Over the past few decades, several trends have driven the progress of data storage and processing systems. In recent years a huge amount of data has been produced by people for human consumption, and this amount is dwarfed by the amount of data produced by machines. Also the cost of storage has dropped dramatically. Hard drives, commonly used for data storage now store multiple terabytes for roughly the same price as gigabyte drives stored gigabytes of data a decade ago. Computer memory is also dropping in price, making it possible for many applications to run with their working data sets entirely in memory, systems that store most data on disk still have a big cost advantage.
These trends have caused system and application developers to take a hard look at conventional designs and to consider alternatives. The question many are asking is: how should we build applications so we can take advantage of all this data, in light of current hardware trends, and in the most cost-effective way possible?
What is Accumulo?
Accumulo is a high-performance, distributed data store for government applications on Apache Hadoop. It is highly scalable, open source data store modeled after Google’s Bigtable design. Accumulo is built to store mass amount of data elements in organized way so that their users can excess that information of data with ease.
According to DB-Engines ranking, Accumulo is the third most popular NoSQL wide column store behind Apache Cassandra and HBase and the 67th most popular database engine of any type.
History of Accumulo
Accumulo is written in JAVA. In 2008 A team of software engineers at the United States’ National Security Agency (NSA) started building Accumulo as a clone of Google’s BigTable system. In September 2011 Accumulo was released as a public open source on Apache Software Foundation.
Versions
The first public open source version of Accumulo is 1.3. Later version 1.4 has been used in production for years on very large numbers. Currently the latest stable version of Accumulo is 1.6.
Main Features of this Latest Version:-
- Table namespaces
- Conditional mutations
- Locality groups in memory
- Multivolume support (running over multiple HDFS instances)
- Support for ViewFS
- Maven plug-in
- Service IP addresses
- Default key size constraint
- Partial encryption support
Storage Architecture
Accumulo is a disk-oriented database that relies on HDFS to store data.
Data Model
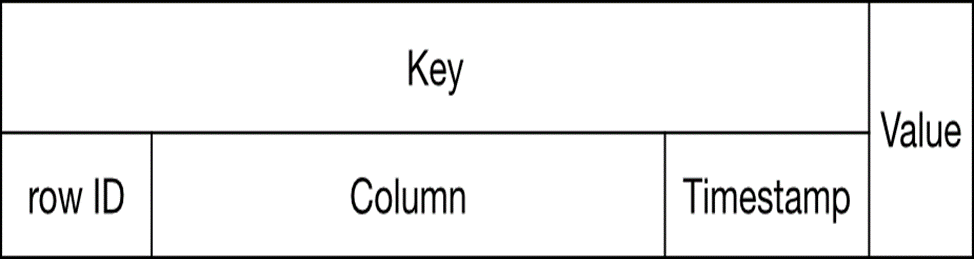
Accumulo stores key-value pairs on disk keeping the keys sorted at all times. The default constraint on the maximum size of the key is 1 MB. It allows user to look up the value of a particular key or range of keys very quickly. Values are stored as byte arrays, and Accumulo doesn’t restrict the type or size of the values stored. Accumulo keys are made up of several components. Inside the key there are three main components: a row ID, a column, and a timestamp.
These row ID and column components allow developers to design their data in a way to store data in a relational database, or may be in a spreadsheet. Also have major difference in process is that relational databases auto generated row IDs and rely on secondary indexes for all data access, whereas the row IDs in Accumulo can contain data that is relevant to an application. Accumulo first sorts the data by row ID, then sorts keys with the same row ID by column, while sorting the keys. Row IDs and columns are sorted in ascending, lexicographical order byte-by-byte.
This implies that values in the same row will be stored together, and that different rows don’t have to contain the same number of columns. Time stamps are used to support multi-versioning of the same key. The column component in the key can be further divided into three fields: column families, column qualifiers and column visibility. Column families are defined by the application designer to group columns with similar functions, so that Accumulo will store them close on disk for faster access. Note that unlike Bigtable and HBase, Accumulo column families need not be declared before use. Column visibility is Accumulo’s unique feature; this allows Accumulo to store data with different sensitivity to be stored on the same physical tables.
Accumulo key features
- Secure data delivery
Built with the table and cell-level security required to serve data to diverse sets of users with varying levels of permissions and security clearance, for complete and secure government applications.
- Flexibility
Store data of any type — structured, semi-structured, unstructured — without any upfront modeling. Flexible storage means you always have access to full- fidelity data for a wide range of analytics and use cases.
- Near real-time speed
Perform fast, random reads and writes to any type of data stored all within the single platform.
- Reliability
Automatic, tunable replication means multiple copies of your data is always available for access and protection from data loss. Built-in fault-tolerance means servers can fail but your system will remain available for all workloads.
- Hadoop scalable
Designed for massive scalability, so you can store unlimited amounts of data in a single platform and handle growing demands for serving data to more users and applications. As your data needs grow, you can simply add more servers to linearly scale with your business.
Common use cases
Accumulo is the ideal solution for government agencies looking to build secure, real-time applications, including:
- Sessionization
- Real-Time metrics and analytics
- Graph data
- “Internet of Things” applications
Companies using Apache Accumulo
More than 50+ companies are currently on Accumulo, most of companies using Apache Accumulo are mainly found in United States and in the Computer Software industry. Apache Accumulo is most often used by companies with >10000 employees and >1000M dollars in revenue.
