| # | Contents |
|---|---|
| 1. | The Hashing Formula Facts |
| 2. | Important Hashing formula Terminology |
| 3. | How Hashing Algorithm decides which AMP has the Row? |
| 4. | Hashing Theory For Non- Unique Primary Indexes have Skewed Data |
| 5. | What Uniqueness Value? |
| 6. | What is ROW ID? |
| 7. | Why each AMP Sorts their rows by the Row-ID? |
The Teradata Hashing Formula Facts
- There is one Hashing Formula in Teradata, and it is consistent.
- The concept is to take the value of a row’s Primary Index and run it through the Hash Formula.
- It will produce a Row Hash number.
- That Row Hash will stay with the row forever and reside as the first part of the row.
- The Row Hash also determines which AMP owns the row.
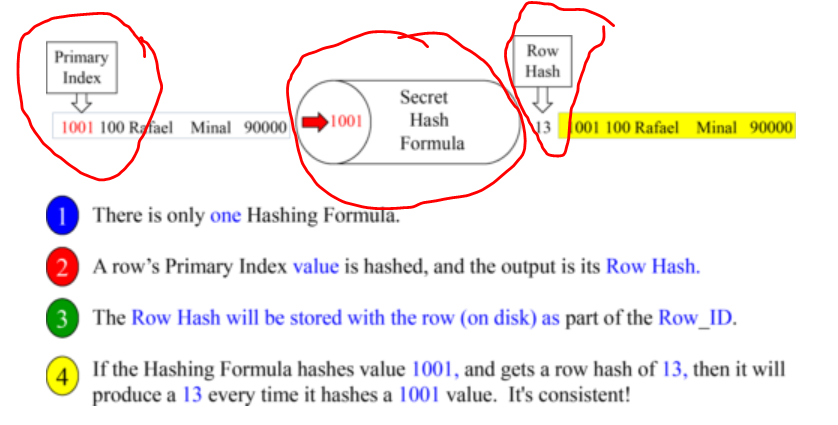
Important Hashing formula Terminology
Row Hash :- The primary Index row goes through Secret hash Formula which gives output number as Row Hash
Hash Map :-The Row hash number goes to a bucket in the Hash Map and is assigned to an AMP.
Hash Bucket:- If a Row Hash number is 5. Teradata counted over to bucket 5 in the Hash Map, and it has the number two (2) inside that bucket. This means that this row will go to AMP 2.
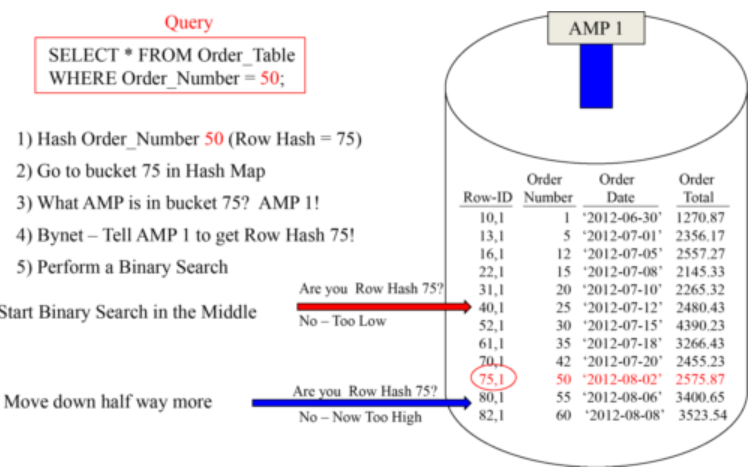
How Hashing Algorithm decides which AMP has the Row?
Hashing Algorithm Process:
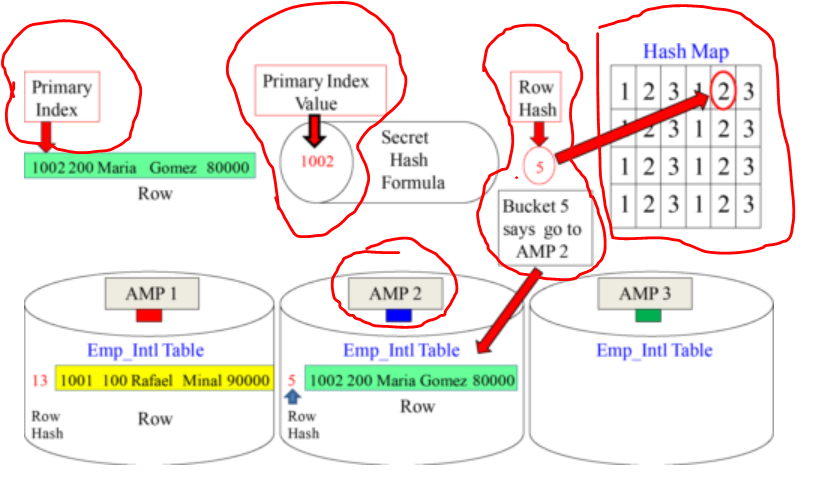
- A row will be placed on an AMP after the Parsing Engine (PE) hashes the row’s Primary Index value.
