A quick discussion about Hadoop
Apache Hadoop is an open-source framework that is used to efficiently store and process large datasets ranging in size from gigabytes to petabytes of data. Instead of using one large computer to store and process the data, Hadoop allows clustering multiple computers to analyze massive datasets in parallel more quickly.
1. What are the different vendor-specific distributions of Hadoop?
Answer: The different vendor-specific distributions of Hadoop are Cloudera, MAPR, Amazon EMR, Microsoft Azure, IBM InfoSphere, and Hortonworks (Cloudera).
2. What are the different Hadoop configuration files?
Answer: The different Hadoop configuration files include:
- Hadoop-env.sh
- mapred-site.xml
- core-site.xml
- yarn-site.xml
- hdfs-site.xml
- Master and Slaves
3. What are the three modes in which Hadoop can run?
Answer: The three modes in which Hadoop can run are :
- Standalone mode: This is the default mode. It uses the local FileSystem and a single Java process to run the Hadoop services.
- Pseudo-distributed mode: This uses a single-node Hadoop deployment to execute all Hadoop services.
- Fully-distributed mode: This uses separate nodes to run Hadoop master and slave services.
4. What are the differences between regular FileSystem and HDFS?
Answer:
Regular FileSystem: In a regular FileSystem, data is maintained in a single system. If the machine crashes, data recovery is challenging due to low fault tolerance. Seek time is more and hence it takes more time to process the data.
HDFS: Data is distributed and maintained on multiple systems. If a DataNode crashes, data can still be recovered from other nodes in the cluster. Time taken to read data is comparatively more, as there is local data read to the disc and coordination of data from multiple systems.
5. What are the two types of metadata that a NameNode server holds?
Answer: The two types of metadata that a NameNode server holds are:
Metadata in Disk – This contains the edit log and the FSImage
Metadata in RAM – This contains the information about DataNodes
6. How can you restart NameNode and all the daemons in Hadoop?
Answer:
The following commands will help you restart NameNode and all the daemons:
You can stop the NameNode with ./sbin /Hadoop-daemon.sh stop NameNode command and then start the NameNode using ./sbin/Hadoop-daemon.sh start NameNode command.
You can stop all the daemons with ./sbin /stop-all.sh command and then start the daemons using the ./sbin/start-all.sh command.
7. Which command will help you find the status of blocks and FileSystem health?
Answer:
To check the status of the blocks, use the command:
hdfs fsck -files -blocks
To check the health status of FileSystem, use the command:
hdfs fsck / -files –blocks –locations > dfs-fsck.log
8. What would happen if you store too many small files in a cluster on HDFS?
Answer: Storing several small files on HDFS generates a lot of metadata files. To store this metadata in the RAM is a challenge as each file, block, or directory takes 150 bytes for metadata. Thus, the cumulative size of all the metadata will be too large.
9. How do you copy data from the local system onto HDFS?
Answer:
The following command will copy data from the local file system onto HDFS:
hadoop fs –copyFromLocal [source] [destination]
Example: hadoop fs –copyFromLocal /tmp/data.csv /user/test/data.csv
In the above syntax, the source is the local path and destination is the HDFS path. Copy from the local system using a -f option (flag option), which allows you to write the same file or a new file to HDFS.
10. Is there any way to change the replication of files on HDFS after they are already written to HDFS?
Answer: Yes, the following are ways to change the replication of files on HDFS:
We can change the dfs.replication value to a particular number in the $HADOOP_HOME/conf/hadoop-site.xml file, which will start replicating to the factor of that number for any new content that comes in.
If you want to change the replication factor for a particular file or directory, use:
$HADOOP_HOME/bin/Hadoop dfs –setrep –w4 /path of the file
Example: $HADOOP_HOME/bin/Hadoop dfs –setrep –w4 /user/temp/test.csv
11. Is it possible to change the number of mappers to be created in a MapReduce job?
Answer:
By default, you cannot change the number of mappers, because it is equal to the number of input splits. However, there are different ways in which you can either set a property or customize the code to change the number of mappers.
For example, if you have a 1GB file that is split into eight blocks (of 128MB each), there will only be only eight mappers running on the cluster. However, there are different ways in which you can either set a property or customize the code to change the number of mappers.
