What are Recommendation Engines?

Recommendation Engines, also known as Recommender Systems, are algorithms and tools designed to recommend relevant items or content to users. These systems analyze user behavior, preferences, and item attributes to provide personalized recommendations for products, movies, music, articles, and more. Recommendation engines are widely used in various industries to improve user experience and increase engagement.
Top 10 use cases of Recommendation Engines:
- E-commerce: Recommending products to customers based on their browsing history, purchase behavior, and preferences.
- Streaming Services: Recommending movies, TV shows, or music to users based on their viewing or listening history.
- Social Media: Recommending friends or connections to users based on their existing network and interests.
- News Aggregators: Recommending articles or news content to users based on their reading history and interests.
- Online Advertising: Recommending ads to users based on their browsing behavior and interests.
- Travel and Hospitality: Recommending hotels, restaurants, or travel packages based on user preferences and past bookings.
- Job Portals: Recommending job postings to candidates based on their skills and past applications.
- Real Estate: Recommending properties to potential buyers or renters based on their preferences and search history.
- Music Streaming: Creating personalized playlists or radio stations based on users’ music preferences.
- Food Delivery: Recommending restaurants and dishes to users based on their past orders and ratings.
What are the feature of Recommendation Engines?
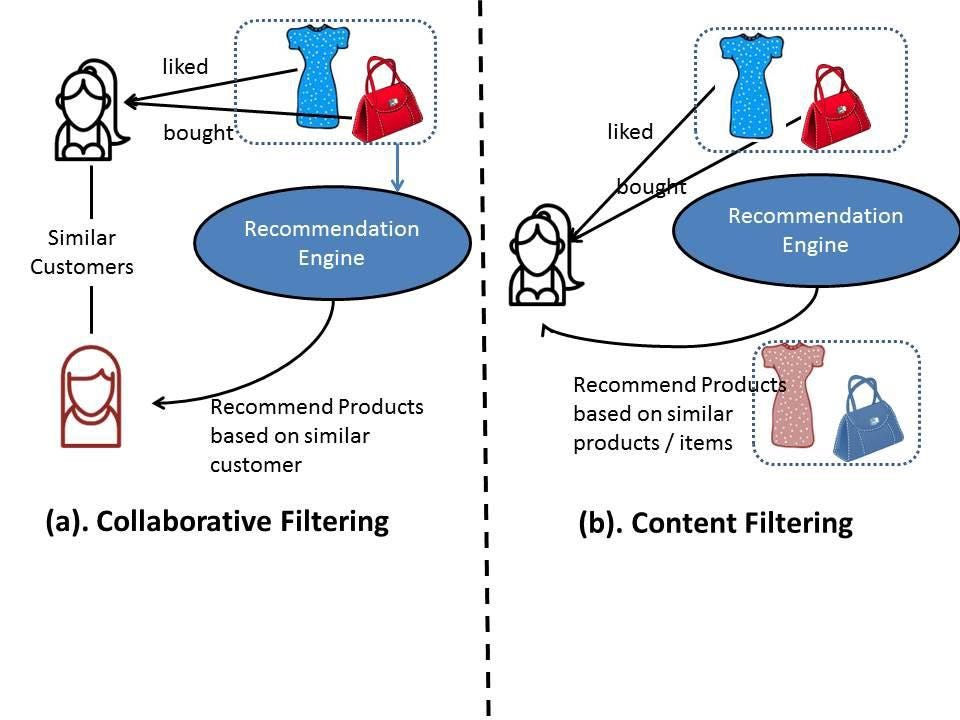
- Collaborative Filtering: Analyzing user behavior and preferences to find similarities and make recommendations based on similar users’ choices.
- Content-Based Filtering: Analyzing item attributes and user preferences to recommend items with similar features.
- Hybrid Approaches: Combining collaborative filtering and content-based filtering for more accurate recommendations.
- Personalization: Providing personalized recommendations based on individual user profiles.
- Scalability: Efficiently handling large datasets and user bases to deliver real-time recommendations.
How Recommendation Engines Work and Architecture?
The architecture and working of recommendation engines can vary based on the specific approach used. However, here’s a general outline of how they work:
- Data Collection: User behavior data (e.g., user-item interactions, ratings, clicks) and item attributes are collected.
- Data Preprocessing: Data is preprocessed to handle missing values, normalize ratings, and create user-item matrices.
- Similarity Calculation: Similarity metrics are used to find similarities between users or items. For collaborative filtering, it may involve calculating user-user or item-item similarity. For content-based filtering, it may involve calculating similarity based on item attributes.
- Recommendation Generation: Based on similarity scores and user preferences, the recommendation engine generates a list of top N recommended items for each user.
- Feedback Collection: User feedback on the recommended items is collected to further improve the recommendations.
How to Install Recommendation Engines?
The installation process for recommendation engines depends on the specific library or tool used. Some popular recommendation engine libraries and platforms include:
- Surprise: A Python library for building recommendation systems.
pip install scikit-surprise- LightFM: A Python library for hybrid recommendation systems.
pip install lightfm- Apache Mahout: A scalable machine learning library that includes recommendation algorithms.
- Download and install Apache Mahout from the official website (https://mahout.apache.org/).
- TensorFlow Recommenders: A TensorFlow extension for building recommendation models.
pip install tensorflow-recommendersPlease note that recommendation engines can be complex and may require a good understanding of the underlying algorithms and techniques. It’s recommended to refer to the official documentation and tutorials provided by the specific library or platform for detailed installation instructions and best practices.
Basic Tutorials of Recommendation Engines: Getting Started
Sure! Let’s see the step-by-step basic tutorials for building recommendation engines using two popular Python libraries: Surprise (collaborative filtering) and LightFM (hybrid recommendation).

