Site Reliability Engineering is also referred as SRE. This is a phrase or a term that is being used very much nowadays but it was coined by Ben Treynor from Google in the year 2003. Site reliability engineering is a software engineering strategy or methodology and discipline that takes up the aspects of software engineering and applies them to infrastructure and operations problems.
In SRE we try to use the principles of software engineering and apply them to these problems:
- How to manage your infrastructure?
- How to manage your operations?
- How to solve those operation problems? –OPeration problems are like deployment like you have production releases, upgrades, these kinds of things are there.
SRE is to create highly reliable and scalable software system that can run with minimum failure
The primary goal of SRE engineers is to create a highly reliable and scalable software system. Developers can develop things but now it has to be a reliable system and scalable and the system should run with minimum failure for a longer duration in different environmental conditions. No system runs for always, there will be some issues but those failures, how do we minimize them and how we can make sure that it keeps running for a very long duration. So if you see services like GMAIL, Google, they have been like very strong in SRE, they have been running like without any failure for a much longer period time. So behind the scene, there are principles of SRE that take place.
Some people view SRE as an implementation of DevOps.
In DevOps we have Development, QAs, Operations, it’s a mix of these profiles and that’s how DevOps was formed. So, in DevOps there are some companies that have separate DevOps teams. Similarly, some companies that have separate SRE teams because nowadays SRE and DevOps are part of the developer. Each Developer has to know these SREs capabilities, each developer has to know the DevOps culture, that way we can say it’s not a separate department.
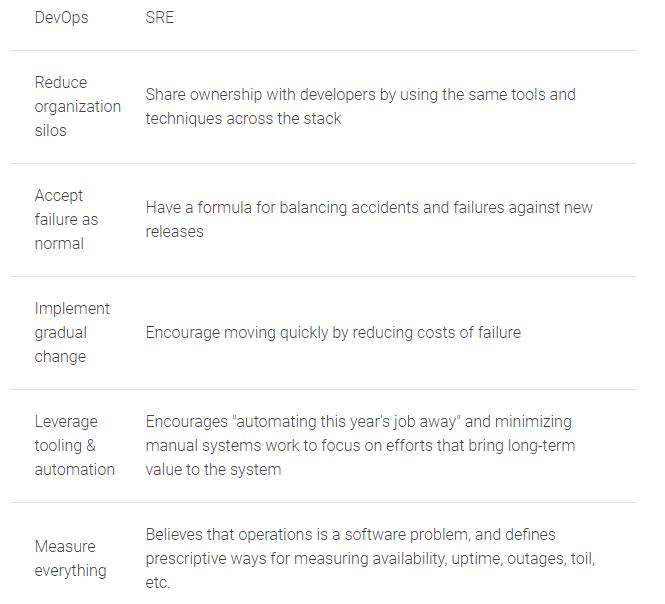
SREs share the ownership of the system with the Developers.
That is now what the trend is. They sit along with developers rather than focus on specific things, they work with developers and try to share that and SREs use the development tools which are similar to the ones used by developers. They use similar IDs, similar CI/CD patterns from the agile processes, that way we increase the reliability of the site our servers for that we use similar tools for that.
SRE accepts the fact that failure can happen and prepare the system towards handling those failures.
As an SRE we expect that there will be some failure but we have to prepare the system so that these failures can be handled. If we prepare the system then failures can be gracefully handled and the system will become more reliable
SREs quantify the failures and availability of a system and track these against the Service Level Agreement (SLA) of the system.
whenever there are any failures we try to quantify and we see what is the availability of a system because of these failures its reduce and then we track these against our service level agreement. Based on that we can see our system is highly available 99.997% of the time, what is tp 99 performance, what are the SLA we are meting, is there a breach in an SLA. SO those kinds of things we try to provide once we measure it then only we can improve it.
SREs perform root cause analysis and perform post mortems of issues.
Whenever there are any issues, SREs perform root cause analysis, if we say what is the root cause of this issue? how can we resolve it? do the post mortem of the issue – what are the different causes that are causing it, what preventive action we can take in the future so that these issues do not occur.
SREs instill the concept of product ownership in developers by reducing the cost of failures.
SREs have a concept of product ownership. In the developers so that we can reduce the cost of failures, in earlier time ops was different and like you know developers were different but nowadays developers are playing the role of SREs so they know this product is owned by themselves, so they have to maintain it, they have to support it. So product ownership increases the quality of the product.
SREs try to automate non-productive tasks
From time to time as a SRE Certification try to automate non-productive tasks there is some kind of deployment, test that are running, SRE try to automate that, so that we get higher efficiency from that
SREs measure various aspects like-latency, SLA, failure counts etc. of the system.
This is one of the measure aspect. SREs measure everything like latency, SLA, failure counts because after measuring only we can know this is our current level and then we can set our higher goals to that level.
SREs work with the mindset that any system operation can be a failure.
As an SREs you need to be prepared to handle those failures with a positive attitude and in a way that it takes minimum impact from that failure
What is the difference between DevOps and SRE (DevOps Vs SRE)
IS SRE DevOps 2.0?
- No
IS SRE trying to overtake DevOps??
- NO
Can I adopt both DevOps & SRE??
- Yes
We in DevOpsSchool recently integrated Site Reliability Engineering course. When it comes to all the latest technologies, having theoretical knowledge from books and from other sources are not relevant. keeping in mind the job market demands you need to have practical experience with good hands-on experience. Our courses are highly career oriented and our trainers taking up these classes are industry experts who have immense experience in that particular tech. This is where we come in as a difference, we provide a real-time scenario based project at the end of our courses so that our learners can leverage from it.
DevOps Vs. SRE: Competing Standards or Friends? (Cloud Next ’19)
MotoShare.in delivers cost-effective bike rental solutions, empowering users to save on transportation while enjoying reliable two-wheelers. Ideal for city commutes, sightseeing, or adventure rides.
Find Trusted Cardiac Hospitals
Compare heart hospitals by city and services — all in one place.
Explore Hospitals