Instant Kubernetes-Native Application Observability
Pixie gives you instant visibility by giving access to metrics, events, traces and logs without changing code.
Pixie is an open source observability tool for Kubernetes applications. Pixie uses eBPF to automatically capture its telemetry data without the need for manual instrumentation.
Using Pixie, developers can view the high-level state of their cluster (service maps, cluster resources, application traffic) and also drill-down into more detailed views (pod state, flame graphs, individual application requests).
Pixie was contributed by New Relic to the CNCF as a sandbox project in June 2021.
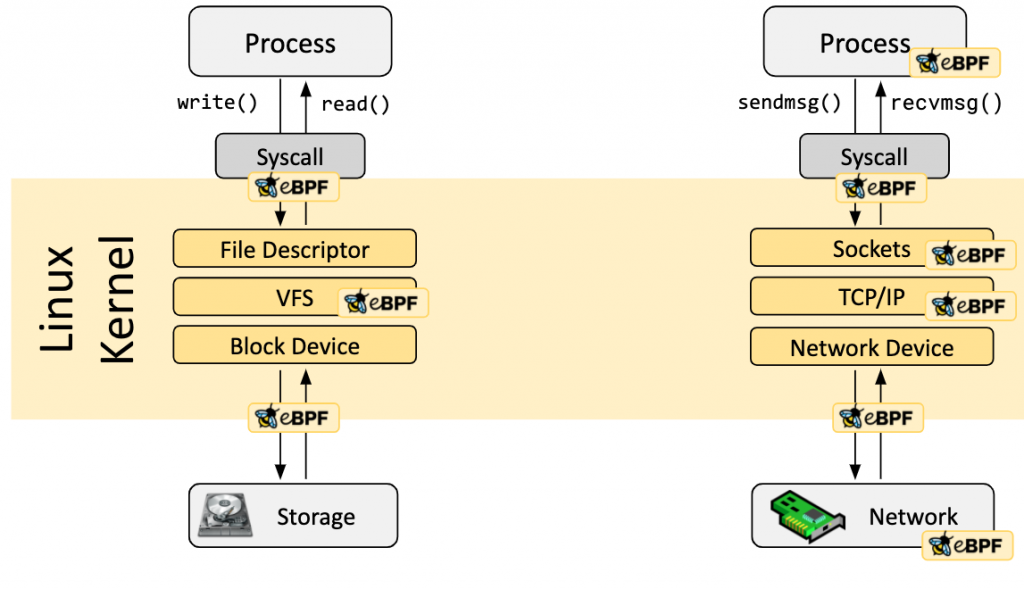
What is eBPF?
The Linux kernel has always been an ideal place to implement monitoring/observability, networking, and security. Unfortunately this was often impractical as it required changing kernel source code or loading kernel modules, and resulted in layers of abstractions stacked on top of each other.
eBPF is a revolutionary technology that can run sandboxed programs in the Linux kernel without changing kernel source code or loading kernel modules. By making the Linux kernel programmable, infrastructure software can leverage existing layers, making them more intelligent and feature-rich without continuing to add additional layers of complexity to the system.
eBPF has resulted in the development of a completely new generation of tooling in areas such as networking, security, application profiling/tracing and performance troubleshooting that no longer rely on existing kernel functionality but instead actively reprogram runtime behavior without compromising execution efficiency or safety.
Features of Pixie
- Auto-telemetry: Using eBPF, Pixie automatically collects telemetry data such as full-body requests, resource metrics, and network statistics.
- In-cluster edge compute: Pixie runs directly on the Kubernetes cluster and stores all telemetry data locally. Pixie uses less than 5% of cluster CPU, and in most cases less than 2%.
- Scriptability: PxL, Pixie’s flexible, Pythonic query language, can be used across Pixie’s UI, CLI, and client APIs.