12. What is speculative execution in Hadoop?
Answer:
If a DataNode is executing any task slowly, the master node can redundantly execute another instance of the same task on another node. The task that finishes first will be accepted, and the other task would be killed. Therefore, speculative execution is useful if you are working in an intensive workload kind of environment.
The following image depicts the speculative execution:
From the above example, you can see that node A has a slower task. A scheduler maintains the resources available, and with speculative execution turned on, a copy of the slower task runs on node B. If the node A task is slower, then the output is accepted from node B.
13. What are the major configuration parameters required in a MapReduce program?
Answer:
We need to have the following configuration parameters:
- Input location of the job in HDFS
- Output location of the job in HDFS
- Input and output formats
- Classes containing a map and reduce functions
- JAR file for mapper, reducer, and driver classes
14. What is the role of the OutputCommitter class in a MapReduce job?
Answer: As the name indicates, OutputCommitter describes the commit of task output for a MapReduce job.
Example: org.apache.hadoop.mapreduce.OutputCommitter
public abstract class OutputCommitter extends OutputCommitter
MapReduce relies on the OutputCommitter for the following:
- Set up the job initialization
- Cleaning up the job after the job completion
- Set up the task’s temporary output
- Check whether a task needs a commit
- Committing the task output
- Discard the task commit
15. Explain the process of spilling in MapReduce.
Answer: Spilling is a process of copying the data from memory buffer to disk when the buffer usage reaches a specific threshold size. This happens when there is not enough memory to fit all of the mapper output. By default, a background thread starts spilling the content from memory to disk after 80 percent of the buffer size is filled.
For a 100 MB size buffer, the spilling will start after the content of the buffer reaches a size of 80 MB.
16. How can you set the mappers and reducers for a MapReduce job?
Answer:
The number of mappers and reducers can be set in the command line using:
-D mapred.map.tasks=5 –D mapred.reduce.tasks=2
In the code, one can configure JobConf variables:
job.setNumMapTasks(5); // 5 mappers
job.setNumReduceTasks(2); // 2 reducers
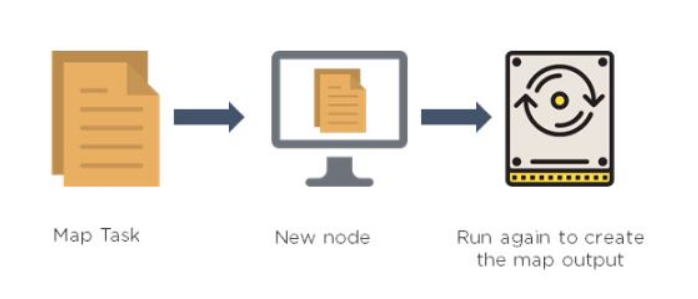
17. What happens when a node running a map task fails before sending the output to the reducer?
Answer: If this ever happens, map tasks will be assigned to a new node, and the entire task will be rerun to re-create the map output. In Hadoop v2, the YARN framework has a temporary daemon called application master, which takes care of the execution of the application. If a task on a particular node failed due to the unavailability of a node, it is the role of the application master to have this task scheduled on another node.
18. Can we write the output of MapReduce in different formats?
Answer: Yes. Hadoop supports various input and output File formats, such as:
- TextOutputFormat – This is the default output format and it writes records as lines of text.
- SequenceFileOutputFormat – This is used to write sequence files when the output files need to be fed into another MapReduce job as input files.
- MapFileOutputFormat – This is used to write the output as map files.
- SequenceFileAsBinaryOutputFormat – This is another variant of SequenceFileInputFormat. It writes keys and values to a sequence file in binary format.
- DBOutputFormat – This is used for writing to relational databases and HBase. This format also sends the reduced output to a SQL table.
19. What benefits did YARN bring in Hadoop 2.0 and how did it solve the issues of MapReduce v1?
Answer:
In Hadoop v1, MapReduce performed both data processing and resource management; there was only one master process for the processing layer known as JobTracker. JobTracker was responsible for resource tracking and job scheduling.
Managing jobs using a single JobTracker and utilization of computational resources was inefficient in MapReduce 1. As a result, JobTracker was overburdened due to handling, job scheduling, and resource management. Some of the issues were scalability, availability issue, and resource utilization. In addition to these issues, the other problem was that non-MapReduce jobs couldn’t run in v1.
