits an application to act as a stream processor, and also consume an input stream from one or more topics and produce an output stream to one or more output topics, moreover, transforming the input streams to output streams effectively, is what we call Streams API
23. What is the role of Consumer API?.
Answer: An API that permits an application to subscribe to one or more topics and also to process the stream of records produced to them is what we call Consumer API.
24. Explain Producer?
Answer: The main role of Producers is to publish data on the topics of their choice. Basically, its duty is to select the record to assign to partition within the topic.
25. What is the role of Connector API?
Answer: An API that permits to run as well as build the reusable producers or consumers which connect Kafka topics to existing applications or data systems is what we call the Connector API.
26. Explain how to Tune Kafka for Optimal Performance.
Answer: So, ways to tune Apache Kafka is to tune its several components:
- Tuning Kafka Producers
- Kafka Brokers Tuning
- Tuning Kafka Consumers
27. State Disadvantages of Apache Kafka.
Answer: Limitations of Kafka are:
- No Complete Set of Monitoring Tools
- Issues with Message Tweaking
- Not support wildcard topic selection
- Lack of Pace
28. Some of the most notable applications of Kafka.
Answer: Some of the real-time applications are:
- Netflix
- Mozilla
- Oracle
29. What do you mean by Stream Processing in Kafka?
Answer: The type of processing of data continuously, in real-time, concurrently, and in a record-by-record fashion is what we call Kafka Stream processing.
30. Features of Kafka Stream.
Answer: Some best features of Kafka Stream are
- Kafka Streams are highly scalable and fault-tolerant.
- Kafka deploys to containers, VMs, bare metal, cloud.
- We can say, Kafka streams are equally viable for small, medium, & large use cases.
- Also, it is fully in integration with Kafka security.
- Write standard Java applications.
- Exactly-once processing semantics.
- Moreover, there is no need for a separate processing cluster.
31. What are the types of System tools?
Answer: There are three types of System tools:
- Kafka Migration Tool
It helps to migrate a broker from one version to another.
- Mirror Maker
Mirror Maker tool helps to offer to mirror of one Kafka cluster to another.
- Consumer Offset Checker
For the specified set of Topics as well as Consumer Group, it shows Topic, Partitions, Owner.
32. What are Replication Tool and their types?
Answer:
For the purpose of stronger durability and higher availability, a replication tool is available here. Its types are −
- Create Topic Tool
- List Topic Tool
- Add Partition Tool
33. State one best feature of Kafka.
Answer: The best feature of Kafka is “Variety of Use Cases”.
It means Kafka is able to manage the variety of use cases which are very common for a Data Lake. For Example log aggregation, web activity tracking, and so on.
34. What are the Guarantees provided by Kafka?
Answer: They are:
- The order will be the same for both the Messages sent by a producer to a particular topic partition. That
- Moreover, the consumer instance sees records in the order in which they are stored in the log.
- Also, we can tolerate up to N-1 server failures, even without losing any records committed to the log.
35. What is a broker in Kafka?
Answer: A Kafka cluster contains one or more servers that are known as brokers. A broker works as a container that holds multiple topics, with various partitions. A broker in a cluster can only be identified by the integer ID associated with it. Connection with any one broker in a cluster implies a connection with the whole cluster. Brokers in Kafka do not contain the complete data, but they know about other brokers, topics, and partitions of the cluster.
36. Explain fault tolerance in Kafka.
Answer: In Kafka, the partition data is copied to other brokers, which are known as replicas. If there is a point of failure in the partition data in one node, then there are other nodes that will provide a backup and ensure that the data is still available. This is how Kafka allows fault tolerance.
37. What is meant by multi-tenancy in Kafka?
Answer: Multi-tenancy refers to the mode of operation of software where there are multiple instances of one or multiple applications operating in a shared environment independent from each other. The instances are said to be logically isolated but physically integrated. For a system to support multi-tenancy, the level of logical isolation must be complete, but the level of physical integration may vary. Kafka can be said to be multi-tenant as it allows for the configuration of different topics for which data can be consumed or produced on the same cluster.
38. Explain the topic replication factor
Answer: The topic replication factor refers to the number of copies of the topic that are present over multiple brokers. The replication factor should be greater than 1 for fault tolerance. In such cases, there will be a replica of the data in another broker from where the data can be retrieved if necessary..
39. Why is Kafka preferred over traditional messaging techniques?
Answer:
- Unlike traditional message brokers, Kafka is more scalable as it allows the addition of more partitions.
- Kafka does not slow down with the addition of new consumers, unlike traditional messaging systems where both the queue and topic performance sees a decline in performance with a rise in the number of consumers.
- In Kafka, the messages contain a key-value pair. The key is used for partitioning purposes and is used to place related messages in the same partition. Traditional messaging systems usually do not have any such method of grouping messages.
- Kafka comes with a checksum method that is used to detect corruption of messages on the various servers; traditional message brokers have no such way of verifying whether message integrity is maintained.
