Here’s a curated list of top model serving frameworks—including your suggestions and a few other best-in-class options—plus a side-by-side comparison so you can see where each one shines.
Top Model Serving Frameworks (2026)
1. KFServing / KServe
- Kubernetes-native, multi-framework model serving.
- Advanced features: autoscaling, canary rollouts, versioning, pre/post processing, scale to zero.
- Supports: TensorFlow, PyTorch, scikit-learn, XGBoost, ONNX, HuggingFace, and custom containers.
2. Seldon Core
- Flexible, Kubernetes-native serving for any ML framework.
- Build complex inference graphs (ensembles, A/B testing, custom pre/post processors).
- Enterprise features: explainability, drift/outlier detection, monitoring.
3. TorchServe
- Official model server for PyTorch (by AWS & Meta).
- REST/gRPC APIs, batch inference, model versioning, multi-model serving, metrics.
4. FastAPI
- High-performance Python web framework.
- Not “model server” out of the box but very popular for serving ML models as REST APIs.
- Async, automatic docs, great developer experience.
5. Knative
- Kubernetes-based serverless platform for running containerized apps (including ML models).
- Autoscale to zero, event-driven, traffic splitting. Often used as a backend for KServe or custom FastAPI model servers.
6. TensorFlow Serving
- Official serving system for TensorFlow models.
- Production-grade, optimized for TF, supports versioning, REST/gRPC.
7. BentoML
- Flexible, easy-to-use framework for model packaging and serving (supports any Python ML framework).
- One-command deploy to REST/gRPC API, great for both local and cloud.
- Integrates with Docker, Lambda, K8s, and cloud providers.
8. Triton Inference Server (NVIDIA)
- High-performance, multi-framework server for deep learning and ML models.
- Supports TensorFlow, PyTorch, ONNX, TensorRT, and more.
- GPU acceleration, concurrent model execution, dynamic batching.
9. MLflow Models
- Simple model serving using MLflow’s model registry; supports multiple flavors (Python, R, Java, H2O, PyTorch, etc.).
- REST API out of the box, but limited to single-model-per-process.
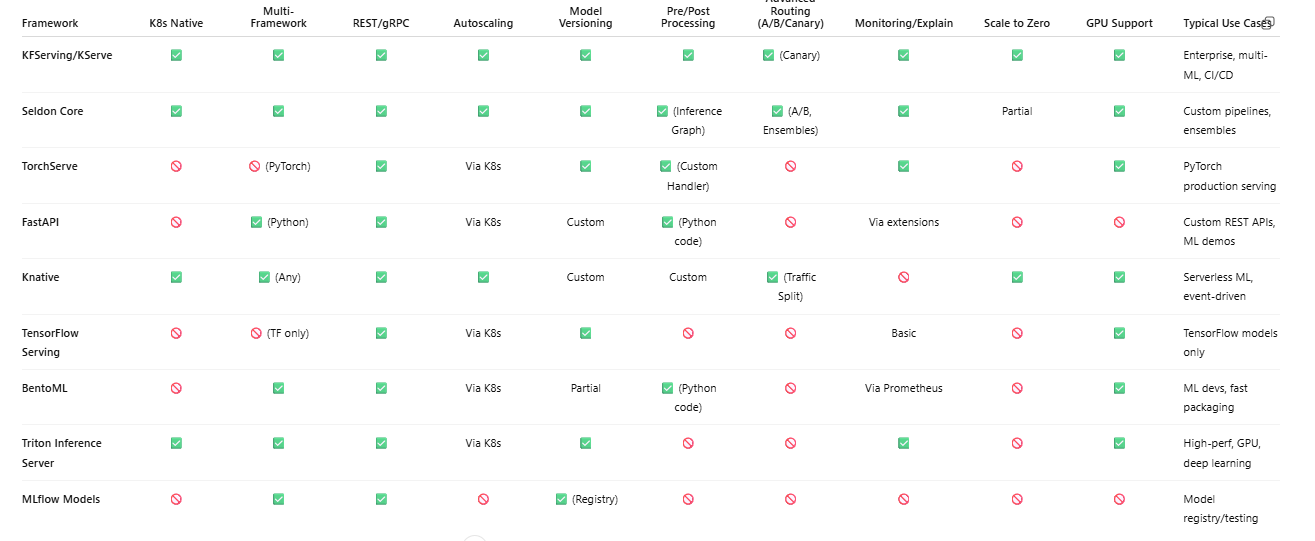
Comparison Table: Model Serving Frameworks
| Framework | K8s Native | Multi-Framework | REST/gRPC | Autoscaling | Model Versioning | Pre/Post Processing | Advanced Routing (A/B/Canary) | Monitoring/Explain | Scale to Zero | GPU Support | Typical Use Cases |
|---|---|---|---|---|---|---|---|---|---|---|---|
