JFrog Artifactory Architecture: Comprehensive Overview
JFrog Artifactory acts as the core of the JFrog Platform, providing robust, universal artifact management across the software supply chain. Its architecture is modular, scalable, and designed to fit both standalone and multi-site enterprise deployments.
Core Components
| Component | Description |
|---|---|
| Artifactory Application | The main server application, handling REST/API requests, artifact management, replication, and all core functions. Requires a DB and filestore to operate. |
| Database | Stores all metadata: user info, permissions, repo configs, artifact paths/names, and platform configuration. Recommended to use an external SQL DB (PostgreSQL, MySQL, etc.) for production. |
| Filestore (Binary Store) | Stores only the actual binaries (artifacts) themselves, organized by checksums (e.g., SHA-1). May use local storage, NFS, or cloud object storage (AWS S3, GCS, Azure Blob). |
Microservices (JFrog Platform, v7+)
| Service | Functionality |
|---|---|
| Router | Service discovery and internal API gateway, handling all traffic routing across microservices and products. |
| Access | Authentication, access control, group/user management, and access token issuance for all platform services. |
| Frontend | The user interface serving the web UI for all JFrog products in the deployment. |
| Topology | Manages platform topology, service registry, and node discovery within clustered deployments (from v7.104). |
| One Model | Central API model for all JFrog entities, providing consistency and a unified GraphQL API. |
| JFConnect | Manages subscription, licensing entitlements, and cloud checks. |
| Event | Handles platform-wide webhook and event distribution for automation and integrations. |
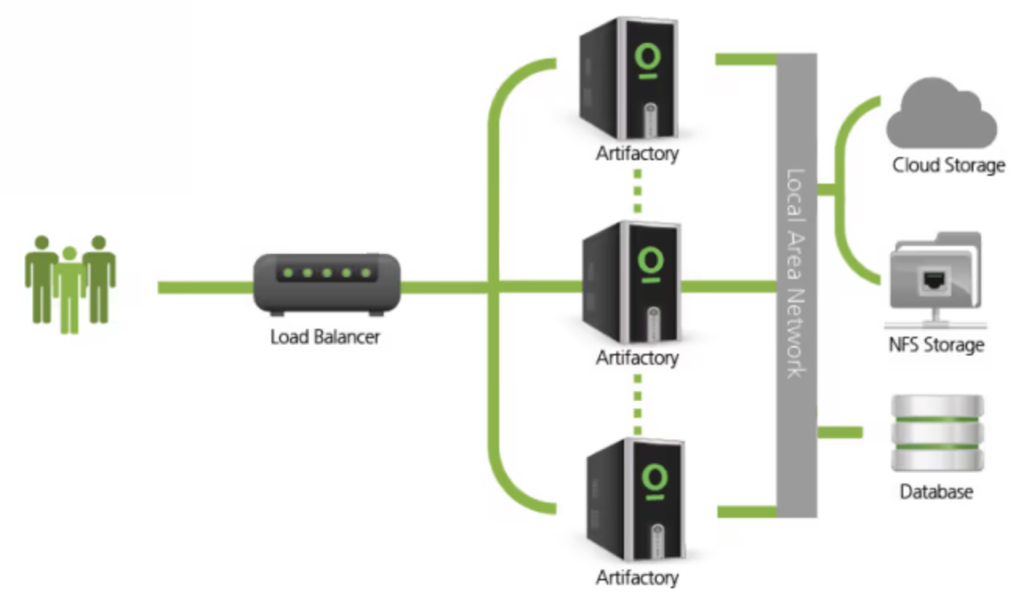
High Availability & Scalability
- HA Cluster: In enterprise mode, Artifactory nodes are grouped behind a load balancer. Nodes share the same external database and filestore, ensuring redundancy, failover, and horizontal scalability. Sessions are stateless, so users or jobs can connect to any node.
- Replication: Both unidirectional and bidirectional (federated) repository replication supported for DR, multi-site collaboration, and distributed pipelines.
- Edge Nodes: JFrog Edge servers enable caching and distribution closer to remote teams; critical for global or hybrid SaaS setups.