- The output of the Hashing Algorithm is a row’s Row Hash.
- The Row hash goes to a bucket in the Hash Map and is assigned to an AMP.
- The above example hashed Emp_No 1002 (Primary Index value) and the output was a Row Hash of 5. Teradata counted over to bucket 5 in the Hash Map, and it has the number two (2) inside that bucket. This means that this row will go to AMP 2.
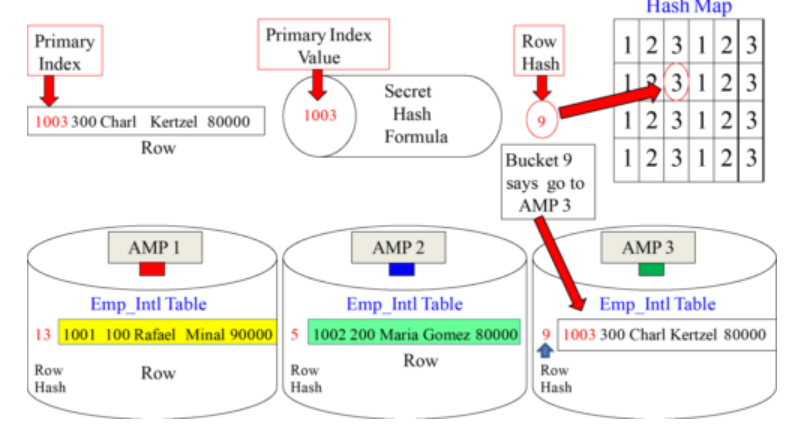
- Than for examples if hashed Emp_No 1003 (Primary Index value) and the output was a Row Hash of 13. Teradata counted over to bucket 9 in the Hash Map, and it has the number one (3) inside that bucket. This means that this row will go to AMP 3
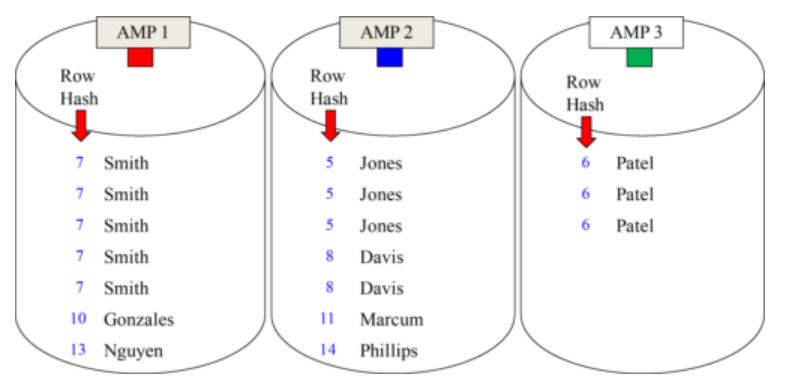
Hashing Theory For Non- Unique Primary Indexes have Skewed Data
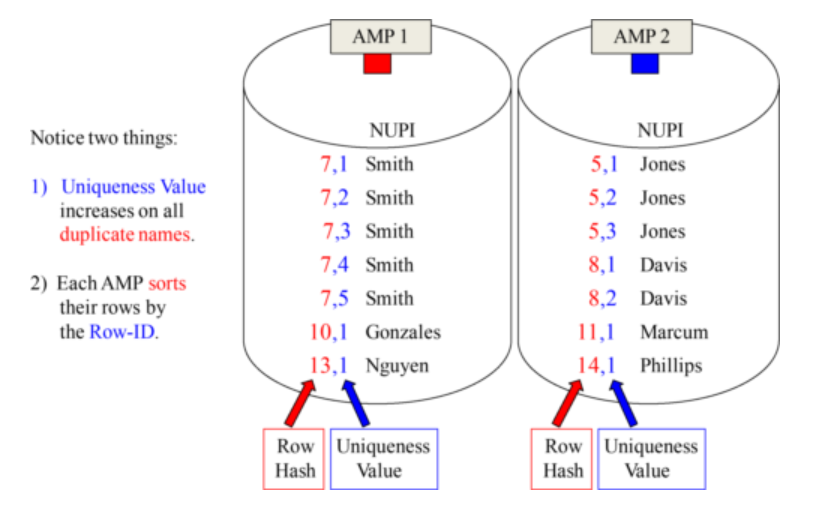
- For Example, if we made Last_Name the Primary Index for a table. Here is an example of how it would distribute. Notice all duplicates have the same Row Hash.
