📌 The Complete End-to-End Big Data Workflow – Ultimate Tool List
Below is a comprehensive list of tools for building a full big data architecture covering every stage, ensuring nothing is missed.
📌 Step 1: Data Ingestion (Real-time & Batch)
| Category | Tool | Description |
|---|---|---|
| Message Queue / Event Streaming | Apache Kafka | High-throughput distributed message broker for real-time streaming. |
| Apache Pulsar | Alternative to Kafka, multi-tier pub-sub messaging. | |
| ETL (Extract, Transform, Load) | Apache NiFi | Automates the flow of data between systems. |
| Airbyte | Open-source data integration tool for moving data from APIs & databases. | |
| Fivetran | Cloud-based ETL service for automated data pipelines. | |
| Talend | Enterprise ETL tool with data integration capabilities. | |
| Apache Flume | Collects and transfers log data to HDFS, Kafka. | |
| Change Data Capture (CDC) | Debezium | Captures changes in databases for streaming data pipelines. |
| Maxwell | Streams MySQL binlog events to Kafka or other destinations. |
✅ Best Choice: Kafka for streaming, NiFi/Airbyte for ETL, and Debezium for database changes.
📌 Step 2: Data Storage (Data Lake & Warehouses)
| Category | Tool | Description |
|---|---|---|
| Distributed File System (HDFS Alternative) | Apache HDFS | Hadoop’s distributed file storage. |
| Ceph | Cloud-native distributed object storage. | |
| MinIO | Open-source alternative to AWS S3 for object storage. | |
| Cloud Storage | AWS S3 | Scalable cloud object storage. |
| Google Cloud Storage (GCS) | Object storage for big data workloads. | |
| NoSQL Databases | Apache Cassandra | Distributed NoSQL database for high availability. |
| MongoDB | Document-oriented NoSQL database. | |
| Columnar Databases | Apache HBase | Column-family NoSQL storage (like Google’s Bigtable). |
| Google BigTable | Managed columnar database for real-time workloads. | |
| Data Warehouses | Amazon Redshift | Cloud data warehouse for structured data analytics. |
| Google BigQuery | Serverless cloud data warehouse for massive-scale querying. | |
| Snowflake | Cloud-native data warehouse with separation of compute & storage. |
✅ Best Choice: HDFS/S3 for raw storage, Cassandra for real-time, and BigQuery/Snowflake for analytics.
📌 Step 3: Data Processing & Compute
| Category | Tool | Description |
|---|---|---|
| Batch Processing | Apache Spark | In-memory processing for big data (batch & real-time). |
| Apache Hadoop (MapReduce) | Disk-based batch processing, slower than Spark. | |
| Real-time Processing | Apache Flink | Low-latency stream processing. |
| Apache Storm | Older real-time processing engine. | |
| Kafka Streams | Lightweight stream processing for Kafka. | |
| SQL Query Engines | Apache Hive | SQL-like queries on Hadoop. |
| Apache Drill | Schema-free SQL engine for JSON, Parquet, ORC files. | |
| Trino (Presto) | Distributed SQL engine for querying large datasets. |
✅ Best Choice: Spark for batch, Flink for streaming, Trino for SQL-based analytics.
📌 Step 4: Data Querying & Interactive Analysis
| Category | Tool | Description |
|---|---|---|
| Interactive SQL Querying | Apache Superset | Open-source BI tool for visualizing and querying big data. |
| Metabase | Simple, user-friendly BI and analytics tool. | |
| Google Data Studio | Cloud-based BI tool for Google ecosystem. | |
| OLAP & Analytics | Apache Druid | Fast OLAP engine for sub-second analytics. |
| ClickHouse | Open-source columnar database for real-time analytics. |
✅ Best Choice: Superset for visualization, Druid for real-time analytics.
📌 Step 5: Data Monitoring & Observability
| Category | Tool | Description |
|---|---|---|
| Monitoring & Metrics | Prometheus | Time-series monitoring for infrastructure and services. |
| Grafana | Dashboarding and visualization for Prometheus/Kafka/Spark metrics. | |
| Logging & Search Analytics | Elasticsearch | Search and analyze log data. |
| Logstash | Log pipeline processing (ELK stack). | |
| Fluentd | Alternative to Logstash, lightweight log collector. | |
| Graylog | Centralized log management and analysis. |
✅ Best Choice: Prometheus for monitoring, Elasticsearch for logs.
