What is StreamSets Data Collector?
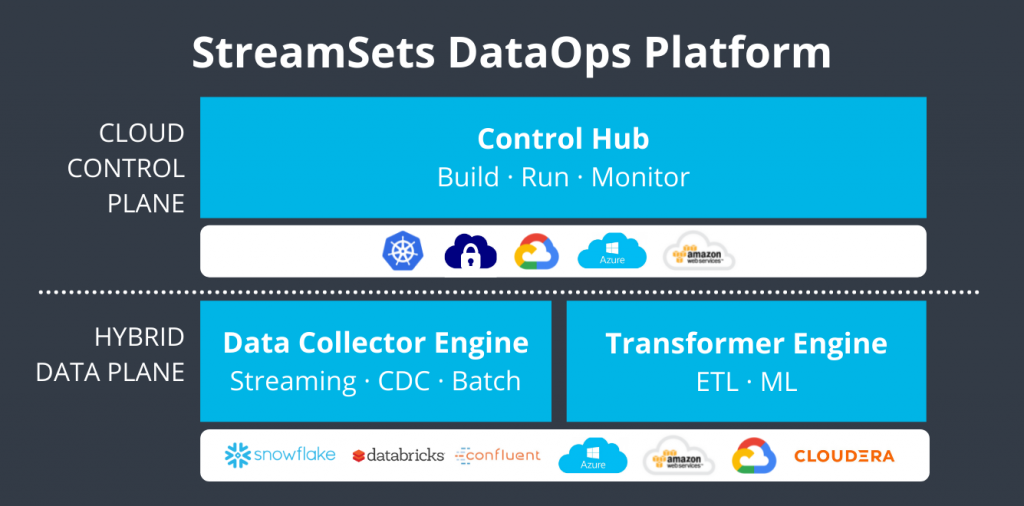
StreamSets Data Collector is an open-source data ingestion and integration tool that simplifies the process of collecting, processing, and delivering data from various sources to multiple destinations. It provides a user-friendly graphical interface to design and execute data pipelines, making it easy for data engineers and data integration teams to build scalable and resilient data integration workflows. StreamSets Data Collector is part of the StreamSets DataOps Platform, which offers a comprehensive set of tools for data engineering and data operations.
Top 10 use cases of StreamSets Data Collector:
- Real-time Data Ingestion: Collect data in real-time from streaming sources, such as Kafka, Kinesis, or RabbitMQ.
- Batch Data Ingestion: Ingest data from batch sources like files, databases, or cloud storage systems.
- Data Transformation: Perform data transformations and enrichment to prepare data for analysis and storage.
- Data Quality Assurance: Validate and clean data to ensure data quality and consistency.
- Data Replication: Replicate data from one database or data store to another for data synchronization.
- Cloud Data Integration: Integrate data between on-premises systems and cloud services.
- IoT Data Collection: Collect and process data from Internet of Things (IoT) devices and sensors.
- Log Aggregation: Centralize and process log data from various applications and systems.
- Change Data Capture (CDC): Capture and propagate data changes from databases to downstream systems.
- Data Archiving: Archive historical data to long-term storage solutions.
What are the feature of StreamSets Data Collector?
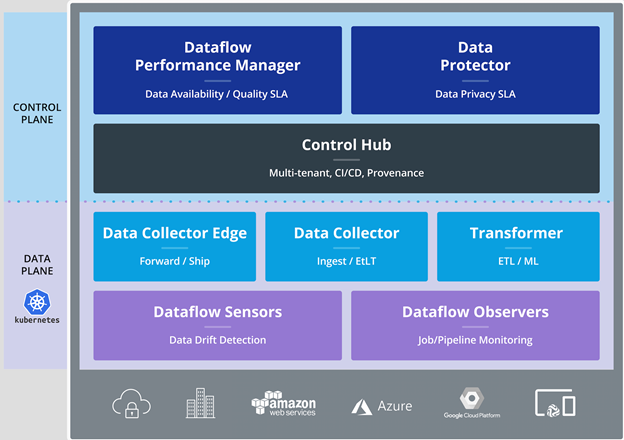
- Drag-and-Drop Interface: Design data pipelines using an intuitive visual interface with drag-and-drop components.
- Pre-built Connectors: Access a library of pre-built connectors for various data sources and destinations.
- Data Transformation: Perform data transformations and enrichment using built-in processors and expressions.
- Data Validation: Validate data against defined rules to ensure data quality and integrity.
- Change Data Capture (CDC): Capture data changes from databases using CDC mechanisms.
- Data Encryption and Security: Securely transfer and handle sensitive data using encryption and security features.
- Monitoring and Alerting: Monitor data pipeline execution in real-time and receive alerts for any issues.
- Fault Tolerance and Resilience: Handle failures and ensure data integrity with built-in fault tolerance.
- Data Lineage and Metadata Management: Track data lineage and manage metadata for data governance.
- Cluster Management: Scale and manage multiple StreamSets Data Collector instances in a cluster.
How StreamSets Data Collector works and Architecture?