Of all the customers that are using Apache Accumulo, 17% are small (<50 employees), 34% are medium-sized and 38% are large (>1000 employees).
Apache Accumulo Market Share and Competitors in Data Storage Management
With over 150 data fields per company at an average. In the Data Storage Management category, Apache Accumulo has a market share of about 0.1%. Other major and competing products in this category include:
Apache Accumulo (0.07%)
Azure Blob Storage (54.90%)
IBM Tivoli Storage Manager (7.01%)
Peak 10 (6.43%)
Looking at Apache Accumulo customers by industry, we find that Computer Software (29%), Information Technology and Services (14%), Aviation & Aerospace (5%) and Government Administration (5%) are the largest segments.
Configuring Accumulo
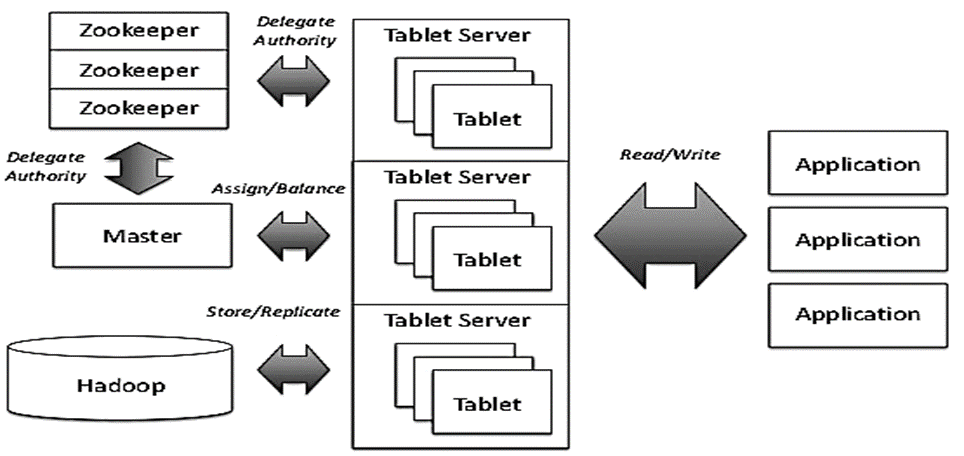
Accumulo requires running Zookeeper and HDFS instances which should be set up before configuring Accumulo.
There are four scripts in the bin directory of the tarball distribution that are used to manage Accumulo:
- accumulo – Runs Accumulo command-line tools and starts Accumulo processes
- accumulo- service – Runs individual Accumulo processes as background services
- accumulo- cluster – Manages Accumulo cluster on a single node or several nodes
- Accumulo- util – Accumulo utilities for building native libraries, running jars, etc.
The primary configuration files for Accumulo are accumulo. Properties, accumulo-env.sh, and accumulo-client. Properties which are located in the conf/ directory.
The accumulo. Properties file configures Accumulo server processes (i.e. tablet server, master, monitor, etc.). Follow these steps to set it up:
Run accumulo-util build-native to build native code. If this command fails, disable native maps by setting tserver.memory.maps.native.enabled to false.
Set instance. Volumes to HDFS location where Accumulo will store data. If your namenode is running at 192.168.1.9:8020 and you want to store data in /accumulo in HDFS, then set instance. Volumes to hdfs://192.168.1.9:8020/accumulo.
Set instance.zookeeper.host to the location of your Zookeepers
(Optional) Change instance.secret (which is used by Accumulo processes to communicate) from the default. This value should match on all servers.
The accumulo-env.sh file sets up environment variables needed by Accumulo:
Set HADOOP_HOME and ZOOKEEPER_HOME to the location of your Hadoop and Zookeeper installations.
Initialization
The initialization command will prompt for the following information.
Instance name: This is the name of the Accumulo instance and its Accumulo clients need to know it in order to connect.
Root password: Initialization sets up an initial Accumulo root user and prompts for its password. This information will be needed to later connect to Accumulo.
Run Accumulo
Run Accumulo processes using accumulo command which runs processes in foreground and will not redirect stderr/stdout. Useful for creating init.d scripts that run Accumulo.
Stopping Accumulo
When finished, use the following commands to stop Accumulo:
Stop an individual Accumulo service: accumulo-service tserver stop
Stop Accumulo cluster: accumulo-cluster stop
I’m Rajesh Kumar, a DevOps, SRE, DevSecOps, Cloud, and Platform Engineering expert passionate about sharing practical knowledge, real-world experiences, and industry best practices. I have worked at Cotocus and regularly write about technology, travel, investing, health, product reviews, and digital marketing through my various platforms.
I publish technical articles at DevOps School, travel stories at Holiday Landmark, stock market insights at Stocks Mantra, health and fitness guidance at My Medic Plus, product reviews at TrueReviewNow, and SEO and digital marketing strategies at Wizbrand.
Find Trusted Cardiac Hospitals
Compare heart hospitals by city and services — all in one place.
Explore Hospitals
nice explained