What is DVC?

DVC (Data Version Control) is an open-source version control system designed specifically for managing machine learning projects and data science workflows. It focuses on the versioning and management of data files, machine learning models, and the associated code, allowing data scientists and machine learning engineers to collaborate, track changes, and reproduce experiments more effectively.
Top 10 use cases of DVC:
Here are the top 10 use cases of DVC:
- Versioning Data: DVC allows you to version control large datasets and data files, ensuring that changes to data are tracked and reproducible.
- Reproducibility: DVC helps maintain reproducibility by capturing all the necessary dependencies, data versions, and code used in a specific experiment or project.
- Experiment Tracking: DVC enables you to track and manage experiments, including hyperparameters, metrics, and the exact data and code used for each run.
- Collaboration: DVC facilitates collaboration among team members by providing a clear way to share and reproduce experiments across different environments.
- Data Sharing: With DVC, you can easily share data files and datasets with collaborators without duplicating the data itself.
- Model Management: DVC allows versioning of machine learning models, making it easier to track changes and collaborate on model development.
- Data Lineage: DVC provides a clear lineage of how data is transformed and used throughout the machine learning pipeline, aiding in debugging and troubleshooting.
- Pipeline Management: DVC integrates with popular pipeline orchestration tools, helping you manage complex machine learning workflows and dependencies.
- Data Preprocessing: DVC can version control data preprocessing code, ensuring that data transformations are consistent across experiments.
- Experiment Comparison: DVC makes it easy to compare different experiments, allowing you to analyze the impact of different approaches and changes.
- Model Deployment: DVC can help manage the deployment process by keeping track of the model version, associated code, and data used for deployment.
- Continuous Integration and Continuous Deployment (CI/CD): DVC integrates with CI/CD pipelines, enabling automated testing and deployment of machine learning projects.
These use cases demonstrate how DVC simplifies the management, versioning, and collaboration aspects of machine learning projects, improving reproducibility, collaboration, and efficiency in data science workflows.
What are the feature of DVC?
DVC is designed to address the specific versioning and management needs of machine learning projects and data science workflows. Its features include:
- Data Versioning: DVC allows you to version control data files, datasets, and models, ensuring that changes are tracked over time.
- Reproducibility: DVC captures the exact versions of data, code, and dependencies used in each experiment, enabling easy reproduction of results.
- Experiment Tracking: DVC provides tools to track experiment metadata, including hyperparameters, metrics, and the associated data and code.
- Collaboration: DVC supports collaboration by allowing multiple team members to work on the same project and reproduce each other’s work.
- Data Lineage: DVC provides clear data lineage, showing how data is transformed and used in various stages of the pipeline.
- Model Management: DVC version controls machine learning models, making it easier to track changes and collaborate on model development.
- Pipeline Management: DVC integrates with pipeline orchestration tools to manage complex machine learning workflows and dependencies.
- Integration with Git: DVC seamlessly integrates with Git, enabling versioning of both code and data within the same repository.
- Data Sharing: DVC enables sharing of data files without duplicating the data itself, saving storage space and facilitating collaboration.
- Efficient Storage: DVC employs a technique called “data pointers” to store data efficiently, reducing duplication of large datasets.
- Data Preprocessing: DVC version controls data preprocessing scripts, ensuring consistency in data transformations across experiments.
- CLI and GUI: DVC provides a command-line interface (CLI) for advanced users and a graphical user interface (GUI) for simplified interaction.
How DVC works and Architecture?
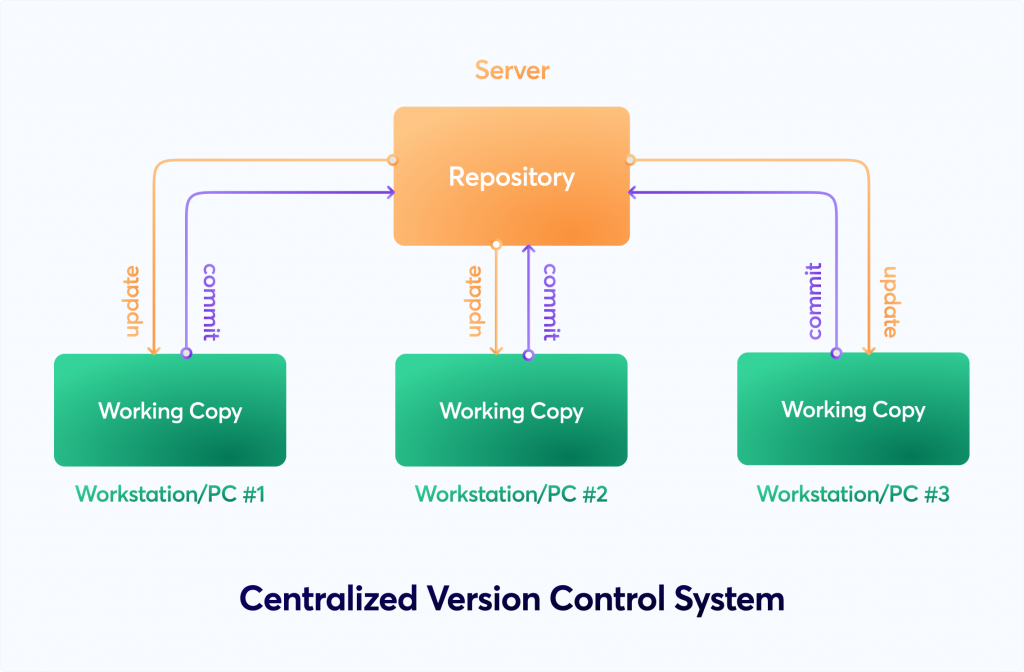
DVC Architecture:
DVC operates in conjunction with a version control system (typically Git) and a storage backend (such as local storage, Amazon S3, or Google Cloud Storage):
- Local Repository: DVC uses Git for managing code and metadata. Git tracks changes to code, while DVC handles data versioning.
- Remote Storage: Data files and large datasets are stored in a remote storage backend, which can be a cloud object storage service or a local file system.
Data Flow and Interaction:
Here’s how DVC works in terms of data flow and interaction:
- Initializing a Project: You start by initializing a DVC project within a Git repository. This sets up the necessary files and directories.
- Adding Data: You add data files to the DVC project using the
dvc addcommand. This creates a small “data pointer” file that points to the actual data file stored remotely. - Committing to Git: After adding data, you commit the changes to the Git repository. This records the addition of the data pointer in Git.
- Managing Experiments: You create and manage experiments by using DVC commands to track changes to code, hyperparameters, metrics, and data.
- Reproducing Experiments: DVC uses the data pointers to retrieve the correct versions of data from the remote storage, ensuring that each experiment is reproducible.
- Versioning Models: DVC can also version control machine learning models, allowing you to track changes to the model files.
- Sharing and Collaboration: Team members can clone the Git repository and use DVC to reproduce experiments, ensuring consistent results across different environments.
DVC’s architecture and workflow simplify the management and versioning of data and code in machine learning projects. By integrating with Git and remote storage, DVC provides a comprehensive solution for maintaining reproducibility and collaboration in data science workflows.
How to Install DVC?
To install DVC, you can follow these steps:
- Install Python 3.8 or later.
- Install the DVC Python package. You can do this using pip:
pip install dvc- Create a DVC project. You may perform this by running the below command:
dvc initThis will create a DVC directory in your current working directory.
- Add some data to your DVC project. You may perform this by running the below command:
dvc add data.csvCode language: CSS (css)This will add the data.csv file to your DVC project.
- Commit your changes. You may perform this by running the below command:
dvc commitThis will create a DVC checkpoint that records the state of your project.
- Push your changes to a remote repository. You may perform this by running the below command:
dvc pushThis will push your DVC checkpoint to a remote repository, such as GitLab or GitHub.
For more detailed instructions on how to install DVC, please refer to the DVC documentation: https://dvc.org/doc/install
Here are some of the benefits of using DVC:
- It is a version control system for data.
- It can be used to track changes to data, manage data pipelines, and collaborate on data science projects.
- It is easy to use and can be integrated with other tools, such as Git and Kubernetes.
Here are some of the drawbacks of using DVC:
- It is a relatively new tool and may not be as stable as some of the other version control systems.
- It can be complex to use for complex data pipelines.
Overall, DVC is a powerful tool that can be used to manage data science projects. It is simple to apply and can be integrated with other tools.
Basic Tutorials of DVC: Getting Started

