
What is Apache Spark?
Apache Spark is an open-source distributed computing system that can process large amounts of data quickly. It was developed in 2009 at the University of California, Berkeley, and is now maintained by the Apache Software Foundation. Spark is designed to be fast and easy to use, with a simple API that allows developers to write complex data processing jobs in a few lines of code.
Top 10 use cases of Apache Spark
Spark is widely used for data analytics, machine learning, and big data processing. Some of the top use cases of Apache Spark are:
- ETL (Extract, Transform, Load) processing
- Real-time stream processing
- Machine learning and predictive analytics
- Fraud detection and security analytics
- Recommendation engines
- Natural language processing (NLP)
- Social media analysis
- Image and video processing
- Financial analysis and risk management
- Healthcare analytics
What is the feature of Apache Spark?
Apache Spark has several features that make it a powerful tool for big data processing. Some of the key features of Apache Spark are:
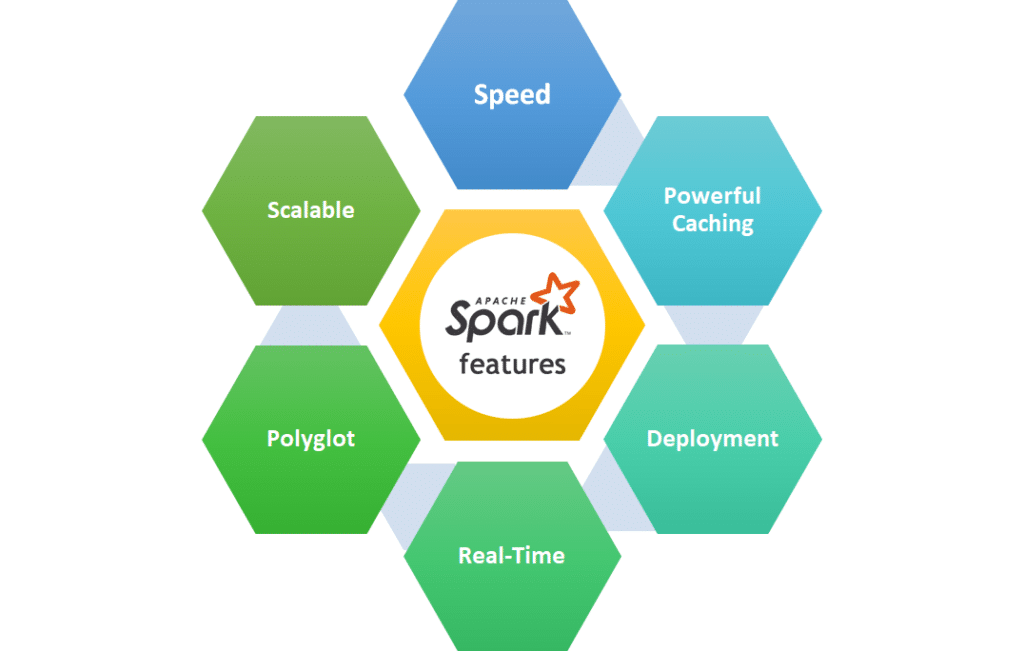
- In-memory processing: Spark stores data in memory, which makes it much faster than traditional disk-based systems.
- Fault tolerance: Spark is designed to handle node failures and recover from them automatically.
- Ease of use: Spark has a simple API that allows developers to write complex data processing jobs in a few lines of code.
- Scalability: Spark can scale to handle large amounts of data across multiple nodes.
- Compatibility: Spark can be used with a variety of programming languages, including Java, Scala, Python, and R.
How Apache Spark works and Architecture?
At a high level, Apache Spark works by breaking up large datasets into smaller chunks and processing them in parallel across multiple nodes. Spark’s architecture consists of several key components, including:
- Driver program: The driver program is responsible for coordinating tasks across the cluster and managing the overall execution of the Spark application.
- Cluster manager: The cluster manager is responsible for managing the resources of the cluster and allocating tasks to individual nodes.
- Executors: Executors are responsible for executing tasks on individual nodes, and can be scaled up or down depending on the size of the dataset being processed.
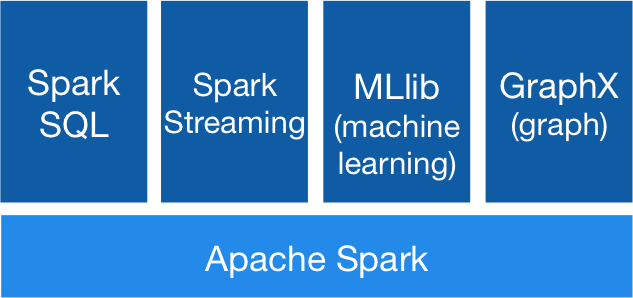
- Spark Core: The Spark Core is the heart of the Spark engine, providing the basic functionality for distributed computing, including task scheduling, memory management, and more.
