What is Red Hat JBoss Data Virtualization?
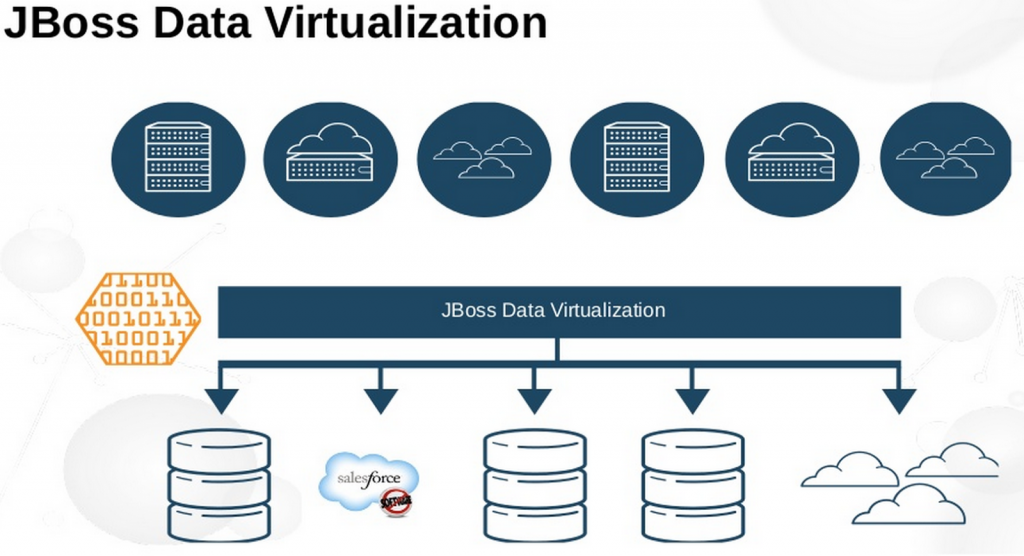
Red Hat JBoss Data Virtualization is an open-source data integration and federation platform that allows organizations to access and integrate data from multiple sources in real-time, without the need for physical data replication. It provides a unified view of data from various sources, such as databases, web services, cloud applications, and more. JBoss Data Virtualization helps organizations improve data agility, reduce data redundancy, and simplify data access for business users.
Top 10 use cases of Red Hat JBoss Data Virtualization:
- Data Integration: Integrating and combining data from heterogeneous data sources into a single, unified view.
- Data Federation: Providing a virtual, real-time view of data from multiple sources without physically moving or replicating the data.
- Data Services: Exposing data as services to facilitate application development and integration.
- Data Virtualization for BI: Creating a unified view of data for reporting and analytics purposes.
- Data Abstraction: Abstracting the complexities of underlying data sources to simplify data access for applications.
- Data Governance: Enforcing data access controls and governance policies across various data sources.
- Data Security: Implementing security controls and access restrictions for sensitive data.
- Data Caching: Caching frequently accessed data to improve performance and reduce data latency.
- Data Quality: Applying data quality rules and transformations in real-time data access.
- Data Replication and Synchronization: Replicating and synchronizing data between different systems and platforms.
What are the feature of Red Hat JBoss Data Virtualization?
