History & Origin of Keras
In the Keras docs, we find: The History. history attribute is a dictionary recording training loss values and metrics values at successive epochs, as well as validation loss values and validation metrics values
When running this model, Keras maintains a so-called History object in the background. This object keeps all loss values and other metric values in memory so that they can be used in e.g. TensorBoard, in Excel reports or indeed for our own custom visualizations.
The history object is the output of the fit operation. Hence, it can be accessed in your Python script by slightly adapting that row in the above code to:
history = model.fit(X, Y, epochs=250, batch_size=1, verbose=1, validation_split=0.2)
In the Keras docs, we find:
The
History.historyattribute is a dictionary recording training loss values and metrics values at successive epochs, as well as validation loss values and validation metrics values (if applicable).
Also add print(history) so that we can inspect the history before we visualize it, to get a feel for its structure.
It indeed outputs the model history (note that for simplicity we trained with only 5 epochs):
What is Keras ?
Keras is a high-level, deep learning API developed by Google for implementing neural networks. It is written in Python and is used to make the implementation of neural networks easy. It also supports multiple backend neural network computation.
Keras is relatively easy to learn and work with because it provides a python frontend with a high level of abstraction while having the option of multiple back-ends for computation purposes. This makes Keras slower than other deep learning frameworks, but extremely beginner-friendly.
Keras allows you to switch between different back ends. The frameworks supported by Keras are:
- Tensorflow
- Theano
- PlaidML
- MXNet
- CNTK (Microsoft Cognitive Toolkit )
Out of these five frameworks, TensorFlow has adopted Keras as its official high-level API. Keras is embedded in TensorFlow and can be used to perform deep learning fast as it provides inbuilt modules for all neural network computations. At the same time, computation involving tensors, computation graphs, sessions, etc can be custom made using the Tensorflow Core API, which gives you total flexibility and control over your application and lets you implement your ideas in a relatively short time.
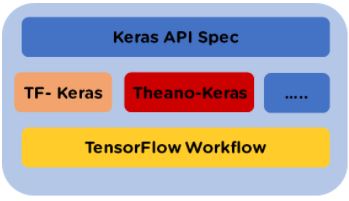
Keras is used for creating deep models which can be productized on smartphones. Keras is also used for distributed training of deep learning models. Keras is used by companies such as Netflix, Yelp, Uber, etc
Explain the Architecture of Keras Framework?
Keras is an Open Source Neural Network library written in Python that runs on top of Theano or TensorFlow. It is designed to be modular, fast and easy to use. Keras is high-level API wrapper for the low-level API, capable of running on top of TensorFlow, CNTK, or Theano.
Keras High-Level API handles the way we make models, defining layers, or set up multiple input-output models. In this level, Keras also compiles our model with loss and optimizer functions, training process with fit function. Keras doesn’t handle Low-Level API such as making the computational graph, making tensors or other variables as it has been handled by the “backend” engine.

Backend is a term in Keras that performs all low-level computation such as tensor products, convolutions and many other things with the help of other libraries such as TensorFlow or Theano. So, the “backend engine” will perform the computation and development of the models. TensorFlow is the default “backend engine” but we can change it in the configuration.
Use case of Keras
Keras is used for creating deep models which can be productized on smartphones. Keras is also used for distributed training of deep learning models. Keras is used by companies such as Netflix, Yelp, Uber, etc.
How to Build a Model in Keras?
The below diagram shows the basic steps involved in building a model in Keras:

Figure 3: Building a model
- Define a network: In this step, you define the different layers in our model and the connections between them. Keras has two main types of models: Sequential and Functional models. You choose which type of model you want and then define the dataflow between them.
- Compile a network: To compile code means to convert it in a form suitable for the machine to understand. In Keras, the model.compile() method performs this function. To compile the model, we define the loss function which calculates the losses in our model, the optimizer which reduces the loss, and the metrics which is used to find the accuracy of our model.
- Fit the network: Using this, we fit our model to our data after compiling. This is used to train the model on our data.
- Evaluate the network: After fitting our model, we need to evaluate the error in our model.
- Make Predictions: We use model.predict() to make predictions using our model on new data.
Applications of Keras
- Keras is used for creating deep models which can be productized on smartphones.
- Keras is also used for distributed training of deep learning models.