| KFServing/KServe | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ (Canary) | ✅ | ✅ | ✅ | Enterprise, multi-ML, CI/CD |
| Seldon Core | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ (Inference Graph) | ✅ (A/B, Ensembles) | ✅ | Partial | ✅ | Custom pipelines, ensembles |
| TorchServe | 🚫 | 🚫 (PyTorch) | ✅ | Via K8s | ✅ | ✅ (Custom Handler) | 🚫 | ✅ | 🚫 | ✅ | PyTorch production serving |
| FastAPI | 🚫 | ✅ (Python) | ✅ | Via K8s | Custom | ✅ (Python code) | 🚫 | Via extensions | 🚫 | 🚫 | Custom REST APIs, ML demos |
| Knative | ✅ | ✅ (Any) | ✅ | ✅ | Custom | Custom | ✅ (Traffic Split) | 🚫 | ✅ | ✅ | Serverless ML, event-driven |
| TensorFlow Serving | 🚫 | 🚫 (TF only) | ✅ | Via K8s | ✅ | 🚫 | 🚫 | Basic | 🚫 | ✅ | TensorFlow models only |
| BentoML | 🚫 | ✅ | ✅ | Via K8s | Partial | ✅ (Python code) | 🚫 | Via Prometheus | 🚫 | ✅ | ML devs, fast packaging |
| Triton Inference Server | ✅ | ✅ | ✅ | Via K8s | ✅ | 🚫 | 🚫 | ✅ | 🚫 | ✅ | High-perf, GPU, deep learning |
| MLflow Models | 🚫 | ✅ | ✅ | 🚫 | ✅ (Registry) | 🚫 | 🚫 | 🚫 | 🚫 | 🚫 | Model registry/testing |
Legend:
✅ = Native/built-in | 🚫 = Not native or not included | Partial = Possible but not full feature
Framework Recommendations by Use Case
- All-purpose, production-ready on Kubernetes:
KServe/KFServing, Seldon Core, Triton Inference Server - PyTorch-only production serving:
TorchServe - Lightweight, developer-friendly Python APIs:
FastAPI, BentoML - Serverless, event-driven, scale to zero:
Knative (often with KServe or FastAPI) - TensorFlow-only, high-performance:
TensorFlow Serving - Easy packaging and deploy for any ML framework:
BentoML - GPU-heavy, deep learning inference at scale:
Triton Inference Server - Simple model serving for quick testing:
MLflow Models
I’m a DevOps/SRE/DevSecOps/Cloud Expert passionate about sharing knowledge and experiences. I have worked at Cotocus. I share tech blog at DevOps School, travel stories at Holiday Landmark, stock market tips at Stocks Mantra, health and fitness guidance at My Medic Plus, product reviews at TrueReviewNow , and SEO strategies at Wizbrand.
Do you want to learn Quantum Computing?
Please find my social handles as below;
Rajesh Kumar Personal Website
Rajesh Kumar at YOUTUBE
Rajesh Kumar at INSTAGRAM
Rajesh Kumar at X
Rajesh Kumar at FACEBOOK
Rajesh Kumar at LINKEDIN
Rajesh Kumar at WIZBRAND
Find Trusted Cardiac Hospitals
Compare heart hospitals by city and services — all in one place.
Explore Hospitals