Understanding Elasticsearch Keywords and Terminology
|
Elasticsearch Terminology |
Description |
|---|---|
|
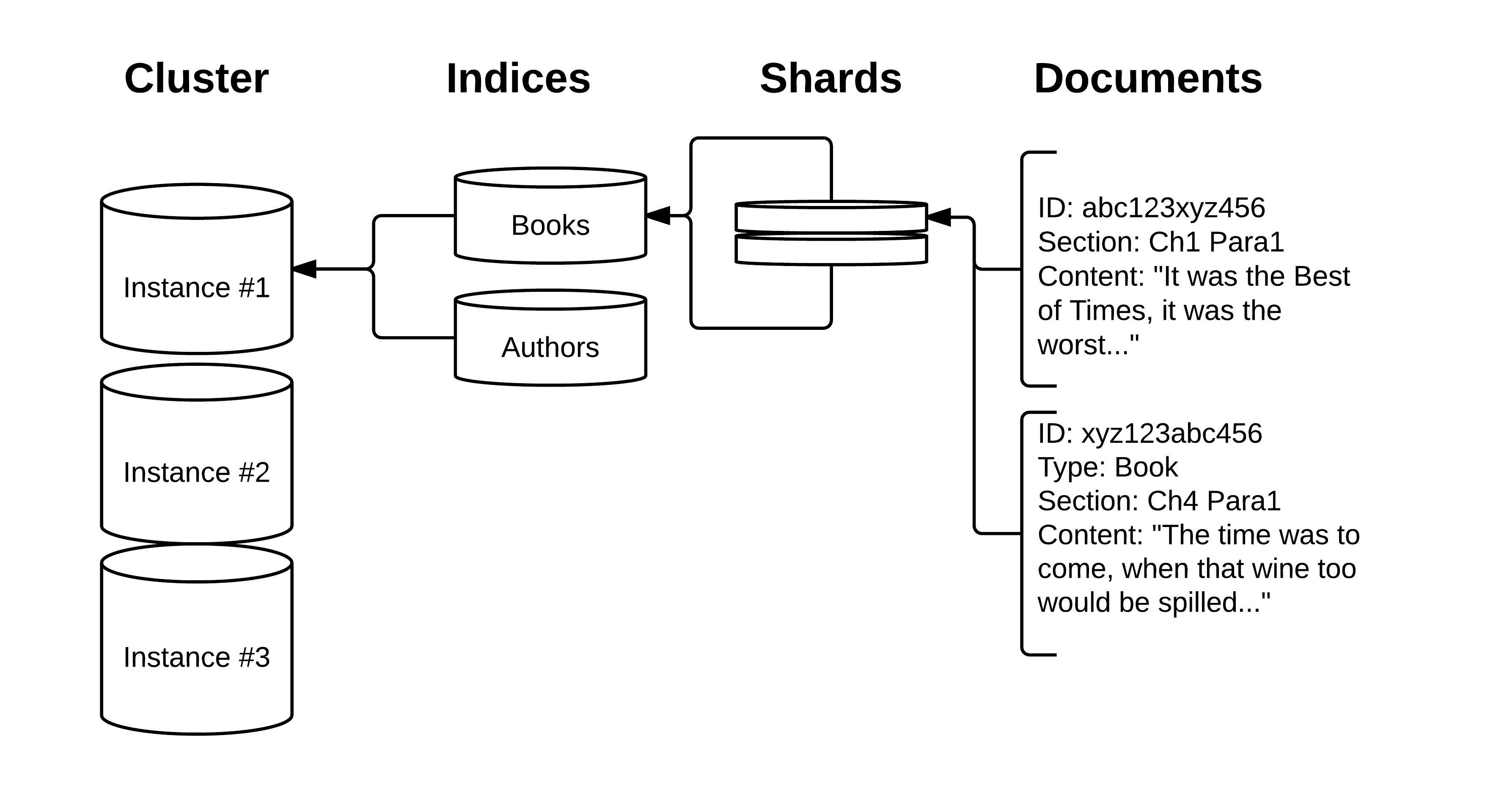
Cluster |
“A cluster is a collection of one or more nodes (servers) that together holds your entire data and provides federated indexing and search capabilities across all nodes. A cluster is identified by a unique name which by default is ‘elasticsearch’. This name is important because a node can only be part of a cluster if the node is set up to join the cluster by its name.” “Make sure that you don’t reuse the same cluster names in different environments, otherwise you might end up with nodes joining the wrong cluster. For instance you could use logging-dev, logging-stage, and logging-prod for the development, staging, and production clusters.” |
|
Node |
“A node is a single server that is part of your cluster, stores your data, and participates in the cluster’s indexing and search capabilities. Just like a cluster, a node is identified by a name. You can define any node name you want if you do not want the default. This name is important for administration purposes where you want to identify which servers in your network correspond to which nodes in your Elasticsearch cluster.” |
|
Index |
“An index is a collection of documents that have somewhat similar characteristics. In a single cluster, you can define as many indexes as you want.” An index is an equivalent of a relational database. |
|
Type |
“Within an index, you can define one or more types. A type is a logical category/partition of your index whose semantics is completely up to you. In general, a type is defined for documents that have a set of common fields.” A type is an equivalent to a database table or view.Because Lucene, which Elasticsearch is built on, has no concept of document types, this is stored within an _type field. What happens internally is that when searching for a specific type of document, Elasticsearch applies a filter on this field. |
|
Alias |
Alias is a reference to an Elasticsearch index. An alias can be mapped to more than one index. |
|
Document |
“A document is a basic unit of information that can be indexed. This document is expressed in JavaScript Object Notation (JSON) format.” A document is a basic unit of information that can be indexed. It consists of fields, which are key/value pairs, where a value can be of various types, such as strings, dates, objects, etc. A document corresponds to an object in an object-oriented programming language, and a document type corresponds to a class. An example of a document could be a single user or product. Documents