| # | Contents |
|---|---|
| 1. | What is NO PRIMARY INDEX (NOPI) Table? |
| 2. | How’s row distributed in AMP for No PRIMARY INDEX (NOPI) table? |
| 3. | How it can be determine which AMP gets which No PRIMARY INDEX (NOPI) row? |
| 4. | What will happen if we don’t define the Primary Index in the DDL statement while CREATING TABLE? |
| 5. | Why create a table with No Primary Index (NOPI)? |
| 6. | How do NOPI tables affect query performance? |
| 7. | No Primary Index (NOPI ) tables can be skewed or not? |
| 8. | How to find No Primary Index (NOPI) tables? |
| 9. | What are the Limitations No Primary Index (NOPI) Table ? |
| 10. | What are allowed on No Primary Index (NOPI) Table? |
| 11. | NO Primary Index NOPI – Loading Theory |
What is Teradata NO PRIMARY INDEX (NOPI) Table?
The rows of a Teradata NOPI table are not distributed evenly across all AMPs using the hashing algorithm, as is the case with a primary index.
Instead of defining PRIMARY INDEX we defined NO PRIMARY INDEX while creating table, than that tables formed as NO PRIMARY INDEX (NOPI).
EXAMPLE:
This is the syntax:
CREATE TABLE database_name.Table_Name
(
Customer_ID BIGINT NOT NULL
) NO PRIMARY INDEX;
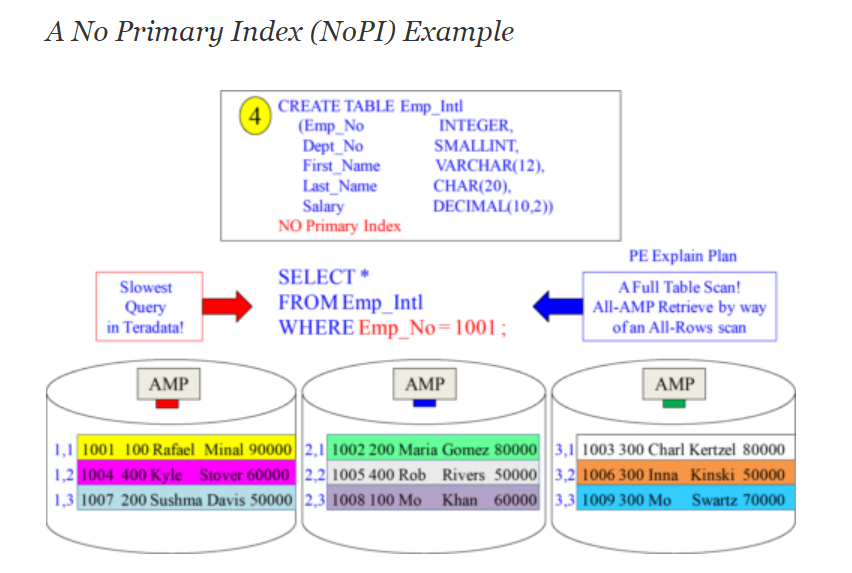
How’s row distributed in AMP for No PRIMARY INDEX (NOPI) table?
For a NOPI table, a full table scan is always necessary if there is no other index that can be used.
To identify the rows in the AMP, a ROWID is needed which we get by Hashing alogrithm.
While for PI tables, this is composed of the ROWHASH and a UNIQUENESS value, For NOPI tables, the hash bucket of the AMP and a UNIQUENESS value is used to form the ROWID.
How it can be determine which AMP gets which No PRIMARY INDEX (NOPI) row?
- A random generator is used. This is available on the AMPs as well as on the parsing engines.
- During fast load, the random generator of the AMPs distributes the rows in the round-robin procedure.
- For SQL requests, the DBQL Query Id of the request is used to generate a hash value which is used to distribute the rows.
What will happen if we don’t define the Primary Index in the DDL statement while CREATING TABLE?
CREATE TABLE database_name.Table_Name
(
Customer_ID BIGINT NOT NULL
) NO PRIMARY INDEX;
- The type of table is created depends on a system setting. If the DBC Control Field is set to “P” or “D” in the settings, a Primary Index Table is created.