To overcome this issue, Hadoop 2 introduced YARN as the processing layer. In YARN, there is a processing master called ResourceManager. In Hadoop v2, you have ResourceManager running in high availability mode. There are node managers running on multiple machines, and a temporary daemon called application master. Here, the ResourceManager is only handling the client connections and taking care of tracking the resources.
In Hadoop v2, the following features are available:
Scalability – You can have a cluster size of more than 10,000 nodes and you can run more than 100,000 concurrent tasks.
Compatibility – The applications developed for Hadoop v1 run on YARN without any disruption or availability issues.
Resource utilization – YARN allows the dynamic allocation of cluster resources to improve resource utilization.
Multitenancy – YARN can use open-source and proprietary data access engines, as well as perform real-time analysis and run ad-hoc queries.
20. Which of the following has replaced JobTracker from MapReduce v1?
Answer:
- NodeManager
- ApplicationManager
- ResourceManager
- Scheduler
- The answer is ResourceManager. It is the name of the master process in Hadoop v2.
21. Write the YARN commands to check the status of an application and kill an application.
Answer: The commands are as follows:
a) To check the status of an application:
yarn application -status ApplicationID
b) To kill or terminate an application:
yarn application -kill ApplicationID
22. Can we have more than one ResourceManager in a YARN-based cluster?
Answer:
Yes, Hadoop v2 allows us to have more than one ResourceManager. You can have a high availability YARN cluster where you can have an active ResourceManager and a standby ResourceManager, where the ZooKeeper handles the coordination.
There can only be one active ResourceManager at a time. If an active ResourceManager fails, then the standby ResourceManager comes to the rescue.

23. What happens if a ResourceManager fails while executing an application in a high availability cluster?
Answer: In a high availability cluster, there are two ResourceManagers: one active and the other standby. If a ResourceManager fails in the case of a high availability cluster, the standby will be elected as active and instructs the ApplicationMaster to abort. The ResourceManager recovers its running state by taking advantage of the container statuses sent from all node managers.
24. What are the different schedulers available in YARN?
Answer:
The different schedulers available in YARN are:
FIFO scheduler – This places applications in a queue and runs them in the order of submission (first in, first out). It is not desirable, as a long-running application might block the small running applications
Capacity scheduler – A separate dedicated queue allows the small job to start as soon as it is submitted. The large job finishes later compared to using the FIFO scheduler
Fair scheduler – There is no need to reserve a set amount of capacity since it will dynamically balance resources between all the running jobs
25. In a cluster of 10 DataNodes, each having 16 GB RAM and 10 cores, what would be the total processing capacity of the cluster?
Answer: Every node in a Hadoop cluster will have one or multiple processes running, which would need RAM. The machine itself, which has a Linux file system, would have its own processes that need a specific amount of RAM usage. Therefore, if you have 10 DataNodes, you need to allocate at least 20 to 30 percent towards the overheads, Cloudera-based services, etc. You could have 11 or 12 GB and six or seven cores available on every machine for processing. Multiply that by 10, and that’s your processing capacity.
26. What are the different components of a Hive architecture?
Answer: The different components of the Hive are:
User Interface: This calls the execute interface to the driver and creates a session for the query. Then, it sends the query to the compiler to generate an execution plan for it
Metastore: This stores the metadata information and sends it to the compiler for the execution of a query
Compiler: This generates the execution plan. It has a DAG of stages, where each stage is either a metadata operation, a map, or reduces a job or operation on HDFS
Execution Engine: This acts as a bridge between the Hive and Hadoop to process the query. Execution Engine communicates bidirectionally with Metastore to perform operations, such as creating or dropping tables.