- The Hash Formula is consistent so every Smith has the same Row Hash and the same goes for each Jones and each Patel. Therefore, duplicate values land on the same AMP.
What Uniqueness Value ?
Each AMP will place a Uniqueness Value after the row hash to track duplicate values.

What is ROW ID?
The Row Hash and Uniqueness Value make up the Row-ID.
Row-ID equals the Row Hash of the Primary Index column and the Uniqueness Value
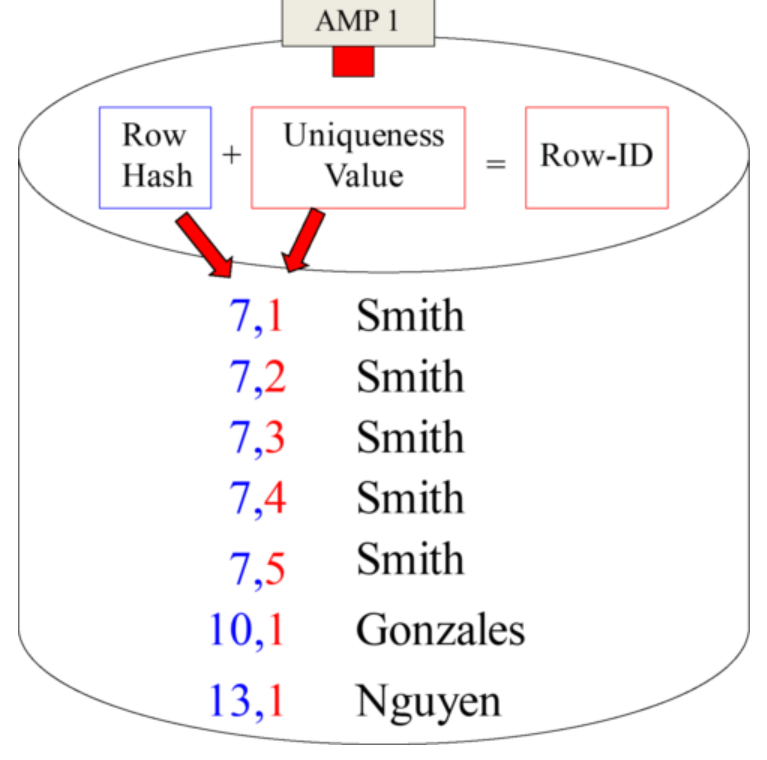
A Row-ID Example for a Unique Primary Index
The two things for this Unique Primary Index (UPI) example:
1) The Uniqueness Value on each Row-ID is 1.
2) Each AMP sorts their rows by the Row-ID .
Row Hash and the Uniqueness Value make up the Row-ID. AMPs sort by the Row-ID.
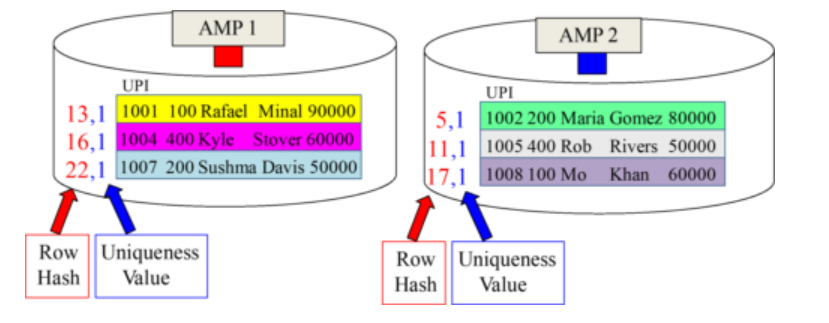
A Row-ID Example for a Non-Unique Primary Index (NUPI)
Row Hash and the Uniqueness Value make up the Row-ID. AMPs sort by the Row-ID.