- Messages in Kafka are not deleted once they are consumed, and are available for a period of time as specified by the retention time. This also makes it possible for consumers to retrieve any message once more and reprocess it. In traditional messaging systems, the broker would either delete a successfully processed message or try to re-deliver an unprocessed one which could cause performance degradation due to messages getting stuck in the queue.
40. Mention some of the system tools available in Kafka.
Answer: The three main system tools available in Kafka are:
Kafka Migration Tool − This tool is used to migrate the data in a Kafka cluster from one version to another.
Mirror Maker − This tool is used to copy data from one Kafka cluster to another.
Consumer Offset Checker − This tool is used to display the Consumer Group, Topic, Partitions, Off-set, logSize, Owner for specific sets of Topics and Consumer Group.
41. What is the optimal number of partitions for a topic?
Answer: The optimal number of partitions a topic should be divided into must be equal to the number of consumers.
42. What is the Kafka MirrorMaker?
Answer: The MirrorMaker is a stand-alone tool that allows data to be copied from one Apache Kafka cluster to another. The MirrorMaker will read data from topics in the original cluster and write the topics to a destination cluster with the same topic name. The source and destination clusters are independent entities and can have different numbers of partitions and varying offset values.
43. What are name restrictions for Kafka topics?
Answer: According to Kafka, there are some legal rules to be followed to name topics, which are as follows:
- The maximum length is 255 characters (symbols and letters). The length has been reduced from 255 to 249 in Kafka 0.10
- . (dot), _ (underscore), – (hyphen) can be used. However, topics with dot (.) and underscore ( _) could cause some confusion with internal data structures and hence, it is advisable to use either but not both.
44. What is the Confluent Replicator?
Answer: The Confluent Replicator allows easy and reliable replication of topics from a source cluster to a destination cluster. It continuously copies messages from the source to the destination and even assigns the same names to the topics in the destination cluster.
45. Where is the meta-information about topics stored in the Kafka cluster?
Answer: Currently, in Apache Kafka, meta-information about topics is stored in the ZooKeeper. Information regarding the location of the partitions and the configuration details related to a topic are stored in the ZooKeeper in a separate Kafka cluster.
46. How can large messages be sent in Kafka?
Answer: By default, the largest size of a message that can be sent in Kafka is 1MB. In order to send larger messages using Kafka, a few properties have to be adjusted. Here are the configuration details that have to be updated
At the Consumer end – fetch.message.max.bytes
At the Broker, end to create replica– replica.fetch.max.bytes
At the Broker, the end to create a message – message.max.bytes
At the Broker end for every topic – max.message.bytes
47. Explain the scalability of Kafka.
Answer: In software terms, the scalability of an application is its ability to maintain its performance when it is exposed to changes in application and processing demands. In Kafka, the messages corresponding to a particular topic are divided into partitions. This allows the topic size to be scaled beyond the size that will fit on a single server. Allowing a topic to be divided into partitions ensures that Kafka can guarantee load balancing over multiple consumer processes. In addition, the concept of consumer groups in Kafka also contributes to making it more scalable. In a consumer group, a particular partition is consumed by only one consumer in the group. This aids in the parallelism of consuming multiple messages of a topic.
48. Explain how topics can be added and removed.
Answer:
To create a topic:
kafka/bin/kafka-topics.sh –create \
–zookeeper localhost:2181 \
–replication-factor [replication factor] \
–partitions [number_of_partitions] \
–topic [unique-topic-name]
*To Delete a topic:
Go to ${kafka_home}/config/server.properties, and add the below line:
Delete.topic.enable = true
* Restart the Kafka server with the new configuration:
${kafka_home}/bin/kafka-server-start.sh ~/kafka/config/server.properties
* Delete the topic:
${kafka_home}/bin/kafka-topics.sh --delete --zookeeper localhost:2181 --topic topic-nameCode language: JavaScript (javascript)49. What is the need for message compression in Kafka?
Answer: Message compression in Kafka does not require any changes in the configuration of the broker or the consumer. It is beneficial for the following reasons:
- Due to reduced size, it reduces the latency in which messages are sent to Kafka.
- Reduced bandwidth allows the producers to send more net messages to the broker.
- When the data is stored in Kafka via cloud platforms, it can reduce the cost in cases where the cloud services are paid.
- Message compression leads to reduced disk load which will lead to faster read and write operations.
50. What are some disadvantages of message compression in Kafka?
Answer:
- Producers end up using some CPU cycles for compression.
- Consumers use some CPU cycles for decompression.
- Compression and decompression result in greater CPU demand.
I’m Rajesh Kumar, a DevOps, SRE, DevSecOps, Cloud, and Platform Engineering expert passionate about sharing practical knowledge, real-world experiences, and industry best practices. I have worked at Cotocus and regularly write about technology, travel, investing, health, product reviews, and digital marketing through my various platforms.
I publish technical articles at DevOps School, travel stories at Holiday Landmark, stock market insights at Stocks Mantra, health and fitness guidance at My Medic Plus, product reviews at TrueReviewNow, and SEO and digital marketing strategies at Wizbrand.
Find Trusted Cardiac Hospitals
Compare heart hospitals by city and services — all in one place.
Explore Hospitals