What is serverless?
Serverless is a type of cloud computing in which the cloud provider is responsible for managing and allocating the servers for running an application, rather than the user. This allows for more efficient use of resources and can lead to cost savings for the user.
With serverless computing, the user only pays for the specific resources and compute time that are used, rather than paying for a fixed amount of server capacity. This can make it more cost-effective for applications that have variable or unpredictable usage patterns.
It is commonly associated with event-driven computing and Function-as-a-Service (FaaS) where the cloud provider dynamically manages the allocation of resources and scaling of the application based on incoming requests. This allows developers to focus on writing and deploying code without worrying about the underlying infrastructure.
AWS Lambda, Azure Functions, and Google Cloud Functions are examples of serverless computing platforms offered by major cloud providers.
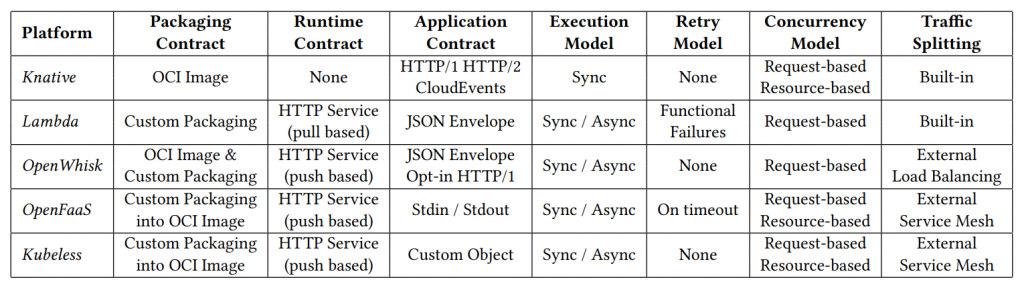
Kubeless
WARNING: Kubeless is no longer actively maintained by VMware.
kubeless is a Kubernetes-native serverless framework that lets you deploy small bits of code without having to worry about the underlying infrastructure plumbing. It leverages Kubernetes resources to provide auto-scaling, API routing, monitoring, troubleshooting and more.
Kubeless stands out as we use a Custom Resource Definition to be able to create functions as custom kubernetes resources. We then run an in-cluster controller that watches these custom resources and launches runtimes on-demand. The controller dynamically injects the functions code into the runtimes and make them available over HTTP or via a PubSub mechanism.
Kubeless is purely open-source and non-affiliated to any commercial organization. Chime in at anytime, we would love the help and feedback !
Knative
Knative is an open-source platform for building, deploying, and running serverless applications on Kubernetes. It extends Kubernetes with additional APIs and components to make it easier to build, deploy, and manage serverless workloads. Knative provides a set of building blocks for creating event-driven, scale-to-zero applications that can automatically scale up and down based on incoming traffic. It also provides a unified way to build, deploy, and manage both container-based and serverless applications, allowing developers to use their existing skills and tools.
Knative consists of several components including:
Serving: A set of Kubernetes custom resources and controllers for building and deploying serverless applications.
Eventing: A set of Kubernetes custom resources and controllers for building event-driven applications, including support for event sources and event sinks.
Build: A set of Kubernetes custom resources and controllers for building container images using popular open-source build tools like Kaniko and buildpacks.
Knative is designed to be cloud-agnostic and can be deployed on a variety of Kubernetes platforms, including on-premises, multi-cloud, and edge clusters. It is built by Google and was donated to the Cloud Native Computing Foundation (CNCF) under the Apache 2.0 license.
Fission
Fission is a framework for serverless functions on Kubernetes.
Write short-lived functions in any language, and map them to HTTP requests (or other event triggers).
Deploy functions instantly with one command. There are no containers to build, and no Docker registries to manage.
OpenFaas
OpenFaaS® makes it easy for developers to deploy event-driven functions and microservices to Kubernetes without repetitive, boiler-plate coding. Package your code or an existing binary in an OCI-compatible image to get a highly scalable endpoint with auto-scaling and metrics.
Highlights
- Ease of use through UI portal and one-click install
- Write services and functions in any language with Template Store or a Dockerfile
- Build and ship your code in an OCI-compatible/Docker image
- Portable: runs on existing hardware or public/private cloud by leveraging Kubernetes
- CLI available with YAML format for templating and defining functions
- Auto-scales as demand increases including to zero
- Commercially supported Pro distribution by the team behind OpenFaaS
OpenWhisk
Apache OpenWhisk is an open source, distributed Serverless platform that executes functions (fx) in response to events at any scale. OpenWhisk manages the infrastructure, servers and scaling using Docker containers so you can focus on building amazing and efficient applications.