are expressed as JSON objects, and you can store as many documents within an index as you want. Now that we have walked through a few concepts, let’s complete the analogy to relational databases. Where an index corresponds to a database and a type corresponds to a table, a document can be thought of as being the equivalent of a row in a database table. The fields of a document correspond to columns, and a mapping corresponds to the schema for a table. |
|
Shards and Replicas |
“Elasticsearch provides the ability to subdivide your index into multiple pieces called shards. When you create an index, you can simply define the number of shards that you want. Each shard is in itself a fully-functional and independent ‘index’ that can be hosted on any node in the cluster. Elasticsearch allows you to make one or more copies of your index’s shards into what are called replica shards, or replicas for short. After the index is created, you may change the number of replicas dynamically anytime but you cannot change the number of shards after-the-fact.” |
| Mappings | A document type has a mapping that is similar to the schema of a table in a relational database. It describes the fields that a document of a given type may have along with their data types, such as string, integer, date, etc. Also included is information on how fields should be indexed and how they should be stored by Lucene. It is, however, optional if you wish to specify this.
Thanks to dynamic mapping, it is optional to define a mapping before adding documents to an index. If no mapping is defined, it will be inferred automatically when a document is added, based on its data. |
Reference
- https://www.elastic.co/guide/en/elastic-stack-glossary/current/terms.html
- https://www.elastic.co/guide/en/elasticsearch/reference/current/glossary.html
- https://www.elastic.co/guide/en/elasticsearch/reference/current/_basic_concepts.html
I’m Rajesh Kumar, a DevOps, SRE, DevSecOps, Cloud, and Platform Engineering expert passionate about sharing practical knowledge, real-world experiences, and industry best practices. I have worked at Cotocus and regularly write about technology, travel, investing, health, product reviews, and digital marketing through my various platforms.
I publish technical articles at DevOps School, travel stories at Holiday Landmark, stock market insights at Stocks Mantra, health and fitness guidance at My Medic Plus, product reviews at TrueReviewNow, and SEO and digital marketing strategies at Wizbrand.
Find Trusted Cardiac Hospitals
Compare heart hospitals by city and services — all in one place.
Explore Hospitals