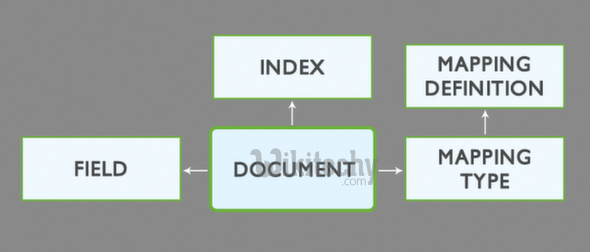
A schema is a description of one or more fields that describes the document type and how to handle the different fields of a document.
The schema in Elasticsearch is a mapping that describes the the fields in the JSON documents along with their data type, as well as how they should be indexed in the Lucene indexes that lie under the hood. Because of this, in Elasticsearch terms, we usually call this schema a “mapping”.
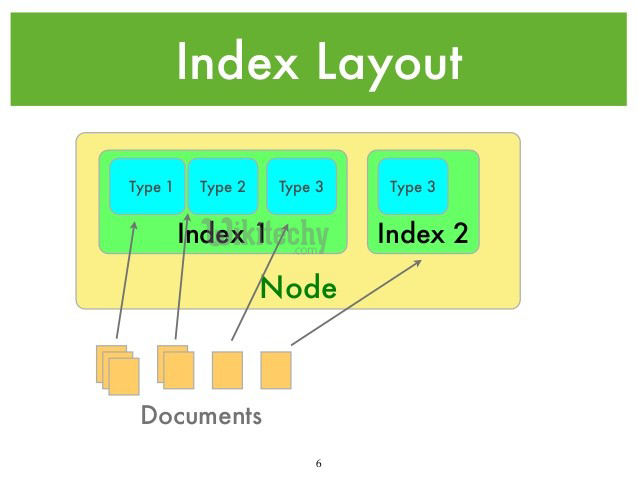
- Conceptually, an Elasticsearch server contains zero or more indexes.
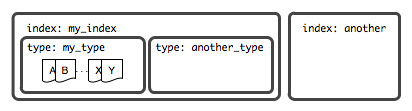
- An index is a container for zero or more types, which in turn has zero or more documents. To put it another way: a document has an identifier, belongs to a type, which belongs to an index.
- Elasticsearch is multi-tenant, by which we mean that a single server can store multiple indexes and multiple types.
- Elasticsearch has the ability to be schema-less, which means that documents can be indexed without explicitly providing a schema.
- If you do not specify a mapping, Elasticsearch will by default generate one dynamically when detecting new fields in documents during indexing.
- However, this dynamic mapping generation comes with a few caveats:Detected types might not be correct, May lead to unnecessary duplication
Mapping Type
Each index has one mapping type which determines how the document will be indexed. A mapping type has:
- Meta-fields – Meta-fields are used to customize how a document’s metadata associated is treated. Examples of meta-fields include the document’s _index, _type, _id, and _source fields.
- Fields or properties – A mapping type contains a list of fields or properties pertinent to the document.
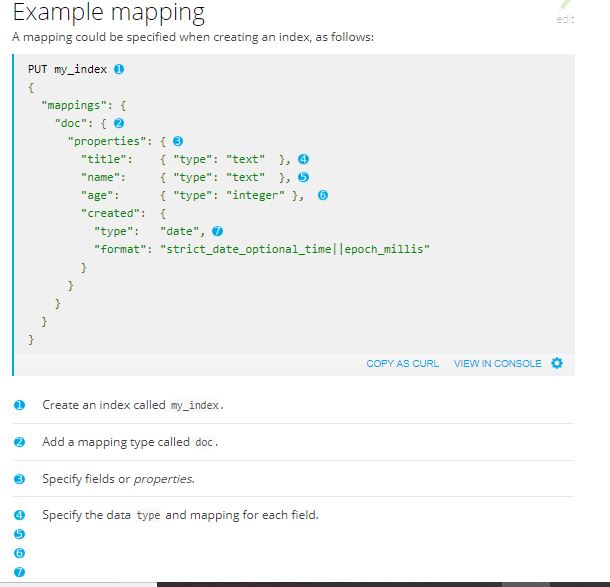
Fields datatypes
Each field has a data type which can be:
- a simple type like text, keyword, date, long, double, boolean or ip.
- a type which supports the hierarchical nature of JSON such as object or nested.
- or a specialised type like geo_point, geo_shape, or completion.
Reference
- https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping.html#_field_datatypes
- https://www.wikitechy.com/tutorials/elasticsearch/elasticsearch-mapping
I’m Rajesh Kumar, a DevOps, SRE, DevSecOps, Cloud, and Platform Engineering expert passionate about sharing practical knowledge, real-world experiences, and industry best practices. I have worked at Cotocus and regularly write about technology, travel, investing, health, product reviews, and digital marketing through my various platforms.
I publish technical articles at DevOps School, travel stories at Holiday Landmark, stock market insights at Stocks Mantra, health and fitness guidance at My Medic Plus, product reviews at TrueReviewNow, and SEO and digital marketing strategies at Wizbrand.
Find Trusted Cardiac Hospitals
Compare heart hospitals by city and services — all in one place.
Explore Hospitals