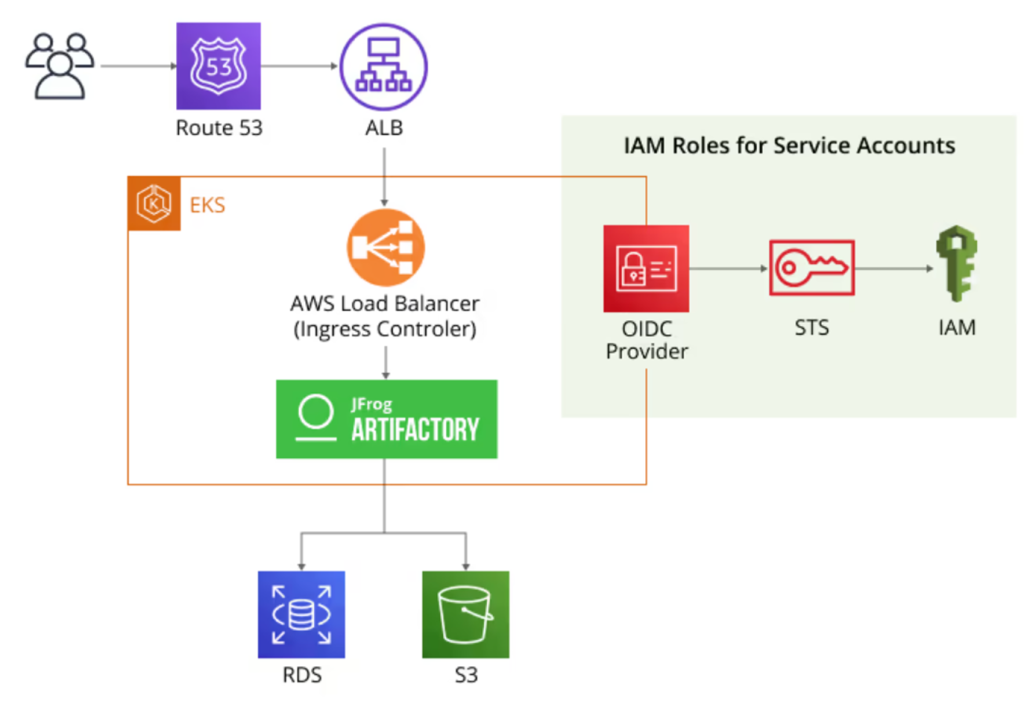
Deployment Models
- Single Node: All services deployed on one VM/container, suitable for evaluation, small teams, or edge.
- Multi-Node / HA: Active-active clusters with externalized DB and filestore for production.
- Hybrid/SaaS: Combines JFrog-managed SaaS core with on-prem or edge nodes for copliance or performance.
- Cloud-Native: Supports Kubernetes, scalable object storage, integrations with CSPs.
Key Platform Workflows
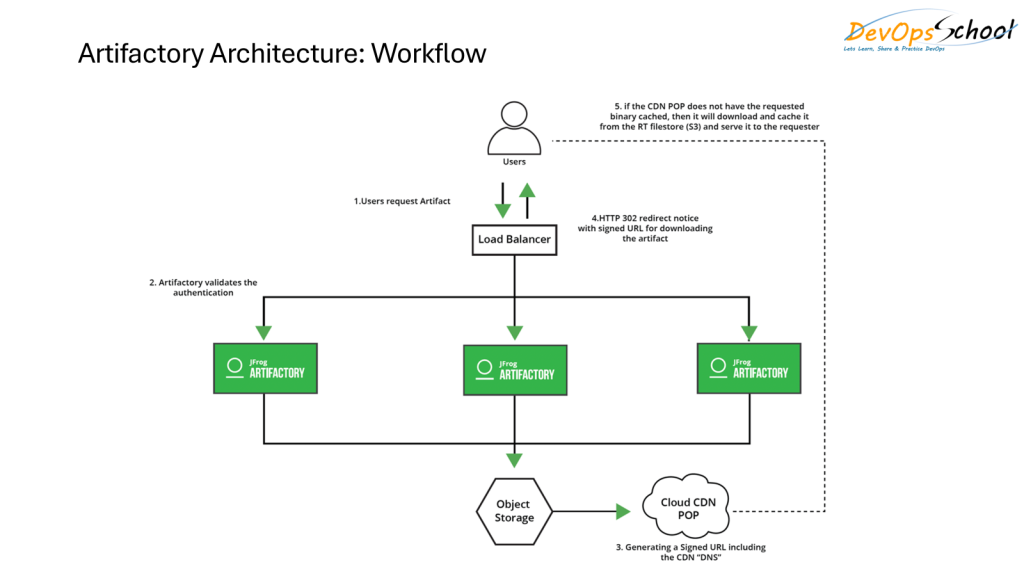
- Clients (browser, CI/CD servers, REST API, CLI, package managers) interact via a load balancer.