The OpenWhisk platform supports a programming model in which developers write functional logic (called Actions), in any supported programming language, that can be dynamically scheduled and run in response to associated events (via Triggers) from external sources (Feeds) or from HTTP requests. The project includes a REST API-based Command Line Interface (CLI) along with other tooling to support packaging, catalog services and many popular container deployment options.
Fn Project
Fn is an open-source, container-native, and cloud-agnostic serverless platform. It allows developers to easily build, run, and scale serverless functions using the same container-based approach they use for their other workloads. Fn supports various languages and frameworks, and can run on any infrastructure that can run Docker. It also provides a simple and consistent way to manage, monitor, and troubleshoot serverless functions across different environments.
Direktiv
Direktiv is an event-driven container orchestration engine, running on Kubernetes and Knative. The following key concepts:
- direktiv runs containers as part of workflows from any compliant container registry, passing JSON structured data between workflow states.
- JSON structured data is passed to the containers using HTTP protocol on port 8080.
- direktiv uses a primitive state declaration specification to describe the flow of the orchestration in YAML, or users can build the workflow using the workflow builder UI.
- direktiv uses jq JSON processor to implement sophisticated control flow logic and data manipulation through states.
- Workflows can be event-based triggers (Knative Eventing & CloudEvents), cron scheduling to handle periodic tasks, or can be scripted using the APIs.
- Integrated into Prometheus (metrics), Fluent Bit (logging) & OpenTelemetry (instrumentation & tracing).
Kubeflow
Kubeflow is an open-source platform for machine learning (ML) that runs on Kubernetes. It provides a collection of tools and frameworks for building and deploying ML workflows on Kubernetes clusters, such as TensorFlow, PyTorch, and MXNet. Kubeflow enables data scientists and ML engineers to build scalable, portable, and reproducible ML pipelines on Kubernetes, leveraging the scalability, fault-tolerance, and flexibility of Kubernetes.
Kubeflow provides a range of features to help with ML workflow management, such as:
- Training and Serving: Kubeflow provides an end-to-end pipeline for training and deploying machine learning models using a variety of popular frameworks and tools, such as TensorFlow, PyTorch, and Jupyter.
- Hyperparameter Tuning: Kubeflow includes tools for hyperparameter tuning, such as Katib, which can be used to automate the tuning process and find the best hyperparameters for a given model.
- Model Versioning and Experiment Tracking: Kubeflow includes tools for versioning and tracking ML models and experiments, such as ML Metadata, which can be used to record metadata about model versions, training runs, and experiments.
- Workflow Automation: Kubeflow provides tools for automating ML workflows, such as Argo, which can be used to create complex workflows that include multiple ML tasks, such as data preprocessing, model training, and model evaluation.
- Multi-cloud and On-premises Support: Kubeflow can be deployed on a variety of cloud platforms, such as Google Cloud, AWS, and Microsoft Azure, as well as on-premises Kubernetes clusters.
Kserve
Kserve is an open-source, high-performance serving platform for machine learning models. It is built on top of Kubernetes and is designed to serve machine learning models at scale. Kserve is part of the Kubeflow project and is maintained by the Kubeflow community.
Kserve provides a number of features to help with serving machine learning models, including:
- High Performance: Kserve is designed to be highly performant, with low-latency serving and high throughput, making it suitable for serving models in production environments.
- Scalability: Kserve is built on top of Kubernetes, which provides a scalable infrastructure for serving models. Kserve can automatically scale the number of instances serving a model based on the incoming traffic.
- Multi-Model Serving: Kserve can serve multiple machine learning models simultaneously, allowing users to easily deploy and manage multiple models in production.
- Auto Scaling: Kserve can automatically scale up and down the number of instances serving a model based on the incoming traffic, providing efficient use of resources.
- Model Versioning: Kserve supports model versioning, allowing users to easily switch between different versions of a model when serving it.
- Customizable: Kserve is highly customizable, with the ability to define custom pre-processing and post-processing logic
I’m Rajesh Kumar, a DevOps, SRE, DevSecOps, Cloud, and Platform Engineering expert passionate about sharing practical knowledge, real-world experiences, and industry best practices. I have worked at Cotocus and regularly write about technology, travel, investing, health, product reviews, and digital marketing through my various platforms.
I publish technical articles at DevOps School, travel stories at Holiday Landmark, stock market insights at Stocks Mantra, health and fitness guidance at My Medic Plus, product reviews at TrueReviewNow, and SEO and digital marketing strategies at Wizbrand.
Find Trusted Cardiac Hospitals
Compare heart hospitals by city and services — all in one place.
Explore Hospitals