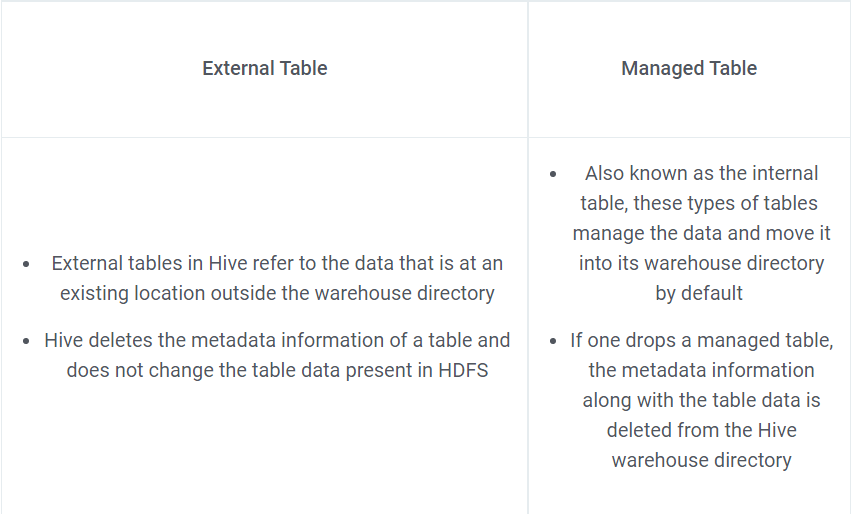
27. What is the difference between an external table and a managed table in Hive?
Answer:
28. What is a partition in Hive and why is partitioning required in Hive
Answer:
Partition is a process for grouping similar types of data together based on columns or partition keys. Each table can have one or more partition keys to identify a particular partition.
Partitioning provides granularity in a Hive table. It reduces the query latency by scanning only relevant partitioned data instead of the entire data set. We can partition the transaction data for a bank based on month — January, February, etc. Any operation regarding a particular month, say February, will only have to scan the February partition, rather than the entire table data.
29. What are the components used in Hive query processors?
Answer: The components used in Hive query processors are:
- Parser
- Semantic Analyzer
- Execution Engine
- User-Defined Functions
- Logical Plan Generation
- Physical Plan Generation
- Optimizer
- Operators
- Type checking
30. Why does Hive not store metadata information in HDFS?
Answer: We know that the Hive’s data is stored in HDFS. However, the metadata is either stored locally or it is stored in RDBMS. The metadata is not stored in HDFS, because HDFS read/write operations are time-consuming. As such, Hive stores metadata information in the megastore using RDBMS instead of HDFS. This allows us to achieve low latency and is faster.
31. What are the different ways of executing a Pig script?
Answer: The different ways of executing a Pig script are as follows:
- Grunt shell
- Script file
- Embedded script
32. What are the major components of a Pig execution environment?
Answer:
The major components of a Pig execution environment are:
Pig Scripts: They are written in Pig Latin using built-in operators and UDFs, and submitted to the execution environment.
Parser: Completes type checking and checks the syntax of the script. The output of the parser is a Directed Acyclic Graph (DAG).
Optimizer: Performs optimization using merge, transform, split, etc. Optimizer aims to reduce the amount of data in the pipeline.
Compiler: Converts the optimized code into MapReduce jobs automatically.
Execution Engine: MapReduce jobs are submitted to execution engines to generate the desired results.
33. State the usage of the group, order by, and distinct keywords in Pig scripts.
Answer: The group statement collects various records with the same key and groups the data in one or more relations.
Example: Group_data = GROUP Relation_name BY AGE
The order statement is used to display the contents of relation in sorted order based on one or more fields.
Example: Relation_2 = ORDER Relation_name1 BY (ASC|DSC)
Distinct statement removes duplicate records and is implemented only on entire records, and not on individual records.
Example: Relation_2 = DISTINCT Relation_name1
34. Write the code needed to open a connection in HBase.
Answer: The following code is used to open a connection in HBase:
<strong>Configuration myConf = HBaseConfiguration.create();</strong>Code language: HTML, XML (xml)<strong>HTableInterface usersTable = new HTable(myConf, “users”);</strong>Code language: HTML, XML (xml)35. What does replication mean in terms of HBase?
Answer:
The replication feature in HBase provides a mechanism to copy data between clusters. This feature can be used as a disaster recovery solution that provides high availability for HBase.
The following commands alter the hbase1 table and set the replication_scope to 1. A replication_scope of 0 indicates that the table is not replicated.
disable ‘hbase1’
alter ‘hbase1’, {NAME => ‘family_name’, REPLICATION_SCOPE => ‘1’}
enable ‘hbase1’Code language: PHP (php)36. What is compaction in HBase?