- Keras is used by companies such as Netflix, Yelp, Uber, etc.
- Keras is also extensively used in deep learning competitions to create and deploy working models, which are fast in a short amount of time.
Build deep learning models in TensorFlow and learn the TensorFlow open-source framework with the Deep Learning Course (with Keras &TensorFlow). Enroll now!
Conclusion
In this article titled ‘What is Keras? The best introductory guide to Keras’, we first answered the question, ‘What is Keras?’. We then looked at why Keras is so popular and why you should use Keras followed by the basic steps involved in making a model in Keras. We then saw a few uses of Keras.
We hope this article answered the question which was burning in the back of your mind: What is Keras? Do you have any doubts or questions for us? Mention them in this article’s comments section, and we’ll have our experts answer them for you at the earliest!
Feature and Advantage of using Keras
- User-Friendly and Fast Deployment. …
- Quality Documentation and Large Community Support. …
- Multiple Backend and Modularity. …
- Pretrained models. …
- Multiple GPU Support. …
- Problems in low-level API. …
- Need improvement in some features. …
- Slower than its backend.
Advantages and Drawbacks of Keras
Keras is a high-level neural network API. It runs on the top of TensorFlow and Theano and is very famous in the field of Deep Learning. It is one of the best libraries used for neural networks that follows a minimalist philosophy.
Keras is very powerful and useful for beginners who are starting with Deep Learning. Before starting with Keras, it is important to know the Advantages and Drawbacks of Keras.
Best Alternative of Keras
- TFLearn.
- NVIDIA Deep Learning GPU Training System (DIGITS)
- Clarifai.
- DeepPy.
- Knet.
- Microsoft Cognitive Toolkit (Formerly CNTK)
- Torch.
- RustNN.
Best Resources, Tutorials and Guide for Keras
You can use any of these courses and online training to learn deep learning, but I highly recommend you to check Deep Learning specialization on Coursera by Andrew Ng and the team. It’s by far the most comprehensive resource on deep learning.
Free Video Tutorials of Keras
Interview Questions and Answer for Keras
LSTM’s have a Nature of Remembering information for long periods of time is their Default behavior. The LSTM had a three-step Process:
1. Forget Gate This gate Decides which information is to be omitted from the cell in that particular timestamp. It is decided by the sigmoid function. However, it looks at the previous state(ht-1) and the content input(Xt) and outputs a number between 0(omit this)and 1(keep this)for each number in the cell state Ct−1.
2. Update Gate/input gate Decides how much of this unit is added to the current state. In this, the Sigmoid function decides which values to let through 0,1. and tanh function gives weightage to the values which are passed deciding their level of importance ranging from-1 to 1.
3. Output Gate Decides which part of the current cell makes it to the output. In this, the Sigmoid function decides which values to let through 0,1. and tanh function gives weightage to the values which are passed deciding their level of importance ranging from-1 to 1 and multiplied with an output of Sigmoid.
The techniques are as follows:
1. L2 and L1 Regularization
2. Dropout
3. Early Stopping
4. Data Augmentation
The process for training a CNN for classifying images consists of the following steps −
1. Data Preparation In this step, we center-crop the images and resize them so that all images for training and testing would be of the same size. This is usually done by running a small Python script on the image data.
2. Model Definition In this step, we define a CNN architecture. The configuration is stored in .pb (protobuf) file.
3. Solver Definition In this, we define the solver configuration file. The solver does the model optimization.
4. Model Training In this, we use the built-in Caffe utility to train the model. The training may take a considerable amount of time and CPU usage. After the training is completed, Caffe stores the model in a file, which can, later on, be used on test data and final deployment for predictions.
I’m Rajesh Kumar, a DevOps, SRE, DevSecOps, Cloud, and Platform Engineering expert passionate about sharing practical knowledge, real-world experiences, and industry best practices. I have worked at Cotocus and regularly write about technology, travel, investing, health, product reviews, and digital marketing through my various platforms.
I publish technical articles at DevOps School, travel stories at Holiday Landmark, stock market insights at Stocks Mantra, health and fitness guidance at My Medic Plus, product reviews at TrueReviewNow, and SEO and digital marketing strategies at Wizbrand.
Find Trusted Cardiac Hospitals
Compare heart hospitals by city and services — all in one place.
Explore Hospitals
Thank you for writing such an informative and interesting article.