Why each AMP Sorts their rows by the Row-ID?
Two Reasons why each AMP Sorts their rows by the Row-ID
- AMPs sort rows by Row-ID so like data is grouped together
- For Binary searches
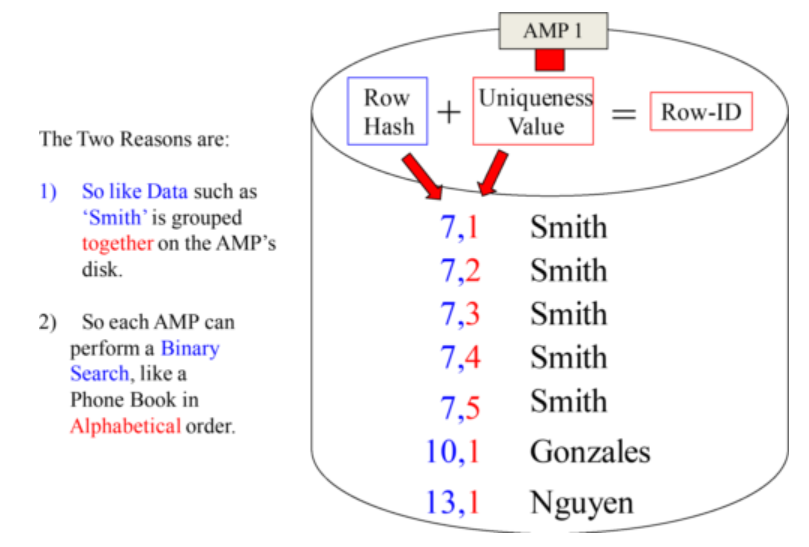
AMPs sort their rows by Row-ID to Group like Data
All of the Smiths are lumped together because of the sorting by Row-ID.

AMPs sort their rows by Row-ID to do a Binary Search
A Binary Search knows the Row-IDs are in numeric order. It’s like you using a phone book. Go to the middle first and then go up or down in chunks to find things quickly.
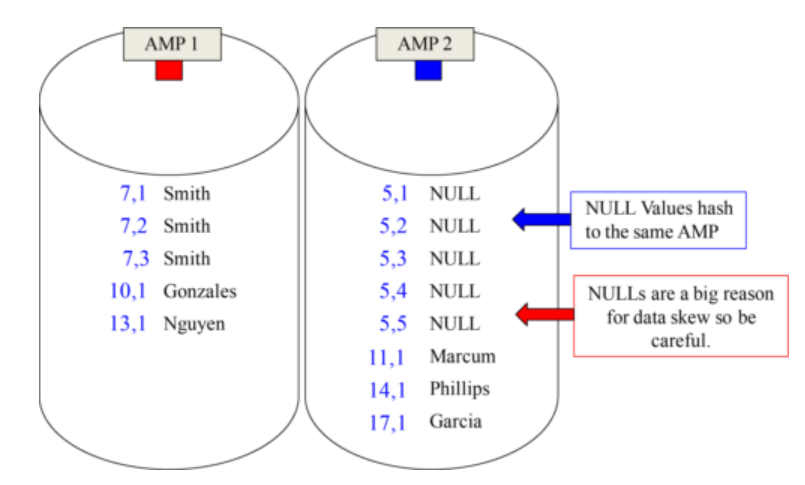
Important Point:
Null Values all Hash to the Same AMP
If there are NULL values in the Primary Index, you could find this is the reason for your skew. A Table with a Unique Primary Index can have only one Null value, but a NUPI table can have many NULL values, and each NULL value hashes to the same AMP.
Checking data distribution of given columns on the AMP
SELECT HASHAMP(HASHBUCKET(HASHROW([columnlist]))),COUNT(*) FROM [databasename].[tablename] GROUP BY 1 ORDER BY 2 DESC;
MotoShare.in is your go-to platform for adventure and exploration. Rent premium bikes for epic journeys or simple scooters for your daily errands—all with the MotoShare.in advantage of affordability and ease.
Find Trusted Cardiac Hospitals
Compare heart hospitals by city and services — all in one place.
Explore Hospitals



