
DataOps is an automated, process-oriented methodology, used by analytic and data teams, to improvise the quality and reduce the cycle time of data analytics.
While DataOps began as a set of best practices, it has now matured to become a new and independent approach to data analytics. DataOps, short for “data operations,” brings rigor to the development and management of data pipelines.
DataOps is a collaborative data management practice focused on improving the communication, integration and automation of data flows between data managers and data consumers across an organization.
The goal of DataOps is to deliver value faster by creating predictable delivery and change management of data, data models and related artifacts.
This merging of software development and IT operations has improved velocity, quality, predictability and scale of software engineering and deployment.
Category
Concept
History & Origin
- DataOps was introduced by Lenny Liebmann on June 19, 2014.
- The term DataOps was famoused by Andy Palmer of Tamr and Steph Locke.
Major Use Cases
- “To accelerate and scale an analytics deployment.” …
- “To remote facility visibility and want to perform multi-site analysis.” …
- “To distribute industrial data to multiple business systems.” …
- “To securely provide customers with data from my machines
Founder Company/Person
Justin Mullen
Advantage of using of DataOps
1. Faster process – This methodology aims to help enterprises implement an approach that makes it possible to manage and use their increasing data volumes effectively while reducing the cycle time of data analytics.
2. Real-time insights – By Fasten the entire data analytics process, you come closer to real-time insights in your data. In the fast-changing world, we live in, we need to have the capability to adapt any market changes, as fast as we can. DataOps place code and configuration continuously from development environments into production, heading to near real-time data insights.
3. Focus on import issues – With the time-savings and more accurate data analytics, your data team can now aims on the market needs and changes, immediately. DataOps permits IT leaders to focus on improvising communication, integration, and automation of data flows enterprise-wide.
Without the load of inefficiencies and poor quality, data science teams can focus on their domain of expertise; creating new models and analytics that fuel business innovation and create a competitive advantage
4. Catch errors immediately – With the help of DataOps, especially SPC, output tests can catch improperly processed data before it is passed downstream. Tests make sure the credibility and quality of the final output by verifying that work-in-progress (the results of intermediate steps in the data pipeline) matches expectations.
Components of DataOps

- Use source control management: A data pipeline is nothing but source code responsible for converting raw content into useful information. We can automate the data pipeline end-to-end, producing a source code which can be consumed in reproducible fashion. A revision control tool (like GitHub) helps to store and manage all of the changes to code and configuration to minimize inconsistent deployment.
- Automate DataOps process and workflow: For DataOps methodology to be successful, automation is the key and requires a data pipeline designed with run-time flexibility. Important requirements to achieve this are automated data curation services, metadata management, data governance, master data management, and self-service interaction.
- Add data and logic tests: To be certain that the data pipeline is functioning properly, testing of inputs, outputs, and business logic must be applied. At each stage, the data pipeline is tested for accuracy or potential deviation along with errors or warnings before they are released to have consistent data quality.
- Work without fear with consistent deployment: Data analytics professionals dread the prospect of deploying changes that break the current data pipeline. This can be addressed with two key workflows, which later integrate in production. First, the value pipeline creates continuous value for organizations. Second, the innovation pipeline takes the form of new analytics undergoing development which are later added to the production pipeline.
- Implement communication and process management: Efficient and automated notifications are critical within a DataOps practice. When changes are made to any source code; or when a data pipeline is triggered, failed, completed or deployed, the right stakeholders can be notified immediately. Tools to enable cross-stakeholder communications are also part of the toolchain (think Slack or Trello).
Terminologies of DataOps
Methodogy, Data Scientists, Data analysts, Data Engineers, Data Management, Practice, Automation
Architecture of DataOps & How DataOps works?