📌 Step 6: Machine Learning & AI
| Category | Tool | Description |
|---|---|---|
| ML for Big Data | MLlib (Spark ML) | Machine learning library for Spark. |
| TensorFlow on Spark | Deep learning with Spark integration. | |
| MLOps & Model Deployment | Kubeflow | Kubernetes-based ML model deployment. |
| MLflow | Model tracking and deployment framework. |
✅ Best Choice: Spark ML for big data ML, MLflow for model tracking.
📌 Step 7: Workflow Orchestration & Job Scheduling
| Category | Tool | Description |
|---|---|---|
| Workflow Scheduling | Apache Airflow | Best tool for scheduling ETL pipelines. |
| Apache Oozie | Hadoop workflow scheduler. | |
| Dagster | Modern data orchestration alternative to Airflow. |
✅ Best Choice: Airflow for general workflows, Dagster for modern data ops.
🔥 Final Big Data Workflow (Best Tech Stack)
| Stage | Best Tools |
|---|---|
| Data Ingestion | Kafka, NiFi, Airbyte, Debezium |
| Data Storage | HDFS, S3, Cassandra, BigQuery, Snowflake |
| Data Processing | Spark (batch), Flink (real-time), Trino (SQL) |
| Data Querying | Presto, Hive, Druid |
| Data Visualization | Superset, Grafana |
| Data Monitoring | Prometheus, Elasticsearch |
| Machine Learning | MLlib, TensorFlow on Spark, MLflow |
| Orchestration | Airflow, Dagster |
🚀 Final Thoughts
- 🔹 If you’re streaming real-time data, use Kafka + Flink + Druid/Superset.
- 🔹 If you need batch analytics, use Spark + Hadoop + Trino.
- 🔹 If you want a modern cloud solution, use BigQuery + Airbyte + Superset.
- 🔹 If you’re running ML on big data, use Spark ML + MLflow.
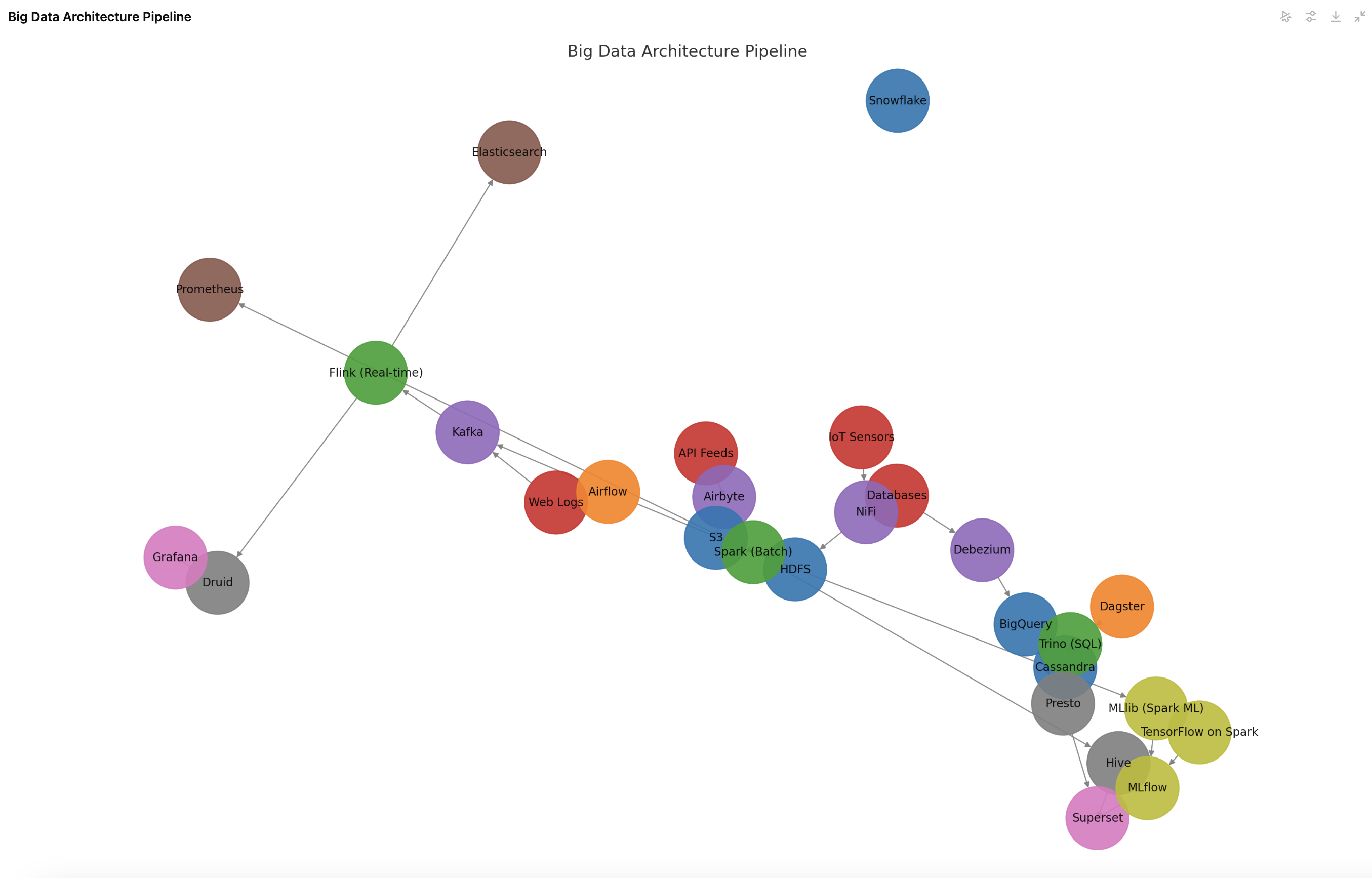
Here is the detailed architecture diagram of the Big Data Pipeline. It visually represents the data flow across ingestion, storage, processing, querying, visualization, monitoring, machine learning, and orchestration stages.