- Router directs requests to platform microservices or the core Artifactory server.
- Authentication & Access is managed by the Access service.
- Artifacts are stored in the filestore; all metadata is in the DB. File locations are mapped by checksum.
- Replication and event handling allow for automation, integration, and multi-site consistency.
Architecture Highlights
- Universal Format Support: 40+ package types, broad DevOps ecosystem compatibility.
- Stateless Services: Easy to scale both horizontally and vertically.
- API-Driven Automation: Extensive REST and GraphQL APIs available for all operations.
- Backup/DR: Backups cover DB + filestore; HA mode is recommended for critical workloads.
- Observability: Logging, access auditing, and real-time eventing is integrated.
- Governance: Role-based access, compliance, and security scanning (with Xray add-ons).
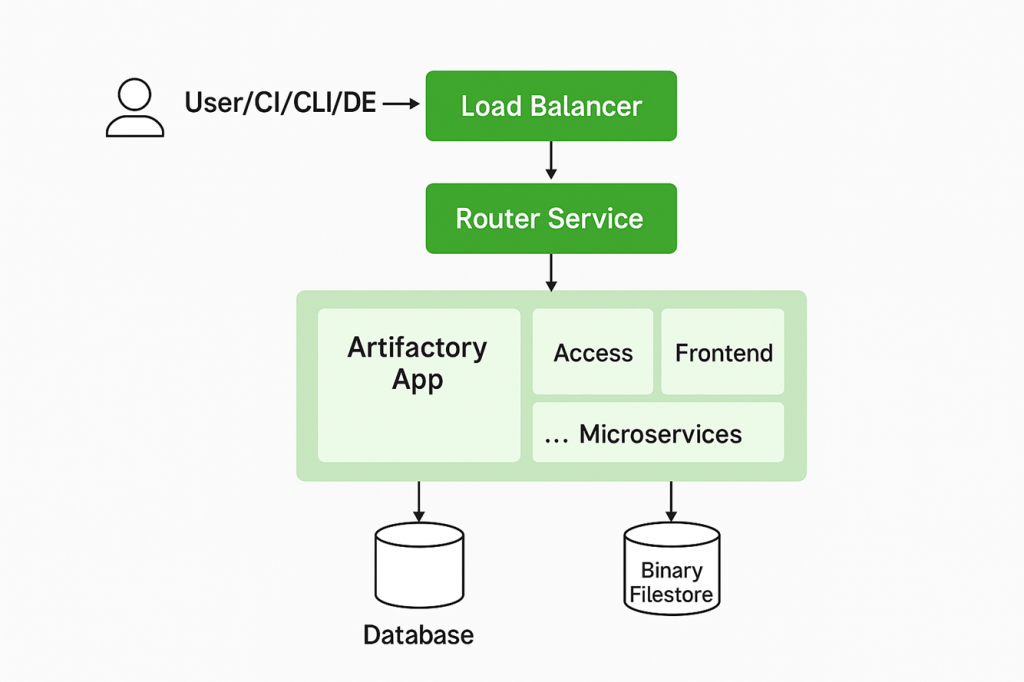
Sample High-level Architecture Diagram (Textual)
text+---------------------+ +-------------------+ +--------------------------+
| User/CI/CLI/IDE +-----> | Load Balancer +------> | Router Service |
+---------------------+ +-------------------+ +--------------------------+
|
+-------------------------+-----------+----------+---+---+------------------+
| Artifactory App | Access | Frontend | ... | Microservices |
+-------------------------+-----------+----------+---+---+------------------+
| |
+-------------------+ +-----------------------+
| Database | | Binary Filestore |
+-------------------+ +-----------------------+
Summary Table: Artifactory Architecture Capabilities
| Capability | Description |
|---|---|
| Artifact Storage | Highly scalable & pluggable filestore; all binary assets managed via checksum |
| Metadata Management | Relational DB for all config, repo, and artifact metadata |
| Multi-tenancy & RBAC | Fine-grained role/access control throughout |
| API/Automation | Full-featured REST API, scripted automation, and webhook/event platform |
| Scalability & HA | Active/active cluster mode with shared DB/file store; seamless failover, rolling upgrades |
| Multi-site/Edge | Support for federated and replicated topologies; edge node distribution for global organizations |
| Security & Compliance | Encrypted storage, access controls, audit logs, optional integrated scanning and policy engines (via JFrog Xray) |
| Observability | Unified logs, queryable event streams, and usage dashboards |
JFrog Artifactory’s architecture is engineered for performance, robustness, and flexibility, making it suitable for everything from small teams to the largest, most demanding global enterprises.
