What is AWS Glue Data Catalog?

AWS Glue Data Catalog is a fully managed metadata repository provided by Amazon Web Services (AWS). It serves as a central catalog to store metadata about data sources, tables, and partitions in your data lake or data warehouse. AWS Glue Data Catalog simplifies and automates the process of discovering, cataloging, and managing data assets in AWS-based data lake architectures. It is a serverless service that allows you to keep track of the schema and structure of your data, making it easier to perform data analysis and data processing tasks.
Top 10 use cases of AWS Glue Data Catalog:
- Metadata Management: Centralize and manage metadata about data assets, tables, and partitions in a data lake or data warehouse.
- Data Discovery: Discover and explore data assets across various data sources in the AWS environment.
- Data Cataloging: Catalog data assets and define their schema and structure for efficient data processing and analysis.
- Data Lineage: Track the lineage of data to understand its origins, transformations, and usage.
- Data Governance: Enforce data governance policies and control access to data assets.
- Data Lake Management: Manage and organize data stored in data lakes effectively.
- Data Processing: Integrate AWS Glue Data Catalog with AWS Glue ETL service to perform data processing and transformation tasks.
- Data Querying: Leverage AWS Glue Data Catalog to query and analyze data using AWS data analytics services like Amazon Athena or Amazon Redshift Spectrum.
- Data Integration: Integrate data from various sources to create a unified and consistent view of data assets.
- Data Collaboration: Facilitate collaboration among data professionals by providing a centralized metadata repository.
What are the feature of AWS Glue Data Catalog?
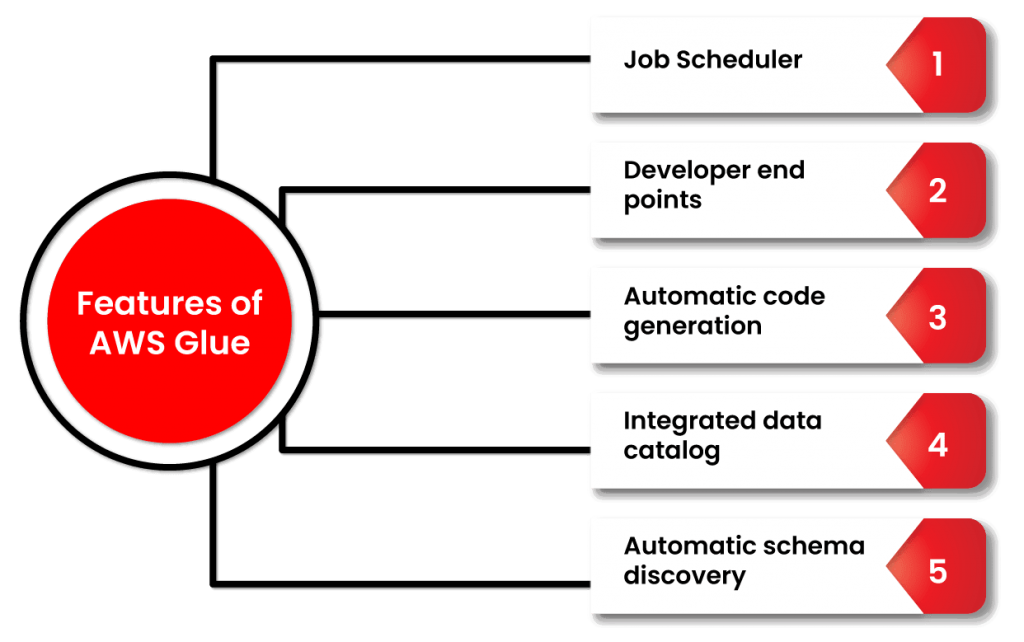
- Metadata Repository: Store metadata about data assets, tables, and partitions in a centralized repository.
- Data Discovery: Discover and explore data assets across various data sources.
- Data Cataloging: Catalog data assets and define their schema, structure, and format.
- Data Lineage: Track data lineage to understand the flow of data from source to destination.
- Data Governance: Enforce data governance policies and control access to data.
- Integration with AWS Services: Integrate with AWS data analytics services like Amazon Athena and Amazon Redshift Spectrum.
- Data Lake Management: Organize and manage data stored in data lakes.
- Data Processing Integration: Integrate with AWS Glue ETL service for data processing and transformation.
- Versioning and Change Management: Manage versions and changes to data assets and schemas.
- Data Collaboration: Facilitate collaboration among data professionals by providing a unified view of data assets.
How AWS Glue Data Catalog works and Architecture?
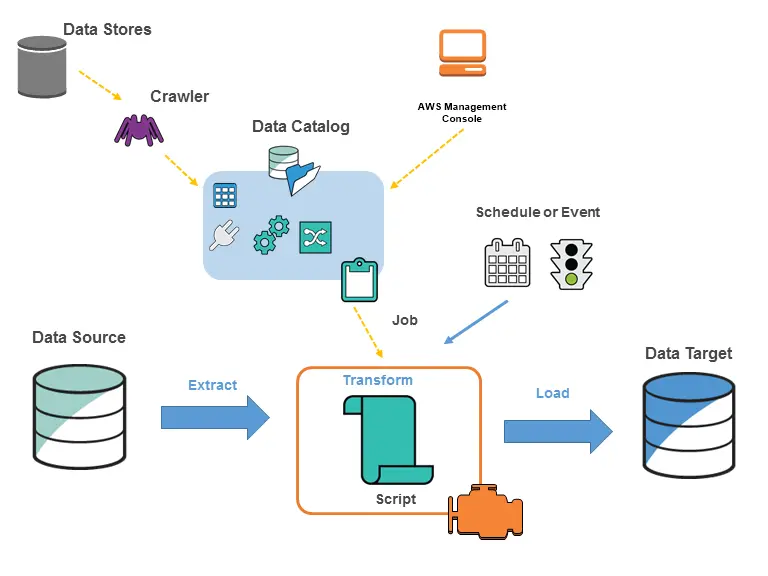
AWS Glue Data Catalog is a serverless metadata repository that automatically discovers, catalogs, and manages metadata about data assets in an AWS data lake or data warehouse environment. The service works in conjunction with other AWS data services, such as AWS Glue ETL, Amazon Athena, and Amazon Redshift Spectrum, to provide a seamless data management experience.
The architecture of AWS Glue Data Catalog involves the following components:
- Metadata Store: The metadata store is the core component of AWS Glue Data Catalog, where metadata about data assets, tables, and partitions is stored.
- Data Crawling: AWS Glue Data Catalog can automatically crawl and discover data assets in data sources like Amazon S3, Amazon RDS, Amazon Redshift, etc., to populate the metadata store.
- Data Cataloging: Once the data is crawled, AWS Glue Data Catalog catalogs the data assets and stores their metadata, including schema and structure.
- Integration with Other AWS Services: AWS Glue Data Catalog integrates with other AWS data services like AWS Glue ETL, Amazon Athena, and Amazon Redshift Spectrum to enable seamless data processing and analysis.
- Security and Access Control: AWS Glue Data Catalog provides security features to control access to metadata and data assets.
How to Install AWS Glue Data Catalog?
AWS Glue Data Catalog is a managed service provided by AWS, and there is no need for traditional installation. To use AWS Glue Data Catalog, follow these steps:
- Create an AWS Account: Sign up for an AWS account if you don’t have one already.
- Access AWS Glue Console: Log in to the AWS Management Console, navigate to the AWS Glue service, and access the AWS Glue Data Catalog.
- Set Up AWS Glue Data Catalog: Follow the AWS Glue Data Catalog setup wizard to create and configure your data catalog.
- Data Crawling and Cataloging: Set up data crawlers to automatically discover and catalog data assets from your data sources.
- Integrate with Other AWS Services: Integrate AWS Glue Data Catalog with other AWS data services as needed to perform data processing and analysis tasks.
Since AWS Glue Data Catalog is a managed service, AWS handles the infrastructure and maintenance, and there is no need for traditional installation. Simply set up and configure the service through the AWS Management Console, and you can start using the catalog to manage
Basic Tutorials of AWS Glue Data Catalog: Getting Started
Here, Let’s have a look at a basic tutorial on how to use AWS Glue Data Catalog to discover, catalog, and manage metadata about data assets in a data lake or data warehouse environment.