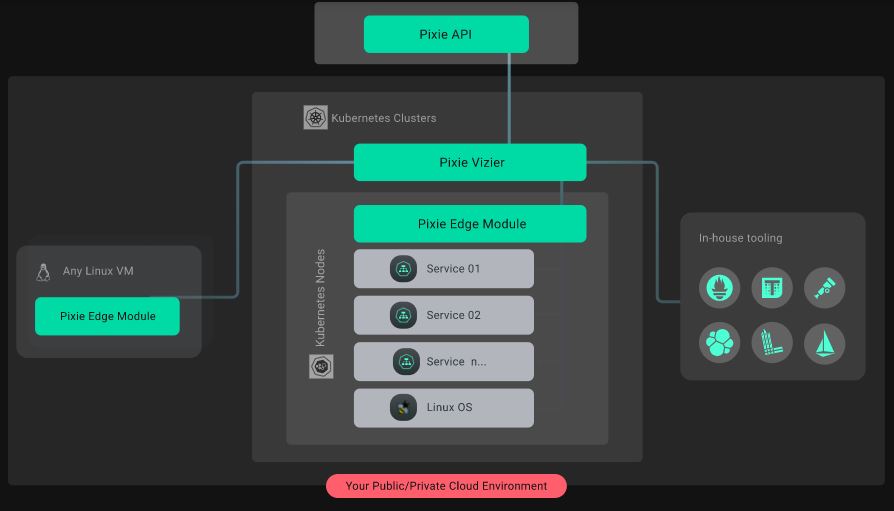
How Pixie works?
When Pixie is deployed on a Kubernetes cluster, it uses eBPF to automatically collect a rich set of data sources. These include full-body requests traces, resource and network metrics, and application profiles
Three fundamental innovations enable Pixie’s magical developer experience:
Progressive Instrumentation: Pixie Edge Modules (“PEMs”) collect full body request traces (via eBPF), system metrics & K8s events without the need for code-changes and at less than 5% overhead. Custom metrics, traces & logs can be integrated into the Pixie Command Module.
In-Cluster Edge Compute: The Pixie Command Module is deployed in your K8s cluster to isolate data storage and computation within your environment for drastically better intelligence, performance & security.
Command Driven Interfaces: Programmatically access data via the Pixie CLI and Pixie UI which are designed ground-up to allow you to run analysis & debug scenarios faster than any other developer tool.
Pixie Architecture
- Pixie Edge Module (PEM): Pixie’s agent, installed per node. PEMs use eBPF to collect data, which is stored locally on the node.
- Vizier: Pixie’s collector, installed per cluster. Responsible for query execution and managing PEMs.
- Pixie Cloud: Used for user management, authentication, and proxying “passthrough” mode. Can be hosted or self-hosted.
- Pixie CLI: Used to deploy Pixie. Can also be used to run queries and manage resources like API keys.
- Pixie Client API: Used for programmatic access to Pixie (e.g. integrations, Slackbots, and custom user logic requiring Pixie data as an input)
Why use Pixie?
No Instrumentation
Access metrics, events, traces and logs in seconds without changing code via dynamic eBPF probes and ingestors. Add logging only for custom data.
Debug with Scripts
Run community, team or custom scripts to debug as code. Publish and share your sessions as code with your team and global Pixienaut community.
Kubernetes Native
Pixie runs entirely inside your Kubernetes clusters without storing any customer data outside. Avoid trading-off depth of visibility due to the hassle and cost of trucking petabytes of telemetry off-cluster.
Reference
- https://docs.px.dev/installing-pixie/quick-start/
- https://github.com/pixie-labs/pixie-docs
- https://github.com/pixie-labs/pxapi.go
- https://github.com/pixie-labs/pixie
- https://px.dev/
I’m Rajesh Kumar, a DevOps, SRE, DevSecOps, Cloud, and Platform Engineering expert passionate about sharing practical knowledge, real-world experiences, and industry best practices. I have worked at Cotocus and regularly write about technology, travel, investing, health, product reviews, and digital marketing through my various platforms.
I publish technical articles at DevOps School, travel stories at Holiday Landmark, stock market insights at Stocks Mantra, health and fitness guidance at My Medic Plus, product reviews at TrueReviewNow, and SEO and digital marketing strategies at Wizbrand.
Find Trusted Cardiac Hospitals
Compare heart hospitals by city and services — all in one place.
Explore Hospitals