| # | Contents |
|---|---|
| 1. | What is Secondary Index in Teradata? |
| 2. | When we can Define Secondary Index? |
| 3. | Types of Secondary Index |
| 4. | Unique Secondary Index (USI) |
| 5. | Non Unique Secondary Index (NUSI) |
| 6. | Value-Ordered NUSI |
| 7. | Advantage and Disadvantage of Secondary Index |
| 8. | Primary Index vs. Secondary Index |
| 9. | Additional Topic |
To Understand More About Secondary Index in Teradata we have to go through below points:
There are 3 general ways to access a table:
- Primary Index access (one AMP access)
- Secondary Index access (two or all AMP access)
- Full Table Scan (all AMP access)
What is Secondary Index in Teradata?
A secondary index provides an alternate pathto the rows of a table.
A secondary index can be used to maintain uniquenesswithin a column or set of columns.
A table can have from 0 to 32 secondary indexes.
Secondary Indexes:
- Do not affect table distribution.
- Add overhead, both in terms of disk space and maintenance.
- May be added or dropped dynamically as needed.
- Are chosen to improve table performance.
When we can Define Secondary Index?
A Secondary Index may be defined:
- At table creation (CREATE TABLE)
- Also can define after table creation Using (CREATE INDEX)
- may be up to 64 columns
Types of Secondary Index
There are two types of secondary index:
- Unique Secondary Index (USI)
- Non Unique Secondary Index (NUSI)
Unique Secondary Index (USI)
- If the index choice of column(s) is unique, it is called a USI.
- Unique Secondary Index Accessing a row via a USI is a 2AMP operation.
Syntax to create USI:
CREATE UNIQUE INDEX (EmpNumber) ON Employee;
Non Unique Secondary Index (NUSI)
- If the index choice of column(s) is non-unique, it is called a NUSI.
- Non-Unique Secondary Index Accessing row(s) via a NUSI is an all AMP operation
Syntax to create USI:
CREATE INDEX (LastName) ON Employee;
Unique Secondary Index (USI)
A Subtable is created on each AMP anytime a secondary index is created. A secondary index requires a separate physical structure (the subtable ).
What is in a Unique Secondary Index (USI) Subtable?
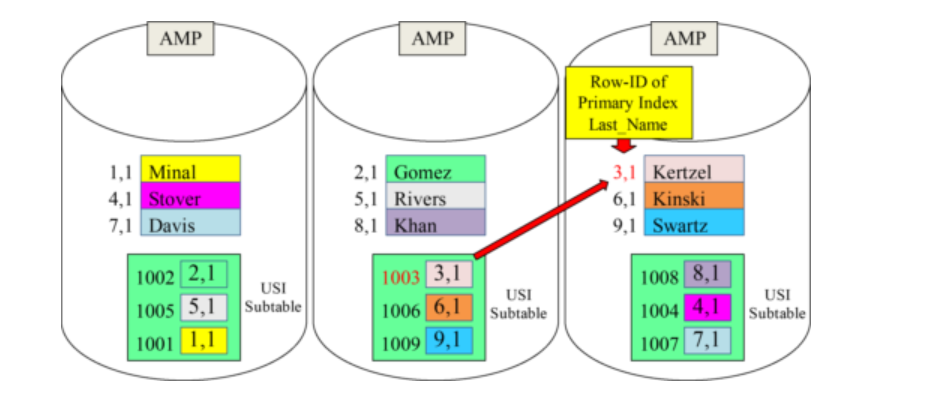
The USI Subtable contains two columns:
1. Emp_No (The USI column)
2. Row-ID of the real Primary Index of the base table
Inside the secondary index subtable is the column Emp_No (USI Column). Then, there is the corresponding Row-ID of the real Primary Index of the table. The USI subtable’s Primary Index is Emp_No, and it is hashed and has a Row-ID like a normal table.