Step-by-Step Basic Tutorial for Building Recommendation Engines using Surprise:
- Install Surprise:
- Install the Surprise library using pip:
pip install scikit-surprise
- Import Libraries:
- Create a Python script (e.g.,
recommendation_surprise.py) and import the necessary libraries:
from surprise import Dataset, Reader, SVD
from surprise.model_selection import train_test_split
from surprise.accuracy import rmse
Code language: JavaScript (javascript)- Load and Prepare Data:
- Load your user-item interaction data into a Surprise
Datasetand define the data format with aReader:
# Assuming your data is in a CSV file with columns: 'user_id', 'item_id', 'rating'
reader = Reader(line_format='user item rating', sep=',')
data = Dataset.load_from_file('data.csv', reader=reader)
Code language: PHP (php)- Split Data into Train and Test Sets:
- Divide the data into testing and training sets for evaluation:
trainset, testset = train_test_split(data, test_size=0.2)
- Build and Train the Model:
- Choose a collaborative filtering algorithm, such as Singular Value Decomposition (SVD), and train it on the training data:
model = SVD() # For example, using SVD for collaborative filtering
model.fit(trainset)
Code language: PHP (php)- Evaluate the Model:
- Evaluate the model’s performance on the test data using Root Mean Squared Error (RMSE):
predictions = model.test(testset)
rmse_score = rmse(predictions)
print("RMSE:", rmse_score)
Code language: PHP (php)Step-by-Step Basic Tutorial for Building Recommendation Engines using LightFM:
- Install LightFM:
- Install the LightFM library using pip:
pip install lightfm
- Import Libraries:
- Create a Python script (e.g.,
recommendation_lightfm.py) and import the necessary libraries:
from lightfm import LightFM
from lightfm.datasets import fetch_movielens
from lightfm.evaluation import precision_at_k
Code language: JavaScript (javascript)- Load and Prepare Data:
- Load a sample dataset like MovieLens for movie recommendation:
data = fetch_movielens()
- Split Data into Train and Test Sets:
- LightFM provides a split function to create train and test sets for evaluation:
train_data, test_data = data['train'], data['test']
Code language: JavaScript (javascript)- Build and Train the Model:
- Create a LightFM model and train it on the training data:
model = LightFM(loss='warp') # For example, using Weighted Approximate-Rank Pairwise (WARP) loss
model.fit(train_data, epochs=30, num_threads=2)
Code language: PHP (php)- Evaluate the Model:
- Evaluate the model’s performance on the test data using precision at k metric:
k = 5
precision = precision_at_k(model, test_data, k=k)
print(f"Precision at {k}: {precision.mean()}")
Code language: PHP (php)These tutorials provide basic steps to build recommendation engines using Surprise (collaborative filtering) and LightFM (hybrid recommendation). For real-world applications, you will need to customize the data loading process, handle user-item interactions, and explore different recommendation algorithms and hyperparameter tuning to achieve more accurate and personalized recommendations.

👤 About the Author
Ashwani is passionate about DevOps, DevSecOps, SRE, MLOps, and AiOps, with a strong drive to simplify and scale modern IT operations. Through continuous learning and sharing, Ashwani helps organizations and engineers adopt best practices for automation, security, reliability, and AI-driven operations.
🌐 Connect & Follow:
- Website: WizBrand.com
- Facebook: facebook.com/DevOpsSchool
- X (Twitter): x.com/DevOpsSchools
- LinkedIn: linkedin.com/company/devopsschool
- YouTube: youtube.com/@TheDevOpsSchool
- Instagram: instagram.com/devopsschool
- Quora: devopsschool.quora.com
- Email– contact@devopsschool.com
Find Trusted Cardiac Hospitals
Compare heart hospitals by city and services — all in one place.
Explore Hospitals