
What is IBM InfoSphere DataStage?
IBM InfoSphere DataStage is a powerful data integration tool that helps businesses streamline their data integration process. It is designed to extract, transform, and load (ETL) large volumes of data from various sources into a target system. With its robust set of features, IBM InfoSphere DataStage can help companies improve their data quality, increase efficiency, and reduce costs.
Top 10 use cases of IBM InfoSphere DataStage
- Data Warehousing: IBM InfoSphere DataStage is widely used for building and maintaining data warehouses. It can extract data from various sources, transform it, and load it into a data warehouse for analytics and reporting.
- Data Migration: When companies need to move data from one system to another, IBM InfoSphere DataStage can help. It can extract data from the source system, transform it as needed, and load it into the target system.
- Data Integration: IBM InfoSphere DataStage can integrate data from various sources, such as databases, files, and web services, into a single system. This helps businesses get a complete view of their data.
- Master Data Management: IBM InfoSphere DataStage can help businesses manage their master data, such as customer or product information. It can extract data from various sources, cleanse and transform it, and load it into a master data repository.
- Data Quality: IBM InfoSphere DataStage can help businesses improve their data quality by performing data profiling, data cleansing, and data validation.
- Big Data Integration: IBM InfoSphere DataStage can integrate data from big data sources, such as Hadoop, into a target system. This helps businesses get insights from their big data.
- Real-time Data Integration: IBM InfoSphere DataStage can process real-time data streams from various sources, such as sensors or social media feeds.
- Cloud Integration: IBM InfoSphere DataStage can integrate data from cloud-based sources, such as Salesforce or Amazon S3, into a target system.
- E-commerce: IBM InfoSphere DataStage can help e-commerce businesses manage their product catalogs, inventory, and orders across multiple channels.
- Healthcare: IBM InfoSphere DataStage can help healthcare providers manage patient data and integrate it with electronic health records (EHRs).
What are the features of IBM InfoSphere DataStage?
IBM InfoSphere DataStage offers a wide range of features that make it a powerful data integration tool. Some of its key features include:
- Data integration from various sources: IBM InfoSphere DataStage can extract data from various sources, including databases, files, and web services.
- Data transformation: IBM InfoSphere DataStage can transform data as needed, such as cleansing, aggregating, and joining data.
- Data quality: IBM InfoSphere DataStage can help improve data quality by performing data profiling, data cleansing, and data validation.
- Parallel processing: IBM InfoSphere DataStage can process data in parallel, which helps improve performance and scalability.
- Real-time data processing: IBM InfoSphere DataStage can process real-time data streams from various sources, such as sensors or social media feeds.
- Cloud integration: IBM InfoSphere DataStage can integrate data from cloud-based sources, such as Salesforce or Amazon S3.
- Big data integration: IBM InfoSphere DataStage can integrate data from big data sources, such as Hadoop.
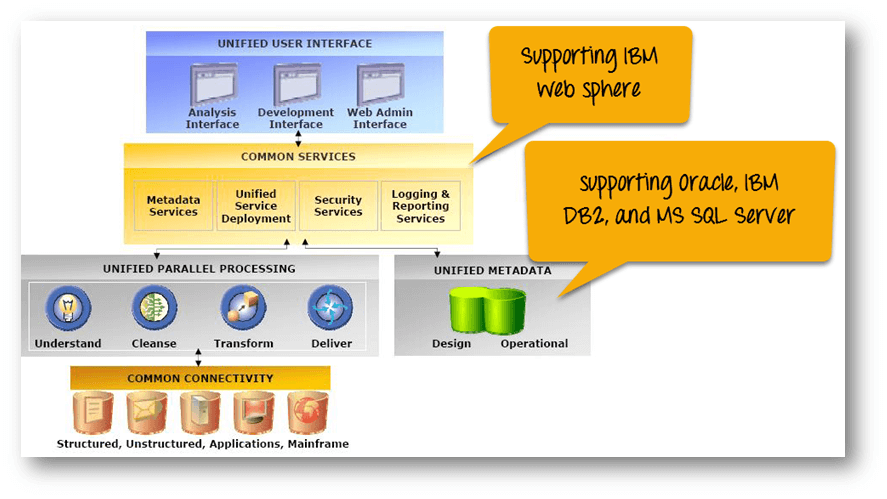
How IBM InfoSphere DataStage works and Architecture?