- In this case, the first NOT NULL column of the table definition is used as PRIMARY INDEX (if all columns are NOT NULL, the first NULLable column is used as PRIMARY INDEX).
- If the DBC Control Field “PrimaryIndexDefault” is set to “N”, a NOPI table is created.
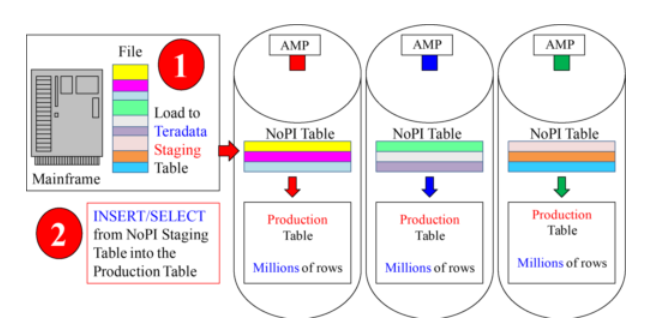
Why create a table with No Primary Index (NOPI)?
NOPI tables are designed to be staging tables. Data from a Mainframe or server can be loaded onto Teradata quickly with perfect distribution. Then, an INSERT/ SELECT can be done to move the data from the staging table (on Teradata) to the production table (also on Teradata). The data can be transformed in staging, and there are no Load Restrictions with an INSERT/ SELECT. A NoPI table usually isn’t queried, but can be!
How do Teradata NOPI tables affect query performance?
As we know no access path via hashing exists, all queries against a NOPI table require a full table scan. So to improve query performance we can create a unique secondary index (USI) or a join index.
No Primary Index (NOPI ) tables can be skewed or not?
NOPI tables can be skewed in specific cases.
If a small table is loaded with a fast load, skew can occurs because the data is not sent to the AMPs row by row All rows may be sent to the same AMP and one data block.
When executing an “INSERT…SELECT” statement, from a primary index table into a NOPI table, AMP-local copying of the rows will be applied. All rows stay on their current AMP, and if the primary index table is skewed, the NOPI table will be skewed.
Skew can be avoided by using the HASH BY RANDOM option; data blocks are distributed randomly, which results in an even distribution.
INSERT INTO Database_name.Table_name SELECT * FROM Database_name.Table_name _2020
HASH BY RANDOM;
If you want to distribute on row level to achieve even better randomness, you can use this statement:
INSERT INTO Database_name.Table_name SELECT * FROM Database_name.Table_name _2020
HASH BY RANDOM (1,100000000);
How to find Teradata No Primary Index (NOPI) tables?
The Teradata tablekind for NOPI tables is ‘O’. With the following SQL statement, we can find all NOPI tables in our system:
SELECT * FROM DBC.TABLESV WHERE TABLEKIND = ‘O’;
What are the Limitations Teradata No Primary Index (NOPI) Table ?
- No SET tables allowed
- No Identity columns allowed
- No Row-Level Partitioning allowed
- No UPDATE, MERGE INTO, or UPSERT allowed
- No Permanent Journaling possible
- No UPDATE triggers allowed
- No Hash Index allowed
- No Multiload, as its load algorithm depends on the PI
What are allowed on Teradata No Primary Index (NOPI) Table ?
- Fallback protection
- Secondary Indexes (USI and NUSI)
- Join Indexes
- CHECK and UNIQUE constraints
- Triggers
- COLLECT STATISTICS
- Global Temporary Tables
- Volatile Tables
- CLOB and BLOB Data Types
- Fastload but duplicates are not filtered
NO Primary Index NOPI – Loading Theory
- INSERT INTO Database_name.Table_name VALUES (100,’Rohan’, ‘Susan’);
The parsing engine random generator selects a random AMP and appends the row to the end of the Teradata NOPI table.
- INSERT INTO Database_name.Table_name SELECT * FROM Database_name.Table_name_2020;
If Database_name.Table_name_2020 is a PI table, the rows will not be redistributed but stay on the same AMP. Skewing is possible!
MotoShare.in is your go-to platform for adventure and exploration. Rent premium bikes for epic journeys or simple scooters for your daily errands—all with the MotoShare.in advantage of affordability and ease.
Find Trusted Cardiac Hospitals
Compare heart hospitals by city and services — all in one place.
Explore Hospitals



