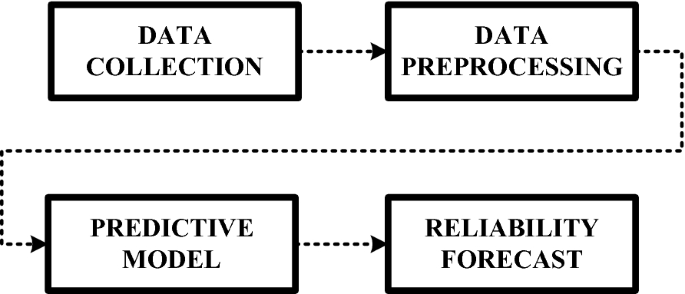
Introduction
Predictive analytics is the process of using data, statistical algorithms, and machine learning techniques to identify the likelihood of future outcomes based on historical data. However, before we can dive into predictive analytics, we need to first discuss the importance of data preprocessing.
What is Data Preprocessing?
Data preprocessing is an essential step in the data analysis process that involves transforming raw data into a more usable format. This step typically involves cleaning, transforming, and organizing data to ensure accuracy and consistency. Data preprocessing is crucial for predictive analytics because it helps improve the accuracy and reliability of the models.
Why is Data Preprocessing Important in Predictive Analytics?
Data preprocessing is important in predictive analytics for several reasons:
1. Data Quality
Inaccurate or inconsistent data can lead to incorrect predictions. By preprocessing the data, we can identify and correct any errors or inconsistencies in the data, which in turn improves the accuracy of the predictive model.
2. Feature Selection
Feature selection is the process of selecting the most relevant variables to include in the predictive model. Data preprocessing can help identify which features are most important and relevant to the prediction task.
3. Data Normalization
Data normalization is the process of scaling the data to a uniform range. This is important because some algorithms are sensitive to the scale of the input data. By normalizing the data, we can ensure that the algorithm is not biased towards certain features.
4. Data Reduction
In some cases, the amount of data we have may be too large to handle efficiently. Data preprocessing can help reduce the size of the data by removing redundant or irrelevant features.
Techniques Used in Data Preprocessing
There are several techniques used in data preprocessing, including:
1. Data Cleaning
Data cleaning involves identifying and correcting errors or inconsistencies in the data. This can include removing duplicates, correcting typos, and filling in missing values.
2. Data Transformation
Data transformation involves converting the data into a more usable format. This can include converting categorical data into numerical data, or applying mathematical functions to the data.
3. Data Integration
Data integration involves combining data from multiple sources into a single dataset. This can be a complex process, as the data may be in different formats or have different structures.
4. Data Reduction
Data reduction involves reducing the size of the data by removing redundant or irrelevant features. This can be done through techniques such as Principal Component Analysis (PCA) or Linear Discriminant Analysis (LDA).
Conclusion
In conclusion, data preprocessing is a crucial step in the predictive analytics process. It helps improve the accuracy and reliability of the predictive model by ensuring that the data is accurate, relevant, and consistent. By using techniques such as data cleaning, data transformation, data integration, and data reduction, we can prepare the data for analysis and ensure that we are making accurate predictions.

👤 About the Author
Ashwani is passionate about DevOps, DevSecOps, SRE, MLOps, and AiOps, with a strong drive to simplify and scale modern IT operations. Through continuous learning and sharing, Ashwani helps organizations and engineers adopt best practices for automation, security, reliability, and AI-driven operations.
🌐 Connect & Follow:
- Website: WizBrand.com
- Facebook: facebook.com/DevOpsSchool
- X (Twitter): x.com/DevOpsSchools
- LinkedIn: linkedin.com/company/devopsschool
- YouTube: youtube.com/@TheDevOpsSchool
- Instagram: instagram.com/devopsschool
- Quora: devopsschool.quora.com
- Email– contact@devopsschool.com
Find Trusted Cardiac Hospitals
Compare heart hospitals by city and services — all in one place.
Explore Hospitals