CouchDB is a document-oriented database and within each document fields are stored as key-value maps. Fields can be either a simple key/value pair, list, or map. It is an open-source document-oriented NoSQL database, implemented in Erlang. CouchDB uses multiple formats and protocols to store, transfer, and process its data. It uses JSON to store data, JavaScript as its query language using MapReduce, and HTTP for an API.
Each document that is stored in the database is given a document-level unique identifier (_id) as well as a revision (_rev) number for each change that is made and saved to the database.
Unlike a relational database, a CouchDB database does not store data and relationships in tables. Instead, each database is a collection of independent documents. Each document maintains its own data and self-contained schema. An application may access multiple databases, such as one stored on a user’s mobile phone and another on a server. Document metadata contains revision information, making it possible to merge any differences that may have occurred while the databases were disconnected.
CouchDB implements a form of multisession concurrency control (MVCC) so it does not lock the database file during writes. Conflicts are left to the application to resolve. Resolving a conflict generally involves first merging data into one of the documents, then deleting the stale one.
History
The CouchDB project was created in April 2005 by Damien Katz, a former Lotus Notes developer at IBM. In February 2008, it became an Apache Incubator project and was offered under the Apache License instead, first stable version being released in July 2010.
In early 2012, Katz left the project to focus on Couchbase Server. In July 2013, the CouchDB community merged the codebase for BigCouch, Cloudant’s clustered version of CouchDB, into the Apache project. The BigCouch clustering framework is included in the current release of Apache CouchDB.
What are the Features of CouchDB?
Features of CouchDB includes the following:
- Replication: It provides the simplest form of replication and no other database is so simple to replicate.
- Document Storage: It is a NoSQL database that follows document storage where each field is uniquely named and contains values of various data types such as text, number, Boolean, lists, etc.
- ACID Properties: The CouchDB file layout follows all the features of ACID properties.
- Security: It also provides database-level security and the permissions are divided into readers and admins where readers can do both the read and write to the database.
- Map/Reduce: The main reason for the popularity of CouchDB is a map/reduce system.
- Authentication: CouchDB facilitates you to keep authentication open via a session cookie-like a web application.
- Built for Offline: CouchDB can replicate to devices like smartphones that have a feature to go offline and handle data sync for you when the device is back online.
- Eventual Consistency: CouchDB guarantees eventual consistency to provide both availability and partition tolerance.
- HTTP API: All items have a unique URI (Unique Resource Identifier) that gets exposed via HTTP. It uses the HTTP methods like POST, GET, PUT, and DELETE for the four basic CRUD (Create, Read, Update, Delete) operations on all resources.
What is the main reason behind using CouchDB?
- CouchDB is easy to use. There is one word to describe CouchDB “Relax”. It is also the byline of CouchDB official logo.
- CouchDB have an HTTP-based REST API, which makes communication with the database very easy.
- CouchDB has the simple structure of HTTP resources and methods (GET, PUT, DELETE) that are easy to understand and use.
- In CouchDB, data is stored in the flexible document-based structure so, there is no need to worry about the structure of the data.
- CouchDB facilitates users with powerful data mapping, which allows querying, combining, and filtering the information.
- CouchDB provides easy-to-use replication, using which you can copy, share, and synchronize the data between databases and machines.
CouchDB Data Model
- Database is the outermost data structure/container in CouchDB.
- Each database is a collection of independent documents.
- Each document is responsible for maintaining its own data and self-contained schema.
- Document metadata contains revision information, which makes it possible to merge the differences occurred while the databases were disconnected.
- CouchDB implements multi version concurrency control, to avoid the need to lock the database field during writes.
The architecture of CouchDB is described below:
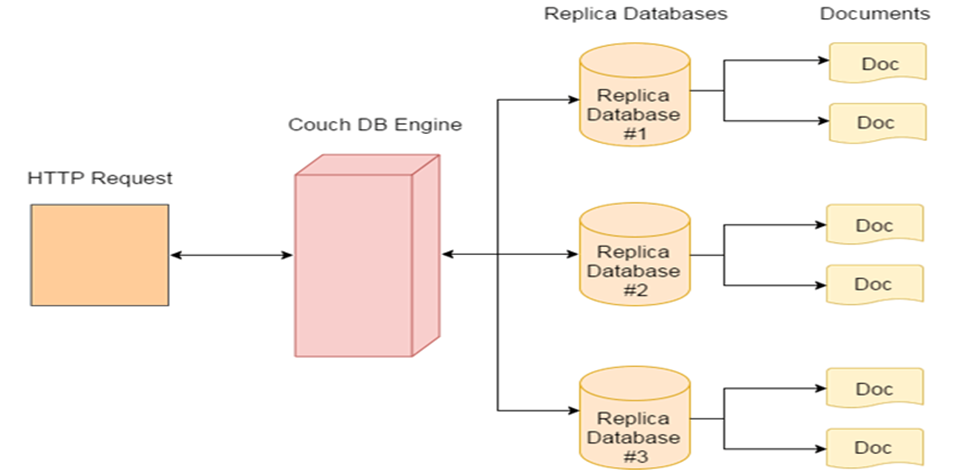
- CouchDB Engine: It is based on B-tree and in it, data is accessed by keys or key ranges which map directly to the underlying B-tree operations. It is the core of the system which manages to store internal data, documents, and views.