Answer:
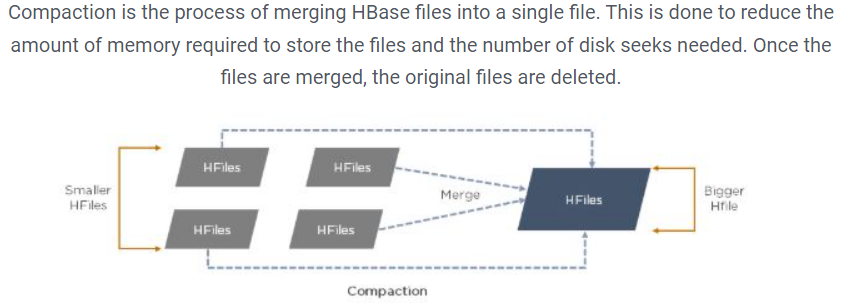
37. How does Bloom filter work?
Answer: The HBase Bloom filter is a mechanism to test whether an HFile contains a specific row or row-col cell. The Bloom filter is named after its creator, Burton Howard Bloom. It is a data structure that predicts whether a given element is a member of a set of data. These filters provide an in-memory index structure that reduces disk reads and determines the probability of finding a row in a particular file.
38. How does the Write Ahead Log (WAL) help when a RegionServer crashes?
Answer: If a RegionServer hosting a MemStore crash, the data that existed in memory, but not yet persisted, is lost. HBase recovers against that by writing to the WAL before the write completes. The HBase cluster keeps a WAL to record changes as they happen. If HBase goes down, replaying the WAL will recover data that was not yet flushed from the MemStore to the HFile.
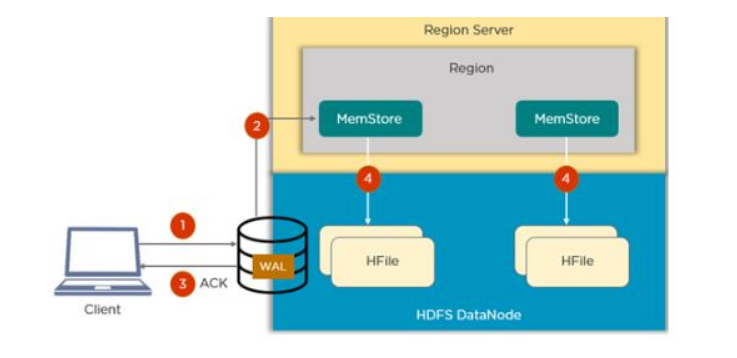
39. What are catalog tables in HBase?
Answer:
The catalog has two tables: hbasemeta and -ROOT-
The catalog table hbase:meta exists as an HBase table and is filtered out of the HBase shell’s list command. It keeps a list of all the regions in the system and the location of hbase:meta is
stored in ZooKeeper. The -ROOT- table keeps track of the location of the .META table.
40. How is Sqoop different from Flume?
Answer:
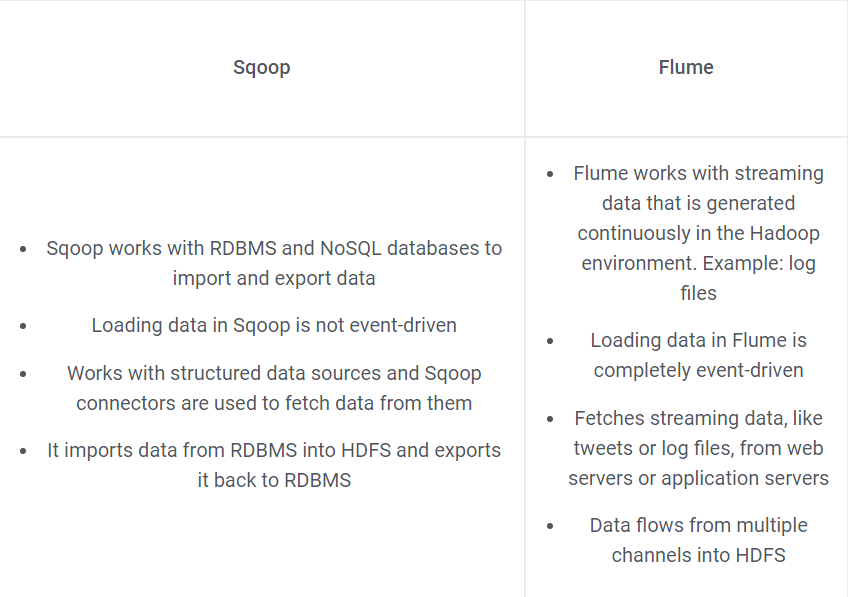
41. What is the importance of the eval tool in Sqoop?
Answer: The Sqoop eval tool allows users to execute user-defined queries against respective database servers and preview the result in the console.
