Microservice oriented architecture provides ideal platform for continuous delivery and offers increased resilience. They foster faster innovation to adapt to changing market conditions, increase developer productivity and improved scalability in real time. Each microservice is implemented as an atomic and self sufficient piece of software and implementing a microservice architecture will often require to make multiple calls to many such single responsibility and independent pieces.
Though we can have synchronous request/response calls when the requester expects immediate response, integration patterns based on events and asynchronous messaging provide maximum scalability and resiliency. In order to build scalable architectures, we need event-driven and asynchronous integration between microservices.
There are a lot of options for asynchronous integration. Some of the widely used ones are:
Kafka
RabbitMQ
Google Pub/Sub
Amazon Services
ActiveMQ
Azure Services
Communication Types
Message Queuing
In this system, messages are persisted in a queue. One or more consumers can consume the messages in the queue, but a particular message can be consumed by a maximum of one consumer only. Once a consumer reads a message in the queue, it disappears from that queue. If there are no consumers available at the time the message is sent, it will be kept until a consumer is available that can process the message.
Publish subscribe
In the publish-subscribe system, messages are persisted in a topic. Consumers can subscribe to one or more topics and consume all the messages in that topic. In the Publish-Subscribe system, message producers are called publishers and message consumers are called subscribers.
Implementations
Kafka:
Kafka is the most popular open source distributed publish-subscribe streaming platform that can handle millions of messages per minute. The key capabilities of Kafka are:
- Publish and subscribe to streams of records
- Store streams of records in a fault-tolerant way
- Process streams of records as they occur
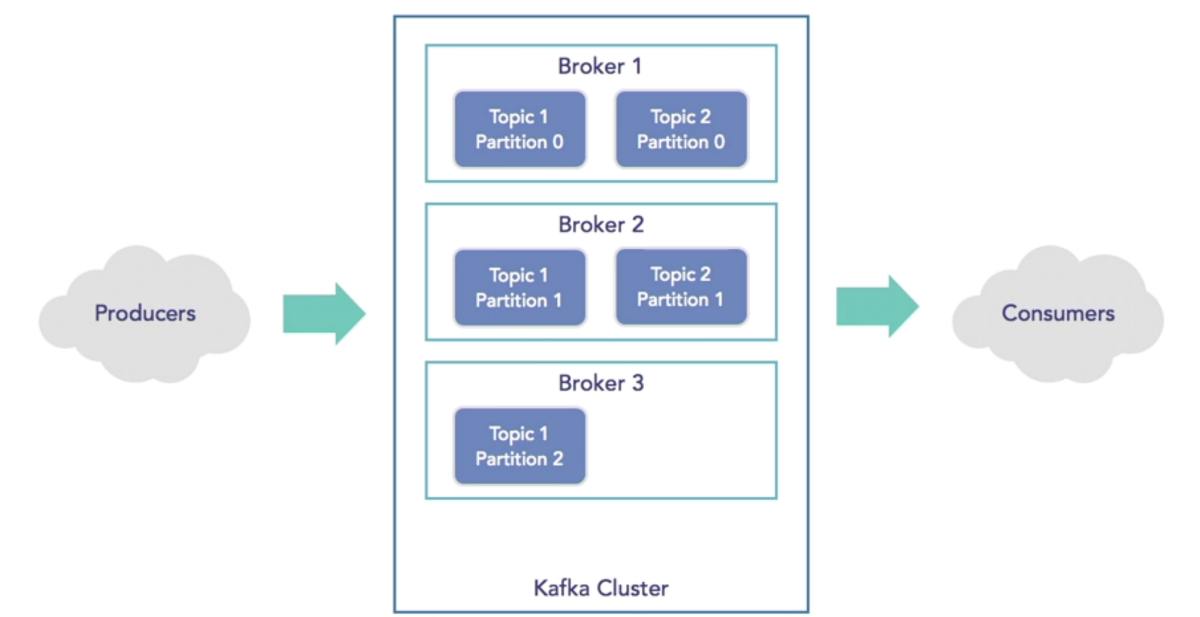
The Key Components of Kafka architecture are: Topics, Partitions, Brokers, Producer, Consumer, Zookeeper.