- HTTP Request: It is used to create indices and extract data from documents. It is written in JavaScript that allows creating Adhoc views that are made of MapReduce jobs.
- Document: It stores a large amount of data.
- Replica Database: It is used for replicating data to a local or remote database and synchronizing design documents.
Installing CouchDB:
- Download CouchDB software from official website.
- Install the downloaded software.
- Now visit the link http://127.0.0.1:5984/.
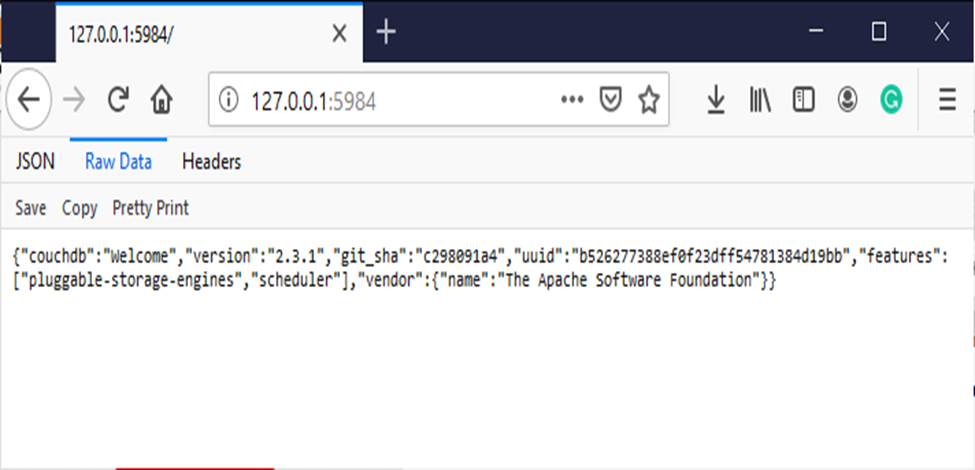
- To interact with CouchDB web interface go to the link
http://127.0.0.1:5984/_utils/.
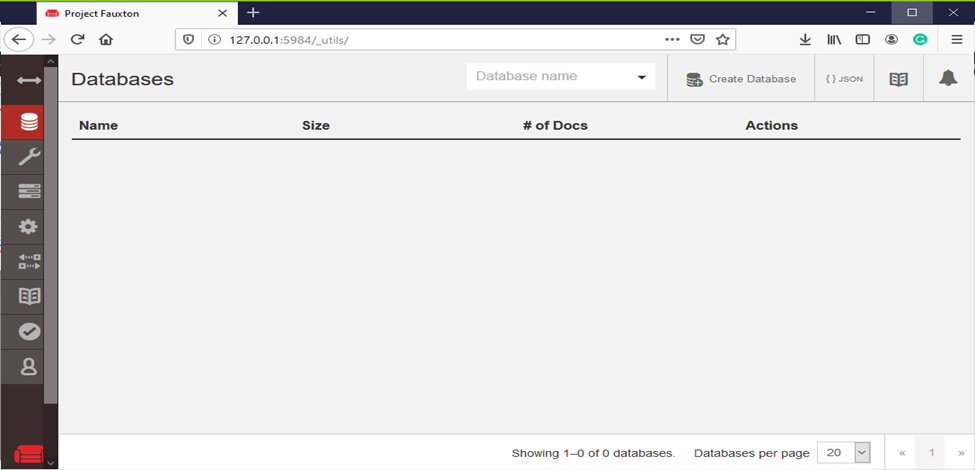
Now, you have successfully installed CouchDB.
I hope you find this particular blog about Apache CouchDB informative and helpful.
Thank You!!
Find Trusted Cardiac Hospitals
Compare heart hospitals by city and services — all in one place.
Explore Hospitals

