History & Origin of Caffe
Deep learning is the new big trend in machine learning. It had many recent successes in computer vision, automatic speech recognition and natural language processing.
The goal of this blog post is to give you a hands-on introduction to deep learning. To do this, we will build a Cat/Dog image classifier using a deep learning algorithm called convolutional neural network (CNN) and a Kaggle dataset.
This post is divided into 2 main parts. The first part covers some core concepts behind deep learning, while the second part is structured in a hands-on tutorial format.
In the first part of the hands-on tutorial (section 4), we will build a Cat/Dog image classifier using a convolutional neural network from scratch. In the second part of the tutorial (section 5), we will cover an advanced technique for training convolutional neural networks called transfer learning. We will use some Python code and a popular open source deep learning framework called Caffe to build the classifier. Our classifier will be able to achieve a classification accuracy of 97%.
By the end of this post, you will understand how convolutional neural networks work, and you will get familiar with the steps and the code for building these networks.
What is Caffe
Caffe is a deep learning framework made with expression, speed, and modularity in mind. It is developed by Berkeley AI Research (BAIR) and by community contributors. Yangqing Jia created the project during his PhD at UC Berkeley. Caffe is released under the BSD 2-Clause license.
Expressive architecture encourages application and innovation. Models and optimization are defined by configuration without hard-coding. Switch between CPU and GPU by setting a single flag to train on a GPU machine then deploy to commodity clusters or mobile devices.
Extensible code fosters active development. In Caffe’s first year, it has been forked by over 1,000 developers and had many significant changes contributed back. Thanks to these contributors the framework tracks the state-of-the-art in both code and models.
Speed makes Caffe perfect for research experiments and industry deployment. Caffe can process over 60M images per day with a single NVIDIA K40 GPU*. That’s 1 ms/image for inference and 4 ms/image for learning and more recent library versions and hardware are faster still. We believe that Caffe is among the fastest convnet implementations available.
How Caffe works aka Caffe architecture?
Classification using a machine learning algorithm has 2 phases:
- Training phase: In this phase, we train a machine learning algorithm using a dataset comprised of the images and their corresponding labels.
- Prediction phase: In this phase, we utilize the trained model to predict labels of unseen images.
The training phase for an image classification problem has 2 main steps:
- Feature Extraction: In this phase, we utilize domain knowledge to extract new features that will be used by the machine learning algorithm. HoG and SIFT are examples of features used in image classification.
- Model Training: In this phase, we utilize a clean dataset composed of the images’ features and the corresponding labels to train the machine learning model.
In the predicition phase, we apply the same feature extraction process to the new images and we pass the features to the trained machine learning algorithm to predict the label.

The main difference between traditional machine learning and deep learning algorithms is in the feature engineering. In traditional machine learning algorithms, we need to hand-craft the features. By contrast, in deep learning algorithms feature engineering is done automatically by the algorithm. Feature engineering is difficult, time-consuming and requires domain expertise. The promise of deep learning is more accurate machine learning algorithms compared to traditional machine learning with less or no feature engineering.

Use case of Caffe
Caffe is being used in academic research projects, startup prototypes, and even large-scale industrial applications in vision, speech, and multimedia. Yahoo! has also integrated Caffe with Apache Spark to create CaffeOnSpark, a distributed deep learning framework.
Feature and Advantage of using Caffe
- Once you venture outside of Caffe’s comfort zone, i.e. convnets, its usability drops significantly. For example, try doing RNN for language modeling in Caffe.
- All the machinery e.g. protobuf, layers etc. comes in the way once you try to define your own layer types.
- Only a few input formats and only one output format, HDF5 (although you can always run it using its Python/C++/Matlab interface and getting output data from there).
- Multi-GPU training is partially supported but not all the different ways of doing that such as model/data parallelism etc.
- Many interesting modifications are only available in patches submitted by different people.
Best Alternative of Caffe
- Keras.
- DeepPy.
- NVIDIA Deep Learning GPU Training System (DIGITS)
- TFLearn.
- Torch.
- Clarifai.
- Microsoft Cognitive Toolkit (Formerly CNTK)
- AWS Deep Learning AMIs.
Best Resources, Tutorials and Guide for Caffe
- DevOpsSchool
- ScmGalaxy
- Edureka
- Simplilearn
Free Video Tutorials of Caffe
Interview Questions and Answer for Caffe
Answer
- Machine Learning depends on humans to learn. Humans determine the hierarchy of features to determine the difference between the data input. It usually requires more structured data to learn.
- Deep Learning automates much of the feature extraction piece of the process. It eliminates the manual human intervention required.
- Machine Learning is less dependent on the amount of data as compared to deep learning.
- Deep Learning requires a lot of data to give high accuracy. It would take thousands or millions of data points which are trained for days or weeks to give an acceptable accurate model.
- Ensemble methods are used to increase the generalization power of a model. These methods are applicable to both deep learning as well as machine learning algorithms.