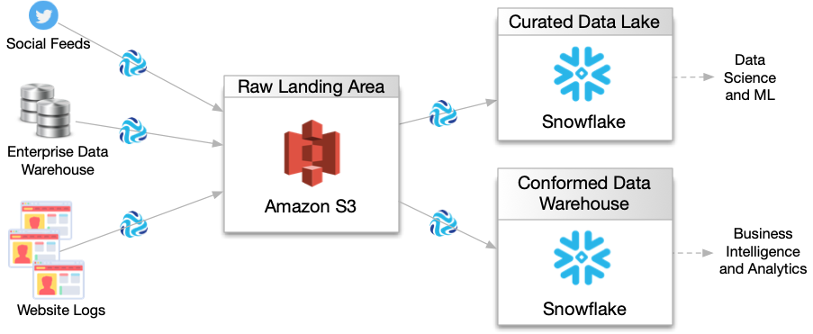
StreamSets Data Collector works by allowing users to visually design data pipelines using a graphical user interface. Users drag and drop connectors and processors onto the canvas, configure them to define data flow, and create data pipelines. StreamSets Data Collector supports both batch and streaming data processing.
The key components of StreamSets Data Collector are:
- Connectors: These components facilitate data extraction and ingestion from various sources.
- Processors: These components perform data transformations, enrichment, and filtering.
- Destinations: These components facilitate data loading into target data stores.
- Pipeline Execution: StreamSets Data Collector executes the data pipelines to collect, process, and deliver data.
How to Install StreamSets Data Collector?
To install StreamSets Data Collector, follow these general steps:
- Prerequisites: Ensure you have Java (JRE 1.8 or later) installed on your system.
- Download StreamSets Data Collector: Go to the StreamSets website (https://streamsets.com/) and download the StreamSets Data Collector package that matches your operating system.
- Extract the Package: Extract the downloaded package to a directory of your choice.
- Start StreamSets Data Collector: Navigate to the extracted directory and run the following command to start StreamSets Data Collector:
./bin/streamsets dc- Access the User Interface: Once StreamSets Data Collector is running, you can access the user interface via your web browser at
http://localhost:18630/.
Please note that this is a basic outline of the installation process. Be sure to refer to the official StreamSets documentation for more detailed installation and configuration instructions: https://streamsets.com/documentation/
Basic Tutorials of StreamSets Data Collector: Getting Started
Here, Let’s have a look at a general outline for getting started with StreamSets Data Collector:
Step-by-Step Basic Tutorial of StreamSets Data Collector:
Step 1: Download and Install StreamSets Data Collector
- Go to the StreamSets website (https://streamsets.com/).
- Download the StreamSets Data Collector package that matches your operating system.
- Install StreamSets Data Collector by following the installation instructions provided in the documentation.
Step 2: Access the StreamSets Data Collector Web Interface
- Once installed, start StreamSets Data Collector by running the appropriate command for your OS.
- Open your web browser and navigate to the StreamSets Data Collector web interface at
http://localhost:18630.
Step 3: Create a New Data Pipeline
- In the StreamSets Data Collector web interface, click on the “Create New Pipeline” button.
- Give your pipeline a name and description.
Step 4: Add a Data Source
- Drag and drop a suitable data source (connector) from the left panel onto the canvas.
- Configure the data source properties, such as the connection details and data format.
Step 5: Add Data Processing Steps (Processors)
- Drag and drop processors from the left panel onto the canvas to perform data transformations and enrichment.
- Connect the data source to the processors to define the data flow.
Step 6: Add a Data Destination
- Drag and drop a data destination (connector) onto the canvas.
- Connect the processors to the data destination to define the output flow.
Step 7: Configure Data Destination
- Configure the properties of the data destination, such as the connection details and data format.
Step 8: Validate and Test the Data Pipeline
- Click on the “Validate” button to check for any configuration errors or issues.
- Click on the “Preview” button to see sample data as it flows through the pipeline.
Step 9: Save and Execute the Data Pipeline
- Save the data pipeline by clicking on the “Save” button.
- Click on the “Start” button to execute the data pipeline and start data ingestion and processing.
Step 10: Monitor and Troubleshoot
- Monitor the data pipeline execution in the “Monitor” tab of the StreamSets Data Collector web interface.
- Use the “Data Collector Logs” tab to troubleshoot any issues or errors that may occur during pipeline execution.
Please note that this is a basic outline to get started with StreamSets Data Collector. For a more detailed and up-to-date tutorial, I recommend checking the official StreamSets documentation and tutorials provided by StreamSets on their website or in their official support channels.

👤 About the Author
Ashwani is passionate about DevOps, DevSecOps, SRE, MLOps, and AiOps, with a strong drive to simplify and scale modern IT operations. Through continuous learning and sharing, Ashwani helps organizations and engineers adopt best practices for automation, security, reliability, and AI-driven operations.
🌐 Connect & Follow:
- Website: WizBrand.com
- Facebook: facebook.com/DevOpsSchool
- X (Twitter): x.com/DevOpsSchools
- LinkedIn: linkedin.com/company/devopsschool
- YouTube: youtube.com/@TheDevOpsSchool
- Instagram: instagram.com/devopsschool
- Quora: devopsschool.quora.com
- Email– contact@devopsschool.com
Find Trusted Cardiac Hospitals
Compare heart hospitals by city and services — all in one place.
Explore Hospitals