A Unique Secondary Index (USI) Subtable is hashed:
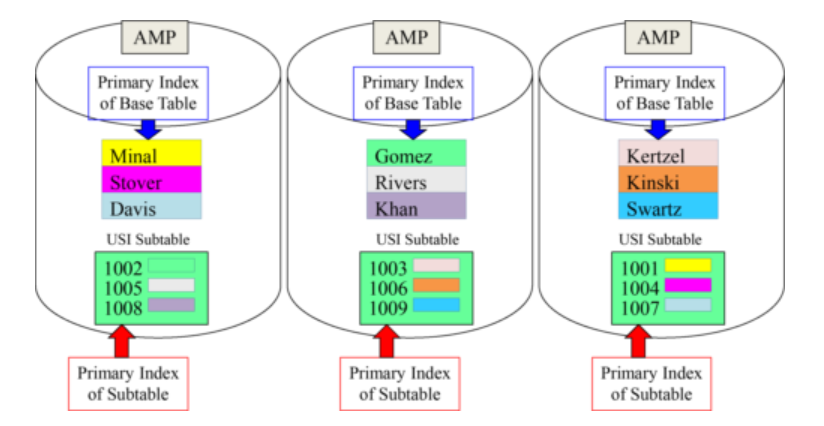
- The USI Subtable spreads the rows evenly among the AMPs. The Primary Index of the Subtable is Emp_No (The USI column).
- Subtable rows are hashed by their Primary Index (Emp_No) and distributed evenly. They contain the Row-ID of the base row, thus providing a pointer to the AMP and row.
How the Parsing Engine uses the USI Subtable:
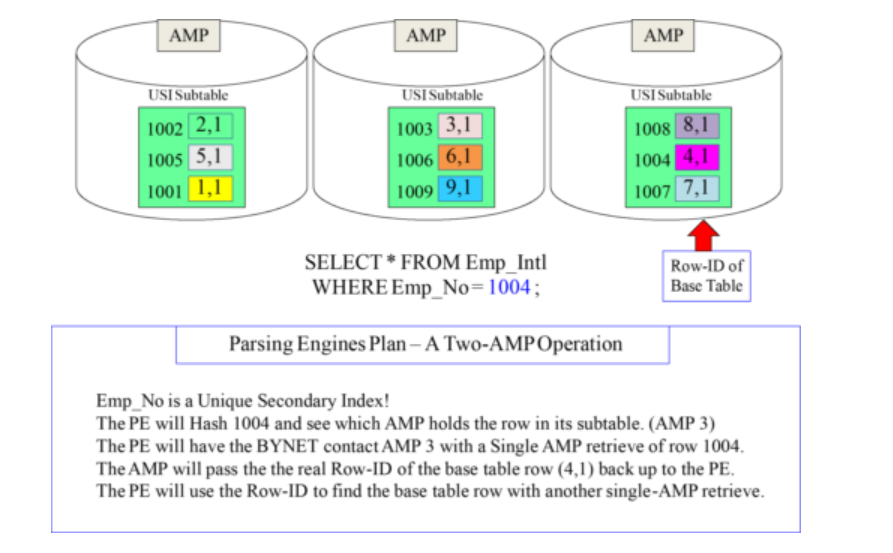
- A USI is a Two-AMP Operation.
- The first AMP is assigned to read the subtable and the second the base table.
- Two binary searches are performed in total, and one row is returned.
Non Unique Secondary Index (NUSI)
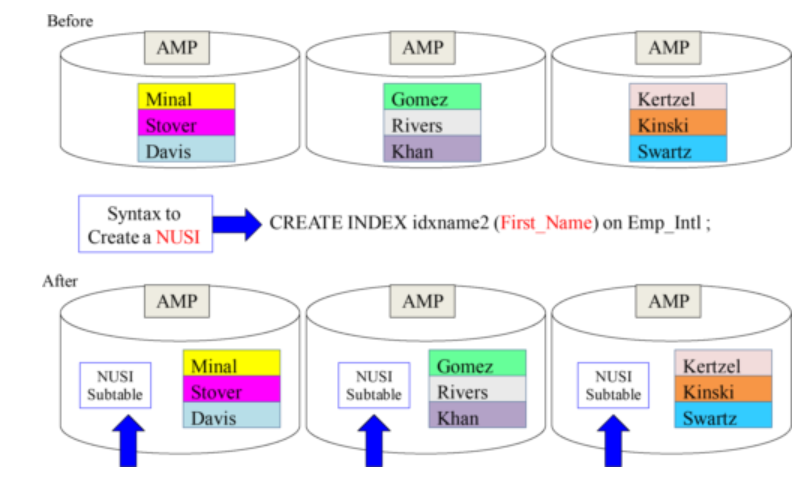
A Subtable is created on each AMP.