- Some ensemble methods introduced in neural networks are Dropout and Dropconnect. The improvement in the model depends on the type of data and the nature of neural architecture.
- Deep Learning gives a better performance compared to machine learning if the dataset is large enough.
- Deep Learning does not need the person designing the model to have a lot of domain understanding for feature introspection. Deep learning outshines other methods if there is no feature engineering done.
- Deep Learning really shines when it comes to complex problems such as image classification, natural language processing, and speech recognition.
Answer
- One of the best benefits of Deep Learning is its ability to perform automatic feature extraction from raw data.
- When the number of data fed into the learning algorithm increases, there will be more edge cases taken into consideration and hence the algorithm will learn to make the right decisions in those edge cases.
- When researchers started to create large artificial neural networks, they started to use the word deep to refer to them.
- As the term deep learning started to be used, it is generally understood that it stands for artificial neural networks which are deep as opposed to shallow artificial neural networks.
- Deep Artificial Neural Networks and Deep Learning are generally the same thing and mostly used interchangeably.
- When researchers started to create large artificial neural networks, they started to use the word deep to refer to them.
- As the term deep learning started to be used, it is generally understood that it stands for artificial neural networks which are deep as opposed to shallow artificial neural networks.
- Deep Artificial Neural Networks and Deep Learning are generally the same thing and mostly used interchangeably.
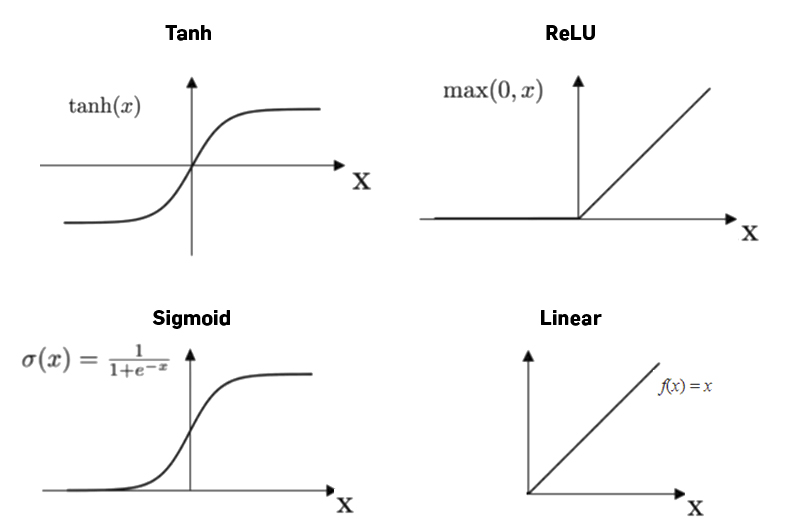
- If the output to be predicted is real, then it makes sense to use a Linear Activation function.
- If the output to be predicted is a probability of a binary class, then a Sigmoid function should be used.
- If the output to be predicted has two classes, then a Tanh function can be used.
- ReLU function can be used in many different cases due to its computational simplicity.
- Incremental learning refers to the ability of an algorithm to learn from new data that may become available after a classifier has already been generated from a previously available dataset.
- An algorithm is said to be an incremental learning algorithm if, for a sequence of training datasets, it produces a sequence of hypotheses where the current hypothesis describes all data that have been seen thus far but depends only on previous hypotheses and the current training data.
- Ensemble-based systems can be used for such problems by training an additional classifier (or an additional ensemble of classifiers) on each dataset that becomes available.
- The model will improve very slowly during the training phase and it is also possible that training stops very early, meaning that any further training does not improve the model.
- The weights closer to the output layer of the model would witness more of a change whereas the layers that occur closer to the input layer would not change much (if at all).
- Model weights shrink exponentially and become very small when training the model.
- The model weights become
0in the training phase.
There are some subtle signs that you may be suffering from exploding gradients during the training of your network, such as:
- The model is unable to get traction on your training data (e g. poor loss).
- The model is unstable, resulting in large changes in loss from update to update.
- The model loss goes to
NaNduring training.
If you have these types of problems, you can dig deeper to see if you have a problem with exploding gradients. There are some less subtle signs that you can use to confirm that you have exploding gradients:
- The model weights quickly become very large during training.
- The model weights go to
NaNvalues during training. - The error gradient values are consistently above
1.0for each node and layer during training.
I’m Rajesh Kumar, a DevOps, SRE, DevSecOps, Cloud, and Platform Engineering expert passionate about sharing practical knowledge, real-world experiences, and industry best practices. I have worked at Cotocus and regularly write about technology, travel, investing, health, product reviews, and digital marketing through my various platforms.
I publish technical articles at DevOps School, travel stories at Holiday Landmark, stock market insights at Stocks Mantra, health and fitness guidance at My Medic Plus, product reviews at TrueReviewNow, and SEO and digital marketing strategies at Wizbrand.
Find Trusted Cardiac Hospitals
Compare heart hospitals by city and services — all in one place.
Explore Hospitals