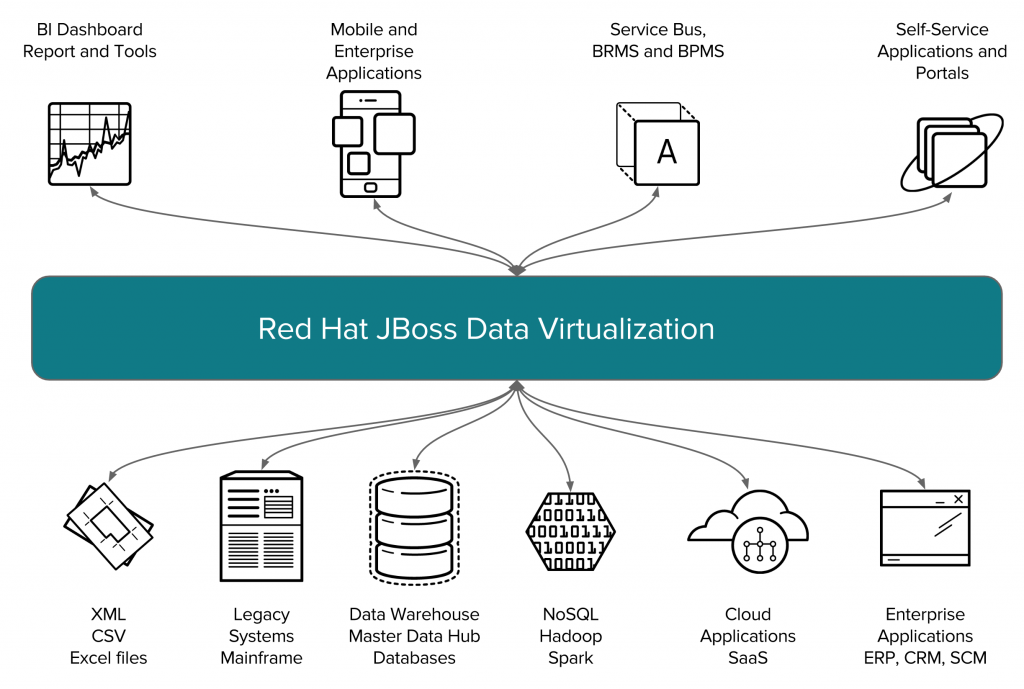
- Data Federation: Provides a unified, virtual view of data from multiple sources.
- Query Optimization: Optimizes queries to improve performance and reduce data latency.
- Real-Time Data Access: Accesses data in real-time from various sources without physical replication.
- Data Transformation: Transforms and manipulates data on-the-fly during data access.
- Data Security: Implements security features and access controls to protect data.
- Metadata Management: Manages metadata to track data sources and relationships.
- Data Governance: Enforces data governance policies and compliance rules.
- RESTful API: Exposes data as RESTful services for easy integration with applications.
- Data Caching: Caches frequently accessed data to improve performance.
- Management Console: Provides a web-based console for managing data virtualization operations.
How Red Hat JBoss Data Virtualization works and Architecture?
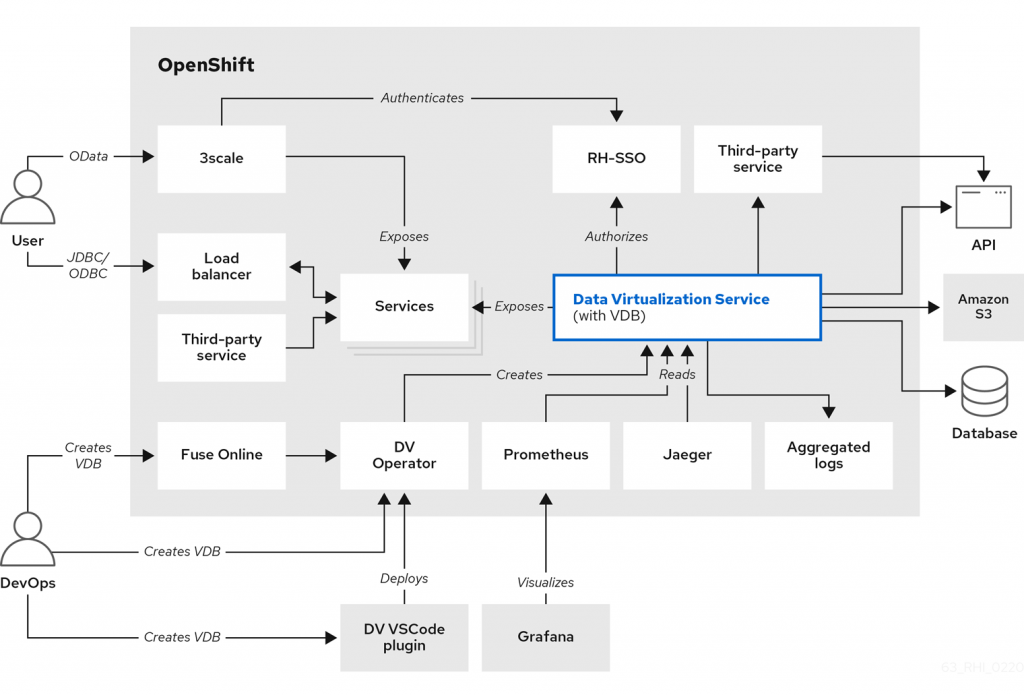
JBoss Data Virtualization works as a middleware layer between data consumers (applications, users) and various data sources. Its architecture typically involves the following components:
- Teiid Server: The core component responsible for data virtualization and query optimization.