- Spark SQL: Spark SQL provides a high-level interface for working with structured data, including support for SQL queries and dataframes.
- Spark Streaming: Spark Streaming provides support for real-time streaming data, allowing you to process and analyze data as it’s generated.
How to Install Apache Spark?
Installing Apache Spark is a fairly straightforward process. Here are the basic steps to install Apache Spark:
- Download the Apache Spark binary from the official website.
- Extract the downloaded file to a directory of your choice.
- Set the SPARK_HOME environment variable to the directory where you extracted Spark.
- Add the Spark bin directory to your PATH environment variable.
- Test the installation by running a sample Spark application.
Basic Tutorials of Apache Spark: Getting Started
To get started with Apache Spark, you’ll need to have some basic knowledge of programming and data processing. Here are some basic tutorials to help you get started:

Installing Apache Spark
Before you start working with Apache Spark, you need to install it on your system. Follow these steps to install Spark on your machine:
- Download Apache Spark: Visit the official Apache Spark website and download the latest version of Spark.
- Extract the archive: Unzip the downloaded file to a directory of your choice.
- Set environment variables: Set the required environment variables (e.g., JAVA_HOME) as per your system.
- Verify the installation: Run a simple Spark shell command to ensure Spark is installed correctly.
Spark Architecture
Understanding Spark’s architecture is crucial to leverage its capabilities fully. Spark follows a distributed computing model based on the Resilient Distributed Dataset (RDD). Learn about the following key components:
- Driver Program: The entry point of your Spark application, responsible for creating SparkContext.
- SparkContext: The connection to the Spark cluster, coordinating the distributed execution of tasks.
- Cluster Manager: Manages resources across the Spark cluster (e.g., Apache Mesos, Hadoop YARN).
- Executors: Worker nodes that execute tasks and store data in memory or disk.
- RDD (Resilient Distributed Dataset): Immutable distributed collections of data partitioned across nodes.
Spark Data Abstractions
Spark provides two fundamental data abstractions: RDD (Resilient Distributed Dataset) and DataFrame. Learn about these abstractions and their differences:
- RDD: RDD stands for Resilient Distributed Datasets. It’s a distributed memory abstraction that allows you to perform parallel processing on large datasets. RDDs provide transformations and actions for data processing.
- DataFrame: DataFrame is an abstraction built on top of RDD, representing a distributed collection of data organized into named columns. It offers a more user-friendly API and enables optimized execution using Catalyst Query Optimizer.
Spark Data Loading
In Spark, you can load data from various sources such as CSV, JSON, Parquet, Hive, etc. Learn how to load data into Spark using the following methods:
- Loading from Local File System: Load data from your local file system into Spark.
- Reading from HDFS: Read data from Hadoop Distributed File System (HDFS).
- Using Spark SQL: Utilize Spark SQL to directly query structured data sources like Hive.
Spark Transformations and Actions
Spark provides a rich set of transformations and actions to process data efficiently. Understand the difference between transformations and actions and how to apply them:
- Transformations: Transformations are operations applied to RDDs or DataFrames to create new RDDs or DataFrames without modifying the original data.
- Actions: Actions are operations that trigger the execution of transformations and return results or write data to an external storage system.
Spark Performance Tuning
Optimizing Spark jobs is essential for efficient data processing. Learn some performance tuning techniques to enhance the speed and efficiency of your Spark applications:
- Data Partitioning: Properly partitioning data can significantly improve performance in Spark.
- Caching and Persistence: Caching intermediate results in memory can avoid recomputation and improve overall performance.
- Broadcasting: Use broadcasting to efficiently share small data across nodes instead of sending it with tasks.
Overall, Apache Spark is a powerful tool for big data processing and analytics. With its fast performance, ease of use, and scalability, it is widely used in a variety of industries and use cases. By following the basic tutorials and getting started guides, you can quickly learn how to use Apache Spark for your own data processing and analytics needs.

👤 About the Author
Ashwani is passionate about DevOps, DevSecOps, SRE, MLOps, and AiOps, with a strong drive to simplify and scale modern IT operations. Through continuous learning and sharing, Ashwani helps organizations and engineers adopt best practices for automation, security, reliability, and AI-driven operations.
🌐 Connect & Follow:
- Website: WizBrand.com
- Facebook: facebook.com/DevOpsSchool
- X (Twitter): x.com/DevOpsSchools
- LinkedIn: linkedin.com/company/devopsschool
- YouTube: youtube.com/@TheDevOpsSchool
- Instagram: instagram.com/devopsschool
- Quora: devopsschool.quora.com
- Email– contact@devopsschool.com
Find Trusted Cardiac Hospitals
Compare heart hospitals by city and services — all in one place.
Explore Hospitals