Here’s an overview of the JFrog Artifactory Architecture with its core components and how they interact:
✅ Key Components of Artifactory Architecture
1️⃣ User Interfaces
- Web UI: For admin and user interaction.
- REST API: For automation and integrations.
- JFrog CLI: Command-line interface to manage artifacts.
- CI/CD Tools: Jenkins, GitLab, Azure DevOps, etc.
2️⃣ Access Layer
- Load Balancer / Reverse Proxy: Routes traffic to Artifactory nodes (used in HA).
- Authentication & RBAC: SAML, LDAP, OAuth, API tokens.
3️⃣ Application Layer
- Artifactory Core Service: Handles repository management, metadata, and artifact lifecycle.
- Router Service: Manages API routing and internal service communication.
- Metadata Service: Stores artifact properties, build info, checksums.
- Replication Service: Manages syncing between instances and federated repositories.
4️⃣ Storage Layer
- Filestore: Stores actual binaries (local disk, NFS, or cloud object storage like S3, Azure Blob).
- Database: Stores metadata, configurations, permissions.
- Recommended: PostgreSQL for production.
- Checksum Storage: Deduplicates identical artifacts using SHA1/MD5.
5️⃣ Repository Types
- Local: Internal artifacts.
- Remote: Cached external dependencies.
- Virtual: Unified access endpoint.
- Federated: Cross-instance sync.
6️⃣ High Availability (HA) Architecture
- Multiple Artifactory Nodes: Active-active cluster for redundancy.
- Shared Filestore: NFS or Object Storage accessible by all nodes.
- External Database: Single source of metadata for all nodes.
- Load Balancer: Distributes requests.
7️⃣ Integrations
- JFrog Xray: Security scanning and license compliance.
- JFrog Pipelines: CI/CD automation integrated with Artifactory.
- JFrog Distribution: Signed, immutable release distribution.
- Third-Party Tools: Kubernetes, Helm, Terraform, Docker.
✅ Workflow Overview
- Developer/CI pipeline pushes artifact to Artifactory.
- Artifactory stores the binary in the Filestore and metadata in the DB.
- Metadata services manage indexing and checksum validation.
- Users or pipelines fetch artifacts via the Web UI, API, or CLI.
- In HA, requests go through Load Balancer → Artifactory Nodes → Shared Storage.
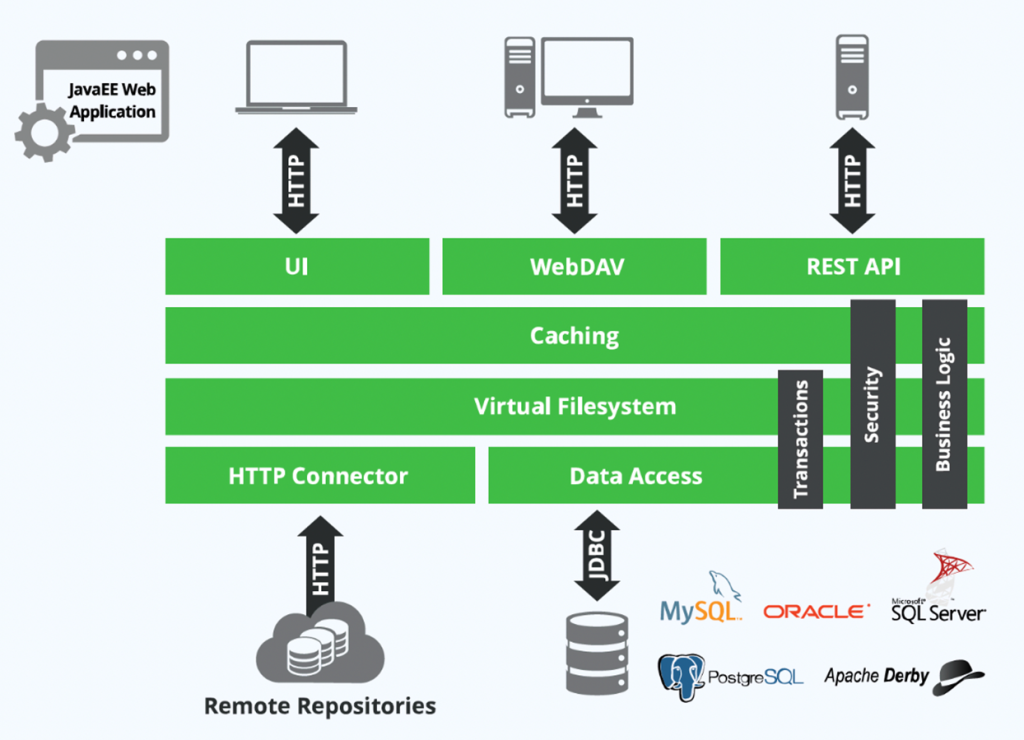
This diagram represents the architecture of JFrog Artifactory and how different components interact. Here’s an explanation of each part:
✅ Top Layer – Interfaces
- JavaEE Web Application
- The Artifactory server application built on JavaEE standards.