📌 How to Read the Diagram
- Data Sources: Incoming data from Web Logs, Databases, IoT Sensors, API Feeds.
- Data Ingestion: Kafka (real-time), NiFi, Airbyte, and Debezium (ETL and CDC tools) collect the data.
- Data Storage: HDFS, S3, Cassandra, BigQuery, and Snowflake store raw data.
- Data Processing:
- Spark processes batch data.
- Flink processes real-time data streams.
- Trino enables SQL-based querying on structured data.
- Data Querying & Analysis: Presto, Hive, and Druid allow complex queries.
- Data Visualization: Superset & Grafana for dashboarding and insights.
- Monitoring & Logging: Prometheus tracks system metrics, Elasticsearch logs real-time events.
- Machine Learning:
- Spark MLlib & TensorFlow on Spark for large-scale ML.
- MLflow tracks models and outputs to dashboards.
- Orchestration: Airflow and Dagster automate workflows.
This end-to-end pipeline ensures smooth handling of real-time and batch data with advanced analytics, visualization, and machine learning. 🚀
I’m a DevOps/SRE/DevSecOps/Cloud Expert passionate about sharing knowledge and experiences. I have worked at Cotocus. I share tech blog at DevOps School, travel stories at Holiday Landmark, stock market tips at Stocks Mantra, health and fitness guidance at My Medic Plus, product reviews at TrueReviewNow , and SEO strategies at Wizbrand.
Do you want to learn Quantum Computing?
Please find my social handles as below;
Rajesh Kumar Personal Website
Rajesh Kumar at YOUTUBE
Rajesh Kumar at INSTAGRAM
Rajesh Kumar at X
Rajesh Kumar at FACEBOOK
Rajesh Kumar at LINKEDIN
Rajesh Kumar at WIZBRAND
Find Trusted Cardiac Hospitals
Compare heart hospitals by city and services — all in one place.
Explore Hospitals