- Data Sources: Connects to various data sources, including databases, web services, and cloud applications.
- Data Models: Defines virtual data models that represent the structure of the data to be exposed.
- Metadata Repository: Stores metadata and configuration information about data sources and virtual data models.
- Teiid Admin Console: A web-based console for managing and monitoring JBoss Data Virtualization.
- Data Services: Virtual data services that expose data as services to applications.
How to Install Red Hat JBoss Data Virtualization?
Installing Red Hat JBoss Data Virtualization involves the following steps:
- Download the Software: Obtain the JBoss Data Virtualization installation files from the Red Hat website.
- System Requirements: Review the system requirements to ensure your environment meets the necessary prerequisites.
- Install the Software: Run the installer and follow the on-screen instructions to install JBoss Data Virtualization.
- Configure Data Sources: Set up connections to your data sources (databases, web services, etc.) in the configuration files.
- Configure Virtual Data Models: Define virtual data models that represent the structure of the data to be exposed.
- Start JBoss Data Virtualization: Start the Teiid Server and other components of JBoss Data Virtualization.
For detailed installation instructions and best practices, refer to the official Red Hat JBoss Data Virtualization documentation and support resources provided by Red Hat.
Basic Tutorials of Red Hat JBoss Data Virtualization: Getting Started
Here, Let’s have a look at a step-by-step guide to get started with Red Hat JBoss Data Virtualization. For detailed instructions and best practices, refer to the official Red Hat JBoss Data Virtualization documentation and support resources.

Step-by-Step Basic Tutorials of Red Hat JBoss Data Virtualization:
- Download and Install JBoss Data Virtualization:
- Obtain the JBoss Data Virtualization installation files from the Red Hat website.
- Review the system requirements to ensure your environment meets the necessary prerequisites.
- Run the installer and follow the on-screen instructions to install JBoss Data Virtualization.
2. Configure Data Sources:
- Set up connections to your data sources such as databases, web services, cloud applications, etc.
- Configure the connection parameters and authentication details for each data source.
3. Define Virtual Data Models:
- Use the Teiid Designer tool to define virtual data models that represent the structure of the data to be exposed.
- Create views, procedures, and functions to transform and manipulate data during data access.
4. Create Data Services:
- Define data services that expose virtual data models as RESTful or SOAP services.
- Specify the data access protocols and endpoints for the data services.
5. Deploy Data Services:
- Deploy the data services to the JBoss Data Virtualization server.
- Ensure that the data services are running and accessible.
6. Query Data Services:
- Use tools like REST clients or SOAP clients to query the data services.
- Retrieve data from various data sources in real-time.
7. Optimize Queries:
- Monitor the performance of data services and optimize queries for better response times.
- Utilize query optimization techniques to improve query execution.
8. Data Caching (Optional):
- Explore data caching options to cache frequently accessed data for improved performance.
9. Data Security (Optional):
- Implement security features and access controls to protect sensitive data.
10. Data Governance (Optional):
- Enforce data governance policies and compliance rules as per organizational requirements.
To gain a deeper understanding and expertise, it is recommended to explore the official Red Hat JBoss Data Virtualization documentation, attend training sessions, and leverage Red Hat support resources for comprehensive tutorials and best practices.

👤 About the Author
Ashwani is passionate about DevOps, DevSecOps, SRE, MLOps, and AiOps, with a strong drive to simplify and scale modern IT operations. Through continuous learning and sharing, Ashwani helps organizations and engineers adopt best practices for automation, security, reliability, and AI-driven operations.
🌐 Connect & Follow:
- Website: WizBrand.com
- Facebook: facebook.com/DevOpsSchool
- X (Twitter): x.com/DevOpsSchools
- LinkedIn: linkedin.com/company/devopsschool
- YouTube: youtube.com/@TheDevOpsSchool
- Instagram: instagram.com/devopsschool
- Quora: devopsschool.quora.com
- Email– contact@devopsschool.com
Find Trusted Cardiac Hospitals
Compare heart hospitals by city and services — all in one place.
Explore Hospitals