Core APIs in Kafka include:
- Producer API allows an application to publish a stream of records to one or more Kafka topics.
- Consumer API allows an application to subscribe to one or more topics and process the stream of records produced to them.
- Streams API allows applications to act as a stream processor, consuming an input stream from one or more topics and producing an output stream to one or more output topics, effectively transforming the input streams to output streams. It has a very low barrier to entry, easy operationalization, and a high-level DSL for writing stream processing applications. As such it is the most convenient yet scalable option to process and analyze data that is backed by Kafka.
- Connect API is a component that you can use to stream data between Kafka and other data systems in a scalable and reliable way. It makes it simple to configure connectors to move data into and out of Kafka. Kafka Connect can ingest entire databases or collect metrics from all your application servers into Kafka topics, making the data available for stream processing. Connectors can also deliver data from Kafka topics into secondary indexes like Elasticsearch or into batch systems such as Hadoop for offline analysis.
Kafka is written in Scala and Java. It was originally developed by LinkedIn and donated to the Apache Foundation.
Kafka as a Messaging System:
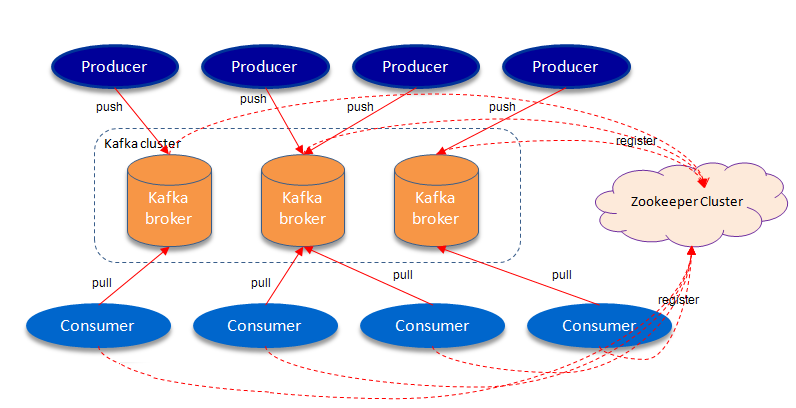
Kafka is a distributed, replicated commit log. Kafka does not have the concept of a queue which might seem strange at first, given that it is primary used as a messaging system. Queues have been synonymous with messaging systems for a long time. Let’s break down “distributed, replicated commit log” a bit:
- Distributed because Kafka is deployed as a cluster of nodes, for both fault tolerance and scale
- Replicated because messages are usually replicated across multiple nodes (servers).
- Commit Log because messages are stored in partitioned, append only logs which are called Topics. This concept of a log is the principal killer feature of Kafka.
Kafka uses a pull model. Consumers request batches of messages from a specific offset. Kafka permits long-pooling, which prevents tight loops when there is no message past the offset. A pull model is logical for Kafka because of its partitions. Kafka provides message order in a partition with no contending consumers. This allows users to leverage the batching of messages for effective message delivery and higher throughput.
It is a dumb broker / smart consumer model — does not try to track which messages are read by consumers. Kafka keeps all messages for a set period of time.
RabbitMQ:
The core idea in the messaging model in RabbitMQ is that the producer never sends any messages directly to a queue. Actually, quite often the producer doesn’t even know if a message will be delivered to any queue at all.