- Provides the web-based admin and user interface.
- Acts as the core platform to serve all user and API requests.
- UI
- The User Interface (web-based dashboard).
- Allows browsing repositories, uploading/downloading artifacts, and managing configurations via HTTP.
- WebDAV
- Web-based Distributed Authoring and Versioning.
- Enables mounting Artifactory as a network drive for easy drag-and-drop artifact management via HTTP.
- REST API
- Provides programmatic access to Artifactory functionality.
- Used by CI/CD pipelines, automation scripts, and integrations.
✅ Middle Layer – Core Services
- Caching
- Temporarily stores frequently accessed artifacts.
- Improves performance and reduces repeated requests to remote repositories.
- Virtual Filesystem
- Provides a unified, logical file structure to users.
- Aggregates artifacts from local, remote, and virtual repositories under a single namespace.
- Transactions
- Ensures atomic operations (upload/download) are consistent.
- Handles concurrent requests without data corruption.
- Security
- Manages authentication, authorization, and role-based access control (RBAC).
- Integrates with LDAP, SAML, OAuth, and API tokens.
- Business Logic
- Implements Artifactory’s core repository management rules.
- Handles artifact promotion, replication, checksum validation, and metadata processing.
✅ Bottom Layer – Connectors and Storage
- HTTP Connector
- Manages communication between Artifactory and external remote repositories via HTTP.
- Responsible for downloading external dependencies and caching them.
- Data Access
- Handles interaction with the metadata database using JDBC.
- Ensures artifact metadata, configuration, and permissions are stored reliably.
- Remote Repositories
- External artifact sources (e.g., Maven Central, npm registry, PyPI).
- Artifactory proxies and caches these via remote repositories.
- Databases
- Stores metadata, configuration, and access control data.
- Supported DBs:
- MySQL
- Oracle
- Microsoft SQL Server
- PostgreSQL (recommended)
- Apache Derby (for testing, not production)
✅ How It Works Together
- Users or CI/CD tools interact via UI, WebDAV, or REST API.
- Requests go through caching and virtual filesystem layers.
- Local artifacts are served from storage; external artifacts are fetched via HTTP connectors from remote repositories.
- Metadata is stored in the relational database via the Data Access layer.
- Security and business logic ensure access control and artifact lifecycle management.
I’m a DevOps/SRE/DevSecOps/Cloud Expert passionate about sharing knowledge and experiences. I have worked at Cotocus. I share tech blog at DevOps School, travel stories at Holiday Landmark, stock market tips at Stocks Mantra, health and fitness guidance at My Medic Plus, product reviews at TrueReviewNow , and SEO strategies at Wizbrand.
Do you want to learn Quantum Computing?
Please find my social handles as below;
Rajesh Kumar Personal Website
Rajesh Kumar at YOUTUBE
Rajesh Kumar at INSTAGRAM
Rajesh Kumar at X
Rajesh Kumar at FACEBOOK
Rajesh Kumar at LINKEDIN
Rajesh Kumar at WIZBRAND
Find Trusted Cardiac Hospitals
Compare heart hospitals by city and services — all in one place.
Explore Hospitals
Great explanation of JFrog Artifactory’s architecture! 📦 I like how the article breaks down the components and how they work together — it makes the overall design much easier to understand. Very informative — thanks for sharing this!