What is in a Unique Secondary Index (USI) Subtable?
The NUSI Subtable only contains two columns:
- First_Name (The NUSI column)
- Row-ID of the real Primary Index of the base table
The NUSI rows get their own Row-ID, but they are not hashed to different AMPs and stay AMP local. That is why NUSI know as AMP locally.
Non- Unique Secondary Index (NUSI) Subtable is AMP Local
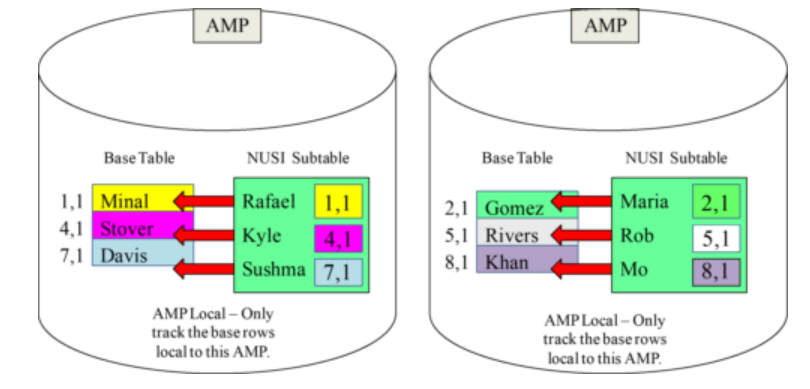
The NUSI Subtable is AMP local because all values in the subtable are of those in the base table (on the same AMP).
How the Parsing Engine uses the NUSI Subtable:
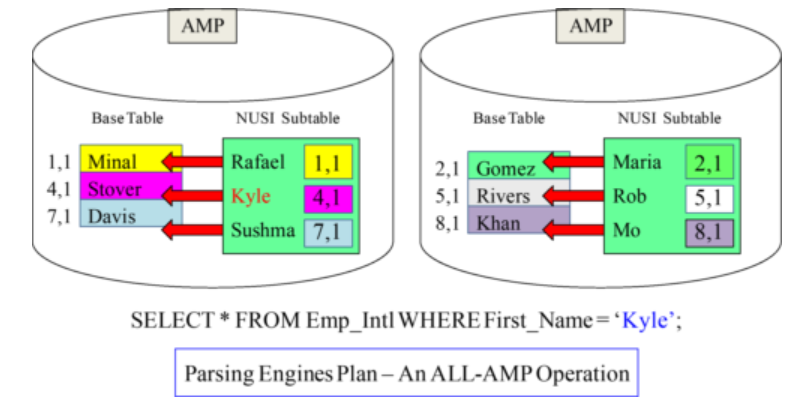
- First_Name is a Non-Unique Secondary Index!
- The Parsing Engine will order each AMP to check if they have a ‘Kyle’ in their NUSI Subtable.
- Each AMP will simultaneously perform a binary search on their NUSI subtable.
- If an AMP has a ‘Kyle’ the PE will order them to retrieve the base row (AMP Local).
- If there are 50 AMPs then all 50 AMPs perform a binary search simultaneously and if they find a “Kyle” they perform another binary search on their local base table.
Note: A NUSI query always searches all AMPs, but the intent is not to do a Full Table Scan. If there are 50 AMPs, then a minimum of 50 binary searches are done.