IBM InfoSphere DataStage works by extracting data from multiple sources, transforming it, and loading it into a target system. It uses a parallel processing architecture to optimize performance and scalability.
The architecture of IBM InfoSphere DataStage consists of four main components:
- DataStage Designer: It is used to design and develop ETL jobs.
- DataStage Director: It is used to run and monitor ETL jobs.
- DataStage Administrator: It is used to manage the DataStage environment.
- DataStage Engine: It is used to execute the ETL jobs.
How to Install IBM InfoSphere DataStage?
Installing IBM InfoSphere DataStage can be a complex process, but it can be simplified by following these steps:
- Download the installation files from the IBM website.
- Extract the installation files to a directory on your system.
- Run the installation program and follow the prompts to install IBM InfoSphere DataStage.
- Configure the installation settings, such as the installation directory and database settings.
- Test the installation by running a sample job.
Basic Tutorials of IBM InfoSphere DataStage: Getting Started
To get started with IBM InfoSphere DataStage, follow these basic tutorials:

Once you have the software installed, let’s open up IBM InfoSphere DataStage and get started!
Creating a New Project
The first step in using IBM InfoSphere DataStage is to create a new project. This will enable you to organize your work and keep everything in one place.
By implementing these steps, create a new project:
- Open up IBM InfoSphere DataStage
- Choose the “File” option in the top left corner
- Click on “New”
- Select “Project” and click “OK”
- Give your project a name and click “OK”
Congratulations! You’ve now created a new project in IBM InfoSphere DataStage.
Creating a Job
Now that we have our project set up, let’s create a job. A job in IBM InfoSphere DataStage is a set of instructions that tells the tool what to do with our data.
To create a job, follow these steps:
- Right-click on your project in the “Designer” tab
- Click on “New” and select “Job”
- Give your job a name and click “OK”
Adding a Stage
We now have a blank job that we can start working on. The first thing we need to do is add a stage. A stage is a module in IBM InfoSphere DataStage that performs a specific task.
To add a stage, follow these steps:
- Right-click on your job and select “Add Stage”
- Select the type of stage you want to add and click “OK”
Congratulations! You’ve now added a stage to your job.
Connecting Stages
Now that we have a stage in our job, we need to connect it to the other stages.
To connect stages, follow these steps:
- Click on the output port of the first stage
- Click and drag to the input port of the next stage
Congratulations! You’ve now connected your stages.
Running the Job
Now that we have our stages connected, we’re ready to run our job.
To run a job, follow these steps:
- Click on the “Run” button in the top left corner
- Select your job and click “OK”
Congratulations! You’ve now run your job in IBM InfoSphere DataStage.
Conclusion
And there you have it, folks! A basic tutorial on IBM InfoSphere DataStage. We covered the essentials of creating a project, adding a job, adding a stage, connecting stages, and running the job. With this knowledge, you’re well on your way to becoming an IBM InfoSphere DataStage pro.
Happy data integrating!

👤 About the Author
Ashwani is passionate about DevOps, DevSecOps, SRE, MLOps, and AiOps, with a strong drive to simplify and scale modern IT operations. Through continuous learning and sharing, Ashwani helps organizations and engineers adopt best practices for automation, security, reliability, and AI-driven operations.
🌐 Connect & Follow:
- Website: WizBrand.com
- Facebook: facebook.com/DevOpsSchool
- X (Twitter): x.com/DevOpsSchools
- LinkedIn: linkedin.com/company/devopsschool
- YouTube: youtube.com/@TheDevOpsSchool
- Instagram: instagram.com/devopsschool
- Quora: devopsschool.quora.com
- Email– contact@devopsschool.com
Find Trusted Cardiac Hospitals
Compare heart hospitals by city and services — all in one place.
Explore Hospitals