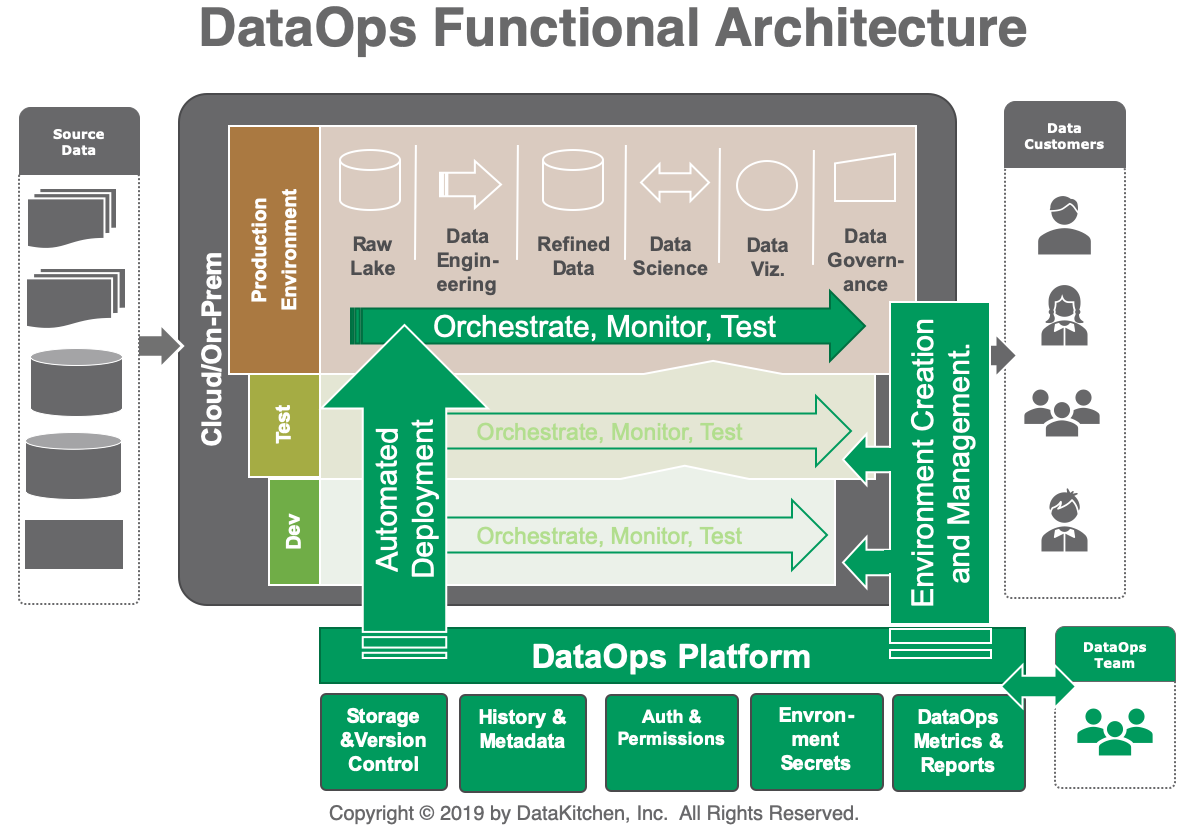
The DataOps architecture contains support for environment creation and management. This enables separate development, test, and production environments, which in turn support orchestration, monitoring, and test automation.
Best Resources for DataOps
https://www.unraveldata.com/resources/dataops/
Free Video Tutorials of DataOps
Interview Questions and Answers
1. What are DataOps principles?
“DataOps is a data management method that emphasizes communication, collaboration, integration, automation and measurement of cooperation between data engineers, data scientists and other data professionals.”
2. Why we need DataOps?
DataOps helps overcome the hurdles and complexities and deliver analytics with speed and agility, without compromising on data quality. It derives inspiration from the practices of Lean Manufacturing, Agile and DevOps.
3. What is DataOps medium?
In a nutshell, DataOps applies Agile development, DevOps and lean manufacturing to data-analytics development and operations. … DevOps *is a natural result of applying lean principles (eliminate waste, continuous improvement, broad focus) to application development and delivery.
**4. What is the difference between DevOps and DataOps?##
DevOps is the transformation in the delivery capability of development and software teams whereas DataOps focuses much on the transforming intelligence systems and analytic models by data analysts and data engineers.
4. Who invented DataOps?
- Lenny Liebmann
History. DataOps was first introduced by Lenny Liebmann, Contributing Editor, InformationWeek, in a blog post on the IBM Big Data & Analytics Hub titled “3 reasons why DataOps is essential for big data success” on June 19, 2014.
5. What is DataOps engineer?
The DataOps Engineer designs the data assembly line so that data engineers and scientists can produce insight rapidly and with the fewest possible errors. You might say that DataOps Engineers own the pipelines and the overall workflow, whereas data scientists and others work within the pipelines.
6. What is StreamSets data collector?
StreamSets Data Collector Engine is an easy-to-use data pipeline engine for streaming, CDC and batch ingestion from any source to any destination. “Data Collector Helps Speed Up Development Time”
7. How do I start DataOps?
- The Wild West of data development. Good stuff. …
- Get down the basics. First, get out of your head any notion that DataOps is just DevOps applied to data. …
- Make people a priority. …
- Manage the processes, take on the tools. …
- Build the case for DataOps. …
- Get going! …
- Adopting DataOps: Lessons for leaders.