Drop Secondary Index:
- Dropping named secondary indexes
DROP INDEX indexname ON tutorial_db.employee;
- Dropping unnamed secondary indexes
DROP INDEX(co) ON tutorial_db.employee;
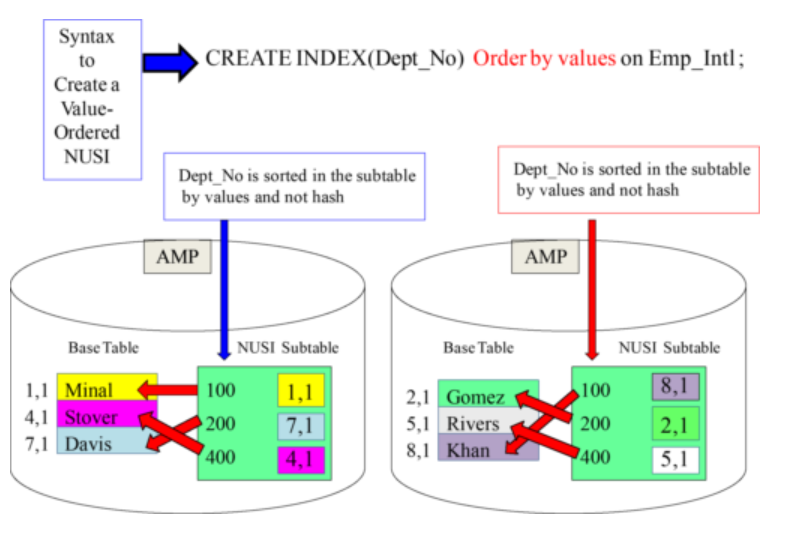
Value-Ordered NUSI
It is called a Value Ordered NUSI because subtable is sorted numerically based on actual column value instead being sorted by Secondary Index Value hash.Works best for the range queries.Can be defined only on ‘numeric’ & ‘date’ data types.
Creating a Value-Ordered NUSI
Advantage and Disadvantage of Secondary Index
Advantage
- A table can have up to 32 secondary indexes (including join/hash indexes).
- Maximum of 64 columns can be added in a single secondary index for a table.
- Does not affect data distribution for table and can be added or dropped as needed.
- Improves table access performance by providing alternative path.
Disadvantage
- Secondary index on multiple columns is less usable.Index would be used only when all columns are used in the WHERE clause.
- Adds overhead, both in terms of disk space and maintenance.
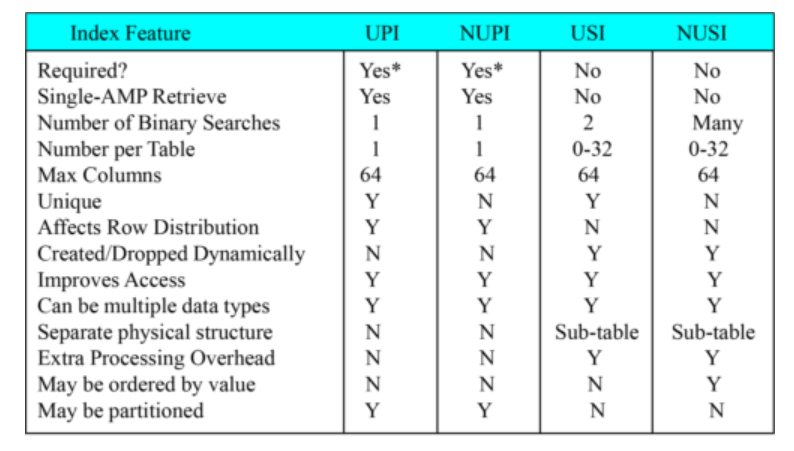
Primary Index vs. Secondary Index
Additional Topic
Full Table Scans
A full table scan is another way to access data without using any Primary or Secondary Indexes.
Every row of the table must be read.
Full table scans typically occur when either:
- An index is not used in the query
- An index is used in a non-equality
MotoShare.in is your go-to platform for adventure and exploration. Rent premium bikes for epic journeys or simple scooters for your daily errands—all with the MotoShare.in advantage of affordability and ease.
Find Trusted Cardiac Hospitals
Compare heart hospitals by city and services — all in one place.
Explore Hospitals