Step-by-Step Basic Tutorial of AWS Glue Data Catalog:
Step 1: Create an AWS Account
- If you don’t have an AWS account, sign up for one at https://aws.amazon.com/ and log in to the AWS Management Console.
Step 2: Access AWS Glue Data Catalog
- In the AWS Management Console, search for “AWS Glue” in the services search bar.
- Click on “AWS Glue” to access the AWS Glue service.
Step 3: Set Up AWS Glue Data Catalog
- In the AWS Glue console, click on “Data Catalogs” in the left-hand navigation pane.
- Click on “Create database” to create a new database within the AWS Glue Data Catalog. Give the database a name and optional description.
- Optionally, you can also set up a data lake or data warehouse using other AWS services like Amazon S3, Amazon RDS, or Amazon Redshift.
Step 4: Crawl and Catalog Data
- Click on “Crawlers” in the left-hand navigation pane.
- Click on “Add crawler” to create a new crawler.
- Configure the crawler to discover and catalog data assets from your data sources, such as Amazon S3 buckets or Amazon RDS databases.
- Schedule the crawler to run periodically for incremental data discovery and cataloging.
Step 5: Review and Validate Data
- Once the crawler runs, review the crawled data in the AWS Glue Data Catalog.
- Validate that the data assets and tables are correctly cataloged with the appropriate schema and metadata.
Step 6: Query Data Using AWS Analytics Services
- Use AWS data analytics services like Amazon Athena or Amazon Redshift Spectrum to query and analyze the data cataloged in AWS Glue Data Catalog.
- Leverage the metadata in the data catalog to perform data analysis efficiently.
Step 7: Manage Data and Metadata
- As your data assets evolve, use AWS Glue Data Catalog to manage changes to metadata, table definitions, and partitions.
- Update the data catalog as new data sources are added or data is transformed.
Step 8: Data Governance (Optional)
- If needed, implement data governance policies using AWS Glue Data Catalog to control access to data assets and manage data quality.
For more in-depth tutorials and advanced use cases, I recommend referring to AWS documentation, tutorials, and user guides available on the AWS website and the AWS Management Console.

👤 About the Author
Ashwani is passionate about DevOps, DevSecOps, SRE, MLOps, and AiOps, with a strong drive to simplify and scale modern IT operations. Through continuous learning and sharing, Ashwani helps organizations and engineers adopt best practices for automation, security, reliability, and AI-driven operations.
🌐 Connect & Follow:
- Website: WizBrand.com
- Facebook: facebook.com/DevOpsSchool
- X (Twitter): x.com/DevOpsSchools
- LinkedIn: linkedin.com/company/devopsschool
- YouTube: youtube.com/@TheDevOpsSchool
- Instagram: instagram.com/devopsschool
- Quora: devopsschool.quora.com
- Email– contact@devopsschool.com
Find Trusted Cardiac Hospitals
Compare heart hospitals by city and services — all in one place.
Explore Hospitals