The following are the steps of basic tutorials of DVC:
- Version control with DVC
DVC can be used to track changes to data in a similar way to how Git tracks changes to code. This can be useful for keeping track of different versions of data, as well as for collaborating on data science projects.
To use DVC for version control, you can follow these steps:
1. Create a DVC project.
2. Add data to the project.
3. Commit the changes to the project.
4. Push the changes to a remote repository.
- Managing data pipelines with DVC
DVC can also be used to manage data pipelines. This can be useful for automating the process of data processing and machine learning model training.
To use DVC for managing data pipelines, you can follow these steps:
1. Define the data pipeline in a DVC file.
2. Run the data pipeline.
3. Commit the changes to the project.
4. Push the changes to a remote repository.
- Collaborating on data science projects with DVC
DVC can also be used to collaborate on data science projects. This can be useful for sharing data, code, and results with other team members.
To collaborate on data science projects with DVC, you can follow these steps:
1. Create a DVC project.
2. Add data to the project.
3. Commit the changes to the project.
4. Push the changes to a remote repository.
5. Invite other team members to the project.
- Integrating DVC with other tools
DVC can be integrated with other tools, such as Git, Kubernetes, and Docker. This can be useful for automating the process of data science projects and for deploying machine learning models.
To integrate DVC with other tools, you can follow the instructions in the DVC documentation: https://dvc.org/doc/

👤 About the Author
Ashwani is passionate about DevOps, DevSecOps, SRE, MLOps, and AiOps, with a strong drive to simplify and scale modern IT operations. Through continuous learning and sharing, Ashwani helps organizations and engineers adopt best practices for automation, security, reliability, and AI-driven operations.
🌐 Connect & Follow:
- Website: WizBrand.com
- Facebook: facebook.com/DevOpsSchool
- X (Twitter): x.com/DevOpsSchools
- LinkedIn: linkedin.com/company/devopsschool
- YouTube: youtube.com/@TheDevOpsSchool
- Instagram: instagram.com/devopsschool
- Quora: devopsschool.quora.com
- Email– contact@devopsschool.com
Find Trusted Cardiac Hospitals
Compare heart hospitals by city and services — all in one place.
Explore Hospitals