Instead, the producer can only send messages to an exchange. An exchange is a very simple thing. On one side it receives messages from producers and the other side it pushes them to queues. The exchange must know exactly what to do with a message it receives. Should it be appended to a particular queue? Should it be appended to many queues? Or should it get discarded. The rules for that are defined by the exchange type (direct, topic, headers and fanout)
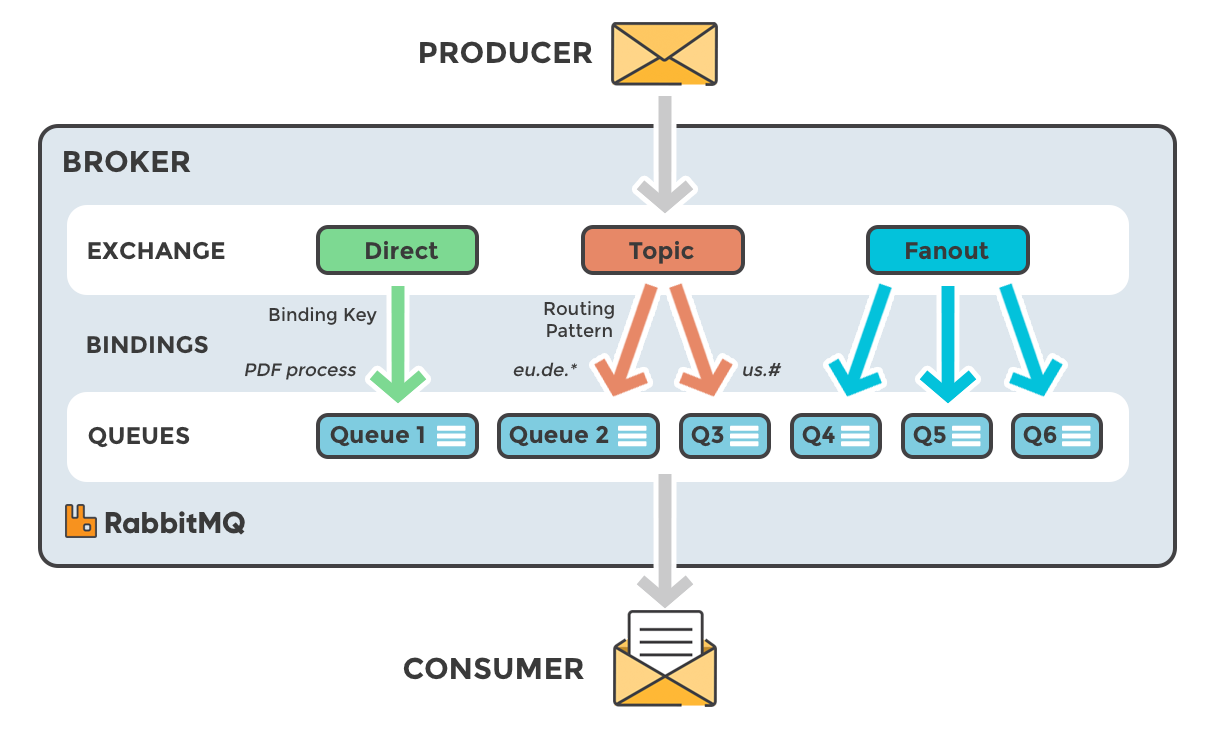
The super simplified overview:
- Publishers send messages to exchanges
- Exchanges route messages to queues and other exchanges
- RabbitMQ sends acknowledgements to publishers on message receipt
- Consumers maintain persistent TCP connections with RabbitMQ and declare which queue(s) they consume
- RabbitMQ pushes messages to consumers
- Consumers send acknowledgements of success/failure
- Messages are removed from queues once consumed successfully
It is a smart broker / dumb consumer model — consistent delivery of messages to consumers, at around the same speed as the broker monitors the consumer state.
RabbitMQ uses a push model. Push-based systems can overwhelm consumers if messages arrive at the queue faster than the consumers can process them. So to avoid this each consumer can configure a prefetch limit (also known as a QoS limit). This basically is the number of unacknowledged messages that a consumer can have at any one time. This acts as a safety cut-off switch for when the consumer starts to fall behind.This can be used for low latency messaging.
The aim of the push model is to distribute messages individually and quickly, to ensure that work is parallelized evenly and that messages are processed approximately in the order in which they arrived in the queue.
RabbitMQ is written in Erlang. Pivotal develops and maintains RabbitMQ.
Read also:
The Challenges of Running Microservices in Production.
Find Trusted Cardiac Hospitals
Compare heart hospitals by city and services — all in one place.
Explore Hospitals