8. What is DataOps team?
DataOps (data operations) is an agile, process-oriented methodology for developing and delivering analytics. It brings together DevOps teams with data engineers and data scientists to provide the tools, processes and organizational structures to support the data-focused enterprise.
9. What are the two main roles of tests in DataOps?
- Testing Enables DataOps
In production, tests ensure that data flowing through analytics is error free and that changes to data sources or databases do not break analytics.
10. What is data architecture in data analytics?
Data architecture is a framework for how IT infrastructure supports your data strategy. The goal of any data architecture is to show the company’s infrastructure how data is acquired, transported, stored, queried, and secured. A data architecture is the foundation of any data strategy.
11. What are DataOps tools?
Developed by Netflix, the DataOps tool is an open-source engine that offers distributed job orchestration services. This tool provides RESTful APIs for developers who wish to run a wide range of jobs with Big Data, such as Hive, Hadoop, Presto, and Spark.
12. What are the three pipelines of DataOps?
DataOps and data pipelines affect all three parts of the “Golden Triangle” — people, process, and technology.
13. What is industrial DataOps?
DataOps (data operations) is the orchestration of people, processes, and technology to securely deliver trusted, ready-to-use data to all who require it. … Ultimately, industrial DataOps is a tool for manufacturers to establish and maintain their critical data infrastructure in order to achieve digitalization.
14. What is DataOps orchestration?
Orchestration. The heart and soul of DataOps is orchestration. Moving, processing, and enriching data as it goes through a pipeline requires a complex workflow of tasks with numerous dependencies.
15. WHAT IS DATAOPS?
DataOps is enterprise data management for the AI era. It applies lessons learned from DevOps to data management and analytics. Effective deployment of DataOps has shown to accelerate time to market for analytic solutions, improve data quality and compliance, and reduce cost of data management.
16. WHAT IS A DATAOPS FRAMEWORK?
The framework for your DataOps combines five essential elements that range from technologies up to full-on culture change. The first element is enabling technologies, many of which are probably in your enterprise already (including IT automation, data management tools), as well as AI and machine learning (ML). The second is an adaptive architecture that supports continuous innovations in major technologies, services and processes. The third is enrichment of your data, putting it into useful context for accurate analysis. That means intelligent metadata that the system creates automatically, often at ingestion to save time later in your data pipeline. The fourth is the DataOps methodology to build and deploy your analytics and data pipelines, following your data governance and model management.
Best Certifications in DataOps?
- Big Data MasterTrack Certificate
- IBM Data Engineering Fundamentals
- DevOps Engineer Master’s Program
Best Courses and Insitute for learning
Again its
1. Big Data MasterTrack Certificate
2. IBM Data Engineering Fundamentals
3. DevOps Engineer Master’s Program
The best Institute for learning DataOps is DevOpsSchool. DevOpsSchool is one of the best institute that provides training as well as certification, not only in DatOps but in so many other courses as well. DevOpsSchool has highly skilled trainers who have 10+ years of experience. This institute knows what is the need of the participants and what kind of skills IT companies looking in their employee. That’s why their course contents are as per IT company standards so their participants could meet the expectations in interview.
There are lots of other benefits are as well that is provided by DevOpsSchool that, they provide completely online and live interactive classes so the participants can feel the same atmosphere that they feels in offline classes. Pdfs, class recording and so many things they provide to participants for their refernece.
Their course contents are also very vast that is not provided by any institutes and in that much price. Its really a best Institutes to get trained.
Reference
Reference
- What is DevOps?
- DataOps Certifications
- DataOps Consultants
- DataOps Consulting Company
- Best DataOps Courses
- Best DataOps Tools
- Best DataOps Trainer
- Best DataOps Training
I’m Rajesh Kumar, a DevOps, SRE, DevSecOps, Cloud, and Platform Engineering expert passionate about sharing practical knowledge, real-world experiences, and industry best practices. I have worked at Cotocus and regularly write about technology, travel, investing, health, product reviews, and digital marketing through my various platforms.
I publish technical articles at DevOps School, travel stories at Holiday Landmark, stock market insights at Stocks Mantra, health and fitness guidance at My Medic Plus, product reviews at TrueReviewNow, and SEO and digital marketing strategies at Wizbrand.
Find Trusted Cardiac Hospitals
Compare heart hospitals by city and services — all in one place.
Explore Hospitals