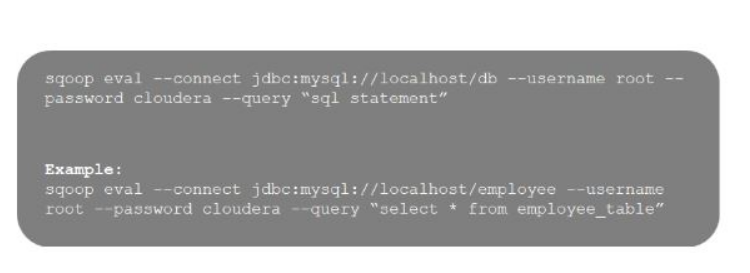
42. What is a checkpoint?
Answer: In brief, “Checkpointing” is a process that takes an FsImage, edit log and compacts them into a new FsImage. Thus, instead of replaying an edit log, the NameNode can load the final in-memory state directly from the FsImage. This is a far more efficient operation and reduces NameNode startup time. Checkpointing is performed by Secondary NameNode.
43. How is HDFS fault-tolerant?
Answer: When data is stored over HDFS, NameNode replicates the data to several DataNode. The default replication factor is 3. You can change the configuration factor as per your need. If a DataNode goes down, the NameNode will automatically copy the data to another node from the replicas and make the data available. This provides fault tolerance in HDFS.
44. Why do we use HDFS for applications having large data sets and not when there are a lot of small files?
Answer: HDFS is more suitable for large amounts of data sets in a single file as compared to a small amount of data spread across multiple files. As you know, NameNode stores the metadata information regarding the file system in the RAM. Therefore, the amount of memory produces a limit to the number of files in my HDFS file system. In other words, too many files will lead to the generation of too much metadata. And, storing this metadata in the RAM will become a challenge. As a thumb rule, metadata for a file, block, or directory takes 150 bytes.
45. What does ‘jps’ command do?
Answer: The ‘jps’ command helps us to check if the Hadoop daemons are running or not. It shows all the Hadoop daemons i.e namenode, datanode, resourcemanager, nodemanager etc. that are running on the machine.
46. What is “speculative execution” in Hadoop?
Answer: If a node appears to be executing a task slower, the master node can redundantly execute another instance of the same task on another node. Then, the task which finishes first will be accepted and the other one is killed. This process is called “speculative execution”.
47. What is the difference between an “HDFS Block” and an “Input Split”?
Answer: The “HDFS Block” is the physical division of the data while “Input Split” is the logical division of the data. HDFS divides data into blocks for storing the blocks together, whereas, for processing, MapReduce divides the data into the input split and assigns it to the mapper function.
48. How do “reducers” communicate with each other?
Answer: This is a tricky question. The “MapReduce” programming model does not allow “reducers” to communicate with each other. “Reducers” run in isolation.
49. How will you write a custom partitioner?
Answer: Custom partitioner for a Hadoop job can be written easily by following the below steps:
- Create a new class that extends Partitioner Class
- Override method – get a partition, in the wrapper that runs in MapReduce.
- Add the custom partitioner to the job by using the method set Partitioner or add the custom partitioner to the job as a config file.
50. What do you know about “SequenceFileInputFormat”?
Answer:
“SequenceFileInputFormat” is an input format for reading within sequence files. It is a specific compressed binary file format which is optimized for passing the data between the outputs of one “MapReduce” job to the input of some other “MapReduce” job.
Sequence files can be generated as the output of other MapReduce tasks and are an efficient intermediate representation for data that is passing from one MapReduce job to another.
I’m Rajesh Kumar, a DevOps, SRE, DevSecOps, Cloud, and Platform Engineering expert passionate about sharing practical knowledge, real-world experiences, and industry best practices. I have worked at Cotocus and regularly write about technology, travel, investing, health, product reviews, and digital marketing through my various platforms.
I publish technical articles at DevOps School, travel stories at Holiday Landmark, stock market insights at Stocks Mantra, health and fitness guidance at My Medic Plus, product reviews at TrueReviewNow, and SEO and digital marketing strategies at Wizbrand.
Find Trusted Cardiac Hospitals
Compare heart hospitals by city and services — all